 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff-V2M: A Hierarchical Conditional Diffusion Model with Explicit Rhythmic Modeling for Video-to-Music Generation
Nov 12, 2025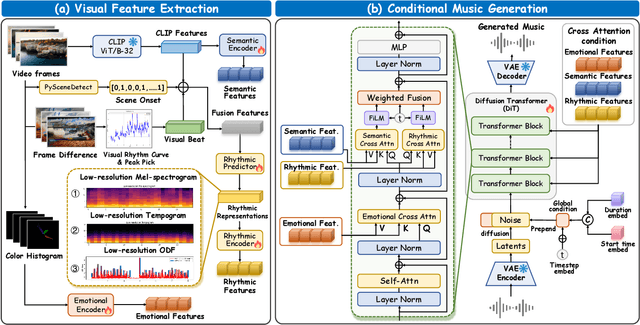
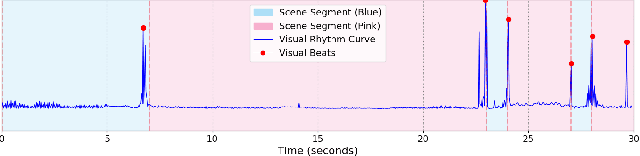
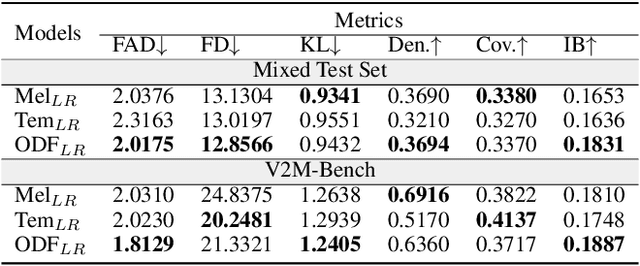
Video-to-music (V2M) generation aims to create music that aligns with visual content. However, two main challenges persist in existing methods: (1) the lack of explicit rhythm modeling hinders audiovisual temporal alignments; (2) effectively integrating various visual features to condition music generation remains non-trivial. To address these issues, we propose Diff-V2M, a general V2M framework based on a hierarchical conditional diffusion model, comprising two core components: visual feature extraction and conditional music generation. For rhythm modeling, we begin by evaluating several rhythmic representations, including low-resolution mel-spectrograms, tempograms, and onset detection functions (ODF), and devise a rhythmic predictor to infer them directly from videos. To ensure contextual and affective coherence, we also extract semantic and emotional features. All features are incorporated into the generator via a hierarchical cross-attention mechanism, where emotional features shape the affective tone via the first layer, while semantic and rhythmic features are fused in the second cross-attention layer. To enhance feature integration, we introduce timestep-aware fusion strategies, including feature-wise linear modulation (FiLM) and weighted fusion, allowing the model to adaptively balance semantic and rhythmic cues throughout the diffusion process. Extensive experiments identify low-resolution ODF as a more effective signal for modeling musical rhythm and demonstrate that Diff-V2M outperforms existing models on both in-domain and out-of-domain datasets, achieving state-of-the-art performance in terms of objective metrics and subjective comparisons. Demo and code are available at https://Tayjsl97.github.io/Diff-V2M-Demo/.
A Survey on Music Generation from Single-Modal, Cross-Modal, and Multi-Modal Perspectives: Data, Methods, and Challenges
Apr 01, 2025Multi-modal music generation, using multiple modalities like images, video, and text alongside musical scores and audio as guidance, is an emerging research area with broad applications. This paper reviews this field, categorizing music generation systems from the perspective of modalities. It covers modality representation, multi-modal data alignment, and their utilization to guide music generation. We also discuss current datasets and evaluation methods. Key challenges in this area include effective multi-modal integration, large-scale comprehensive datasets, and systematic evaluation methods. Finally, we provide an outlook on future research directions focusing on multi-modal fusion, alignment, data, and evaluation.
A Comprehensive Survey on Generative AI for Video-to-Music Generation
Feb 18, 2025The burgeoning growth of video-to-music generation can be attributed to the ascendancy of multimodal generative models. However, there is a lack of literature that comprehensively combs through the work in this field. To fill this gap, this paper presents a comprehensive review of video-to-music generation using deep generative AI techniques, focusing on three key components: visual feature extraction, music generation frameworks, and conditioning mechanisms. We categorize existing approaches based on their designs for each component, clarifying the roles of different strategies. Preceding this, we provide a fine-grained classification of video and music modalities, illustrating how different categories influence the design of components within the generation pipelines. Furthermore, we summarize available multimodal datasets and evaluation metrics while highlighting ongoing challenges in the field.
