 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Class-level Difficulty Factors in Multi-label Classification Problems
May 01, 2020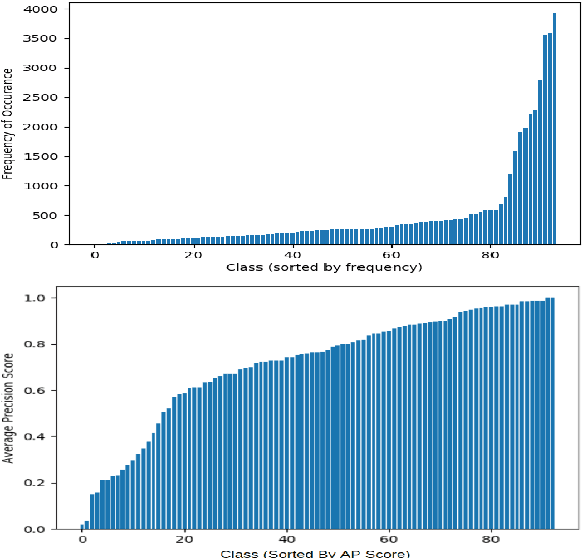

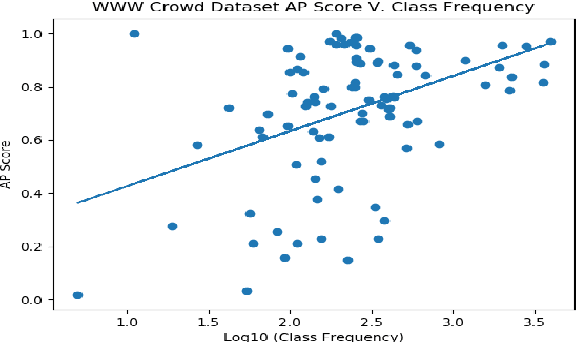

This work investigates the use of class-level difficulty factors in multi-label classification problems for the first time. Four class-level difficulty factors are proposed: frequency, visual variation, semantic abstraction, and class co-occurrence. Once computed for a given multi-label classification dataset, these difficulty factors are shown to have several potential applications including the prediction of class-level performance across datasets and the improvement of predictive performance through difficulty weighted optimisation. Significant improvements to mAP and AUC performance are observed for two challenging multi-label datasets (WWW Crowd and Visual Genome) with the inclusion of difficulty weighted optimisation. The proposed technique does not require any additional computational complexity during training or inference and can be extended over time with inclusion of other class-level difficulty factors.