 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNICE: CVPR 2023 Challenge on Zero-shot Image Captioning
Sep 11, 2023



In this report, we introduce NICE (New frontiers for zero-shot Image Captioning Evaluation) project and share the results and outcomes of 2023 challenge. This project is designed to challenge the computer vision community to develop robust image captioning models that advance the state-of-the-art both in terms of accuracy and fairness. Through the challenge, the image captioning models were tested using a new evaluation dataset that includes a large variety of visual concepts from many domains. There was no specific training data provided for the challenge, and therefore the challenge entries were required to adapt to new types of image descriptions that had not been seen during training. This report includes information on the newly proposed NICE dataset, evaluation methods, challenge results, and technical details of top-ranking entries. We expect that the outcomes of the challenge will contribute to the improvement of AI models on various vision-language tasks.
Large-Scale Bidirectional Training for Zero-Shot Image Captioning
Nov 15, 2022
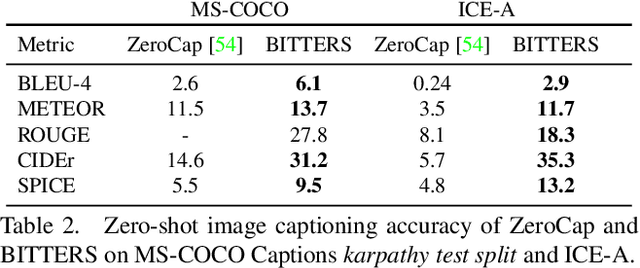
When trained on large-scale datasets, image captioning models can understand the content of images from a general domain but often fail to generate accurate, detailed captions. To improve performance, pretraining-and-finetuning has been a key strategy for image captioning. However, we find that large-scale bidirectional training between image and text enables zero-shot image captioning. In this paper, we introduce Bidirectional Image Text Training in largER Scale, BITTERS, an efficient training and inference framework for zero-shot image captioning. We also propose a new evaluation benchmark which comprises of high quality datasets and an extensive set of metrics to properly evaluate zero-shot captioning accuracy and societal bias. We additionally provide an efficient finetuning approach for keyword extraction. We show that careful selection of large-scale training set and model architecture is the key to achieving zero-shot image captioning.
Investigating Class-level Difficulty Factors in Multi-label Classification Problems
May 01, 2020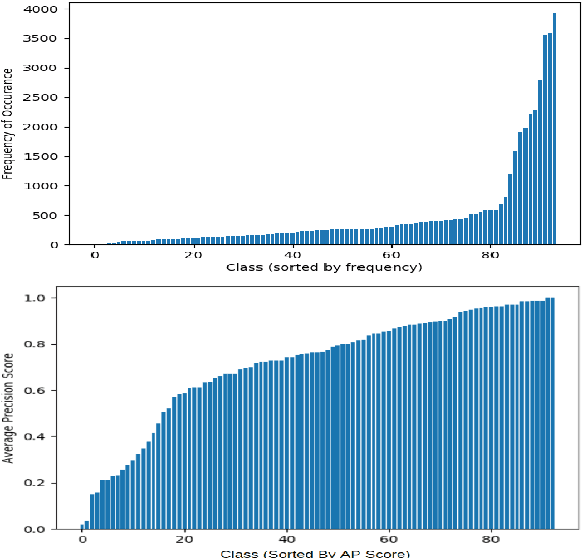

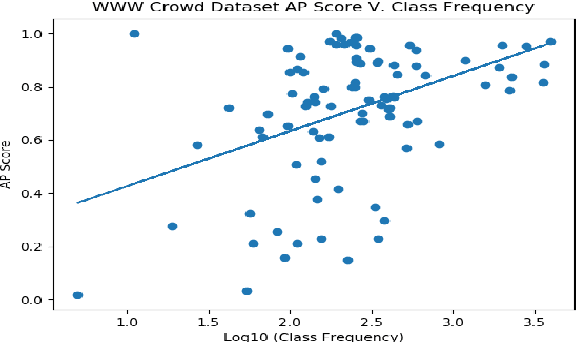

This work investigates the use of class-level difficulty factors in multi-label classification problems for the first time. Four class-level difficulty factors are proposed: frequency, visual variation, semantic abstraction, and class co-occurrence. Once computed for a given multi-label classification dataset, these difficulty factors are shown to have several potential applications including the prediction of class-level performance across datasets and the improvement of predictive performance through difficulty weighted optimisation. Significant improvements to mAP and AUC performance are observed for two challenging multi-label datasets (WWW Crowd and Visual Genome) with the inclusion of difficulty weighted optimisation. The proposed technique does not require any additional computational complexity during training or inference and can be extended over time with inclusion of other class-level difficulty factors.
People, Penguins and Petri Dishes: Adapting Object Counting Models To New Visual Domains And Object Types Without Forgetting
Nov 15, 2017

