 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADFF: Attention Based Deep Feature Fusion Approach for Music Emotion Recognition
Apr 12, 2022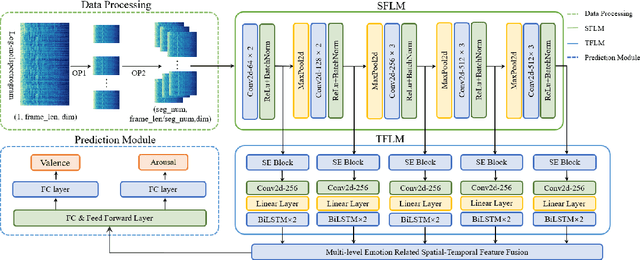
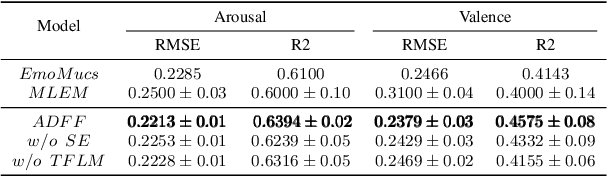
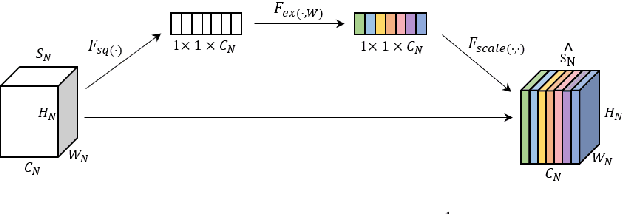

Music emotion recognition (MER), a sub-task of music information retrieval (MIR), has developed rapidly in recent years. However, the learning of affect-salient features remains a challenge. In this paper, we propose an end-to-end attention-based deep feature fusion (ADFF) approach for MER. Only taking log Mel-spectrogram as input, this method uses adapted VGGNet as spatial feature learning module (SFLM) to obtain spatial features across different levels. Then, these features are fed into squeeze-and-excitation (SE) attention-based temporal feature learning module (TFLM) to get multi-level emotion-related spatial-temporal features (ESTFs), which can discriminate emotions well in the final emotion space. In addition, a novel data processing is devised to cut the single-channel input into multi-channel to improve calculative efficiency while ensuring the quality of MER. Experiments show that our proposed method achieves 10.43% and 4.82% relative improvement of valence and arousal respectively on the R2 score compared to the state-of-the-art model, meanwhile, performs better on datasets with distinct scales and in multi-task learning.
Bridge-Prompt: Towards Ordinal Action Understanding in Instructional Videos
Mar 26, 2022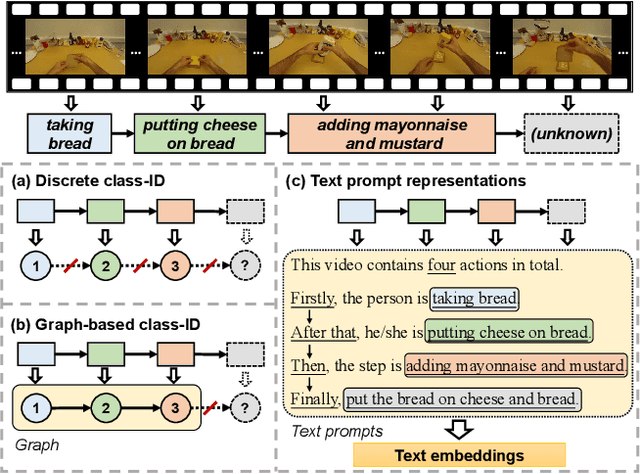
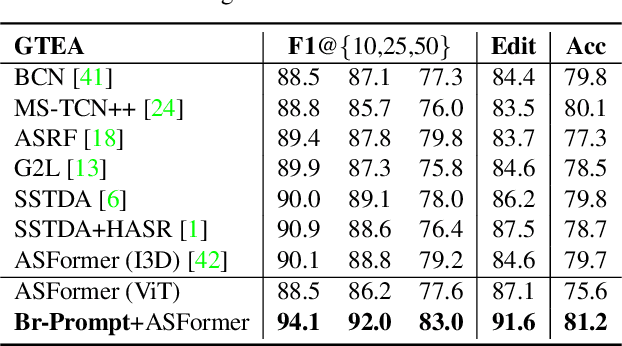
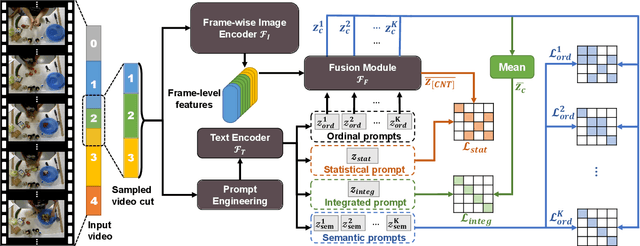
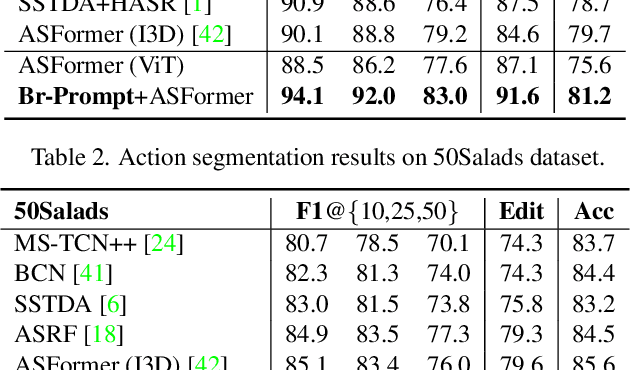
Action recognition models have shown a promising capability to classify human actions in short video clips. In a real scenario, multiple correlated human actions commonly occur in particular orders, forming semantically meaningful human activities. Conventional action recognition approaches focus on analyzing single actions. However, they fail to fully reason about the contextual relations between adjacent actions, which provide potential temporal logic for understanding long videos. In this paper, we propose a prompt-based framework, Bridge-Prompt (Br-Prompt), to model the semantics across adjacent actions, so that it simultaneously exploits both out-of-context and contextual information from a series of ordinal actions in instructional videos. More specifically, we reformulate the individual action labels as integrated text prompts for supervision, which bridge the gap between individual action semantics. The generated text prompts are paired with corresponding video clips, and together co-train the text encoder and the video encoder via a contrastive approach. The learned vision encoder has a stronger capability for ordinal-action-related downstream tasks, e.g. action segmentation and human activity recognition. We evaluate the performances of our approach on several video datasets: Georgia Tech Egocentric Activities (GTEA), 50Salads, and the Breakfast dataset. Br-Prompt achieves state-of-the-art on multiple benchmarks. Code is available at https://github.com/ttlmh/Bridge-Prompt
Investigating Class-level Difficulty Factors in Multi-label Classification Problems
May 01, 2020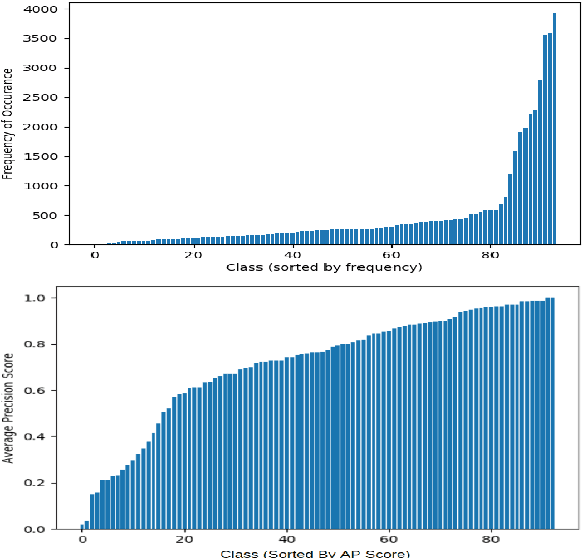