MusER: Musical Element-Based Regularization for Generating Symbolic Music with Emotion
Jan 02, 2024


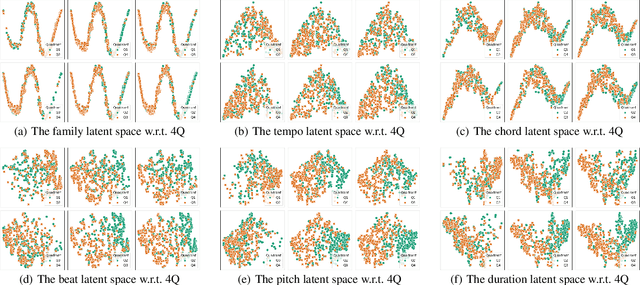
Generating music with emotion is an important task in automatic music generation, in which emotion is evoked through a variety of musical elements (such as pitch and duration) that change over time and collaborate with each other. However, prior research on deep learning-based emotional music generation has rarely explored the contribution of different musical elements to emotions, let alone the deliberate manipulation of these elements to alter the emotion of music, which is not conducive to fine-grained element-level control over emotions. To address this gap, we present a novel approach employing musical element-based regularization in the latent space to disentangle distinct elements, investigate their roles in distinguishing emotions, and further manipulate elements to alter musical emotions. Specifically, we propose a novel VQ-VAE-based model named MusER. MusER incorporates a regularization loss to enforce the correspondence between the musical element sequences and the specific dimensions of latent variable sequences, providing a new solution for disentangling discrete sequences. Taking advantage of the disentangled latent vectors, a two-level decoding strategy that includes multiple decoders attending to latent vectors with different semantics is devised to better predict the elements. By visualizing latent space, we conclude that MusER yields a disentangled and interpretable latent space and gain insights into the contribution of distinct elements to the emotional dimensions (i.e., arousal and valence). Experimental results demonstrate that MusER outperforms the state-of-the-art models for generating emotional music in both objective and subjective evaluation. Besides, we rearrange music through element transfer and attempt to alter the emotion of music by transferring emotion-distinguishable elements.
Emotion-Conditioned Melody Harmonization with Hierarchical Variational Autoencoder
Jun 08, 2023
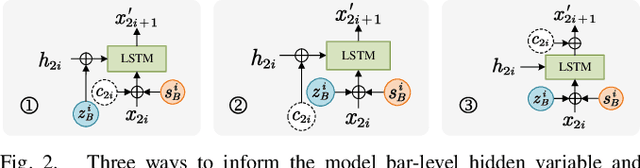


Existing melody harmonization models have made great progress in improving the quality of generated harmonies, but most of them ignored the emotions beneath the music. Meanwhile, the variability of harmonies generated by previous methods is insufficient. To solve these problems, we propose a novel LSTM-based Hierarchical Variational Auto-Encoder (LHVAE) to investigate the influence of emotional conditions on melody harmonization, while improving the quality of generated harmonies and capturing the abundant variability of chord progressions. Specifically, LHVAE incorporates latent variables and emotional conditions at different levels (piece- and bar-level) to model the global and local music properties. Additionally, we introduce an attention-based melody context vector at each step to better learn the correspondence between melodies and harmonies. Experimental results of the objective evaluation show that our proposed model outperforms other LSTM-based models. Through subjective evaluation, we conclude that only altering the chords hardly changes the overall emotion of the music. The qualitative analysis demonstrates the ability of our model to generate variable harmonies.
ADFF: Attention Based Deep Feature Fusion Approach for Music Emotion Recognition
Apr 12, 2022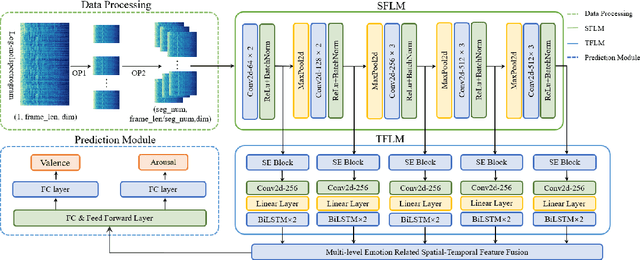
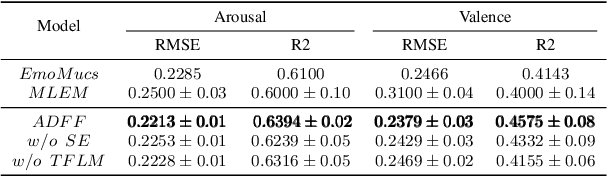