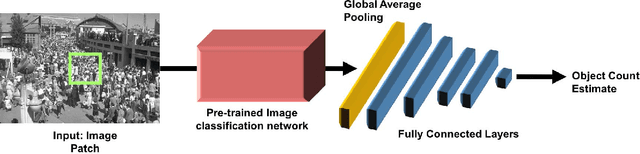
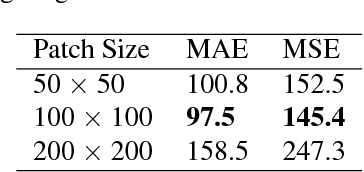
In this paper we propose a technique to adapt a convolutional neural network (CNN) based object counter to additional visual domains and object types while still preserving the original counting function. Domain-specific normalisation and scaling operators are trained to allow the model to adjust to the statistical distributions of the various visual domains. The developed adaptation technique is used to produce a singular patch-based counting regressor capable of counting various object types including people, vehicles, cell nuclei and wildlife. As part of this study a challenging new cell counting dataset in the context of tissue culture and patient diagnosis is constructed. This new collection, referred to as the Dublin Cell Counting (DCC) dataset, is the first of its kind to be made available to the wider computer vision community. State-of-the-art object counting performance is achieved in both the Shanghaitech (parts A and B) and Penguins datasets while competitive performance is observed on the TRANCOS and Modified Bone Marrow (MBM) datasets, all using a shared counting model.
ResnetCrowd: A Residual Deep Learning Architecture for Crowd Counting, Violent Behaviour Detection and Crowd Density Level Classification
May 30, 2017


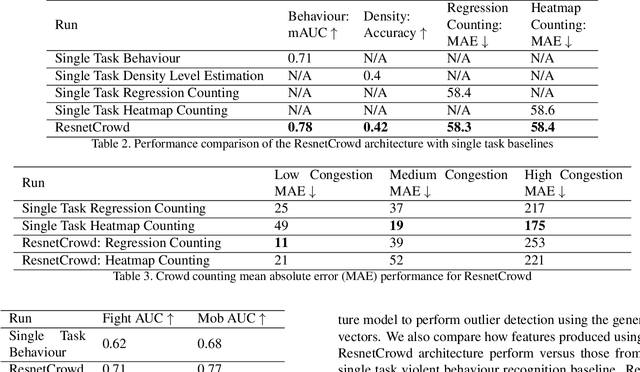
In this paper we propose ResnetCrowd, a deep residual architecture for simultaneous crowd counting, violent behaviour detection and crowd density level classification. To train and evaluate the proposed multi-objective technique, a new 100 image dataset referred to as Multi Task Crowd is constructed. This new dataset is the first computer vision dataset fully annotated for crowd counting, violent behaviour detection and density level classification. Our experiments show that a multi-task approach boosts individual task performance for all tasks and most notably for violent behaviour detection which receives a 9\% boost in ROC curve AUC (Area under the curve). The trained ResnetCrowd model is also evaluated on several additional benchmarks highlighting the superior generalisation of crowd analysis models trained for multiple objectives.
Fully Convolutional Crowd Counting On Highly Congested Scenes
Jan 17, 2017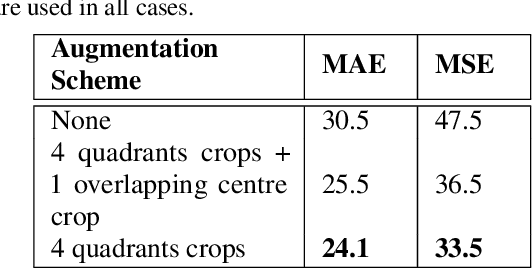



In this paper we advance the state-of-the-art for crowd counting in high density scenes by further exploring the idea of a fully convolutional crowd counting model introduced by (Zhang et al., 2016). Producing an accurate and robust crowd count estimator using computer vision techniques has attracted significant research interest in recent years. Applications for crowd counting systems exist in many diverse areas including city planning, retail, and of course general public safety. Developing a highly generalised counting model that can be deployed in any surveillance scenario with any camera perspective is the key objective for research in this area. Techniques developed in the past have generally performed poorly in highly congested scenes with several thousands of people in frame (Rodriguez et al., 2011). Our approach, influenced by the work of (Zhang et al., 2016), consists of the following contributions: (1) A training set augmentation scheme that minimises redundancy among training samples to improve model generalisation and overall counting performance; (2) a deep, single column, fully convolutional network (FCN) architecture; (3) a multi-scale averaging step during inference. The developed technique can analyse images of any resolution or aspect ratio and achieves state-of-the-art counting performance on the Shanghaitech Part B and UCF CC 50 datasets as well as competitive performance on Shanghaitech Part A.