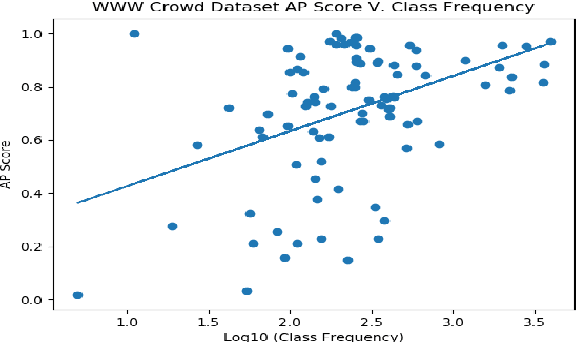

This work investigates the use of class-level difficulty factors in multi-label classification problems for the first time. Four class-level difficulty factors are proposed: frequency, visual variation, semantic abstraction, and class co-occurrence. Once computed for a given multi-label classification dataset, these difficulty factors are shown to have several potential applications including the prediction of class-level performance across datasets and the improvement of predictive performance through difficulty weighted optimisation. Significant improvements to mAP and AUC performance are observed for two challenging multi-label datasets (WWW Crowd and Visual Genome) with the inclusion of difficulty weighted optimisation. The proposed technique does not require any additional computational complexity during training or inference and can be extended over time with inclusion of other class-level difficulty factors.
Open Set Adversarial Examples
Sep 07, 2018


Adversarial examples in recent works target at closed set recognition systems, in which the training and testing classes are identical. In real-world scenarios, however, the testing classes may have limited, if any, overlap with the training classes, a problem named open set recognition. To our knowledge, the community does not have a specific design of adversarial examples targeting at this practical setting. Arguably, the new setting compromises traditional closed set attack methods in two aspects. First, closed set attack methods are based on classification and target at classification as well, but the open set problem suggests a different task, \emph{i.e.,} retrieval. It is undesirable that the generation mechanism of closed set recognition is different from the aim of open set recognition. Second, given that the query image is usually of an unseen class, predicting its category from the training classes is not reasonable, which leads to an inferior adversarial gradient. In this work, we view open set recognition as a retrieval task and propose a new approach, Opposite-Direction Feature Attack (ODFA), to generate adversarial examples / queries. When using an attacked example as query, we aim that the true matches be ranked as low as possible. In addressing the two limitations of closed set attack methods, ODFA directly works on the features for retrieval. The idea is to push away the feature of the adversarial query in the opposite direction of the original feature. Albeit simple, ODFA leads to a larger drop in Recall@K and mAP than the close-set attack methods on two open set recognition datasets, \emph{i.e.,} Market-1501 and CUB-200-2011. We also demonstrate that the attack performance of ODFA is not evidently superior to the state-of-the-art methods under closed set recognition (Cifar-10), suggesting its specificity for open set problems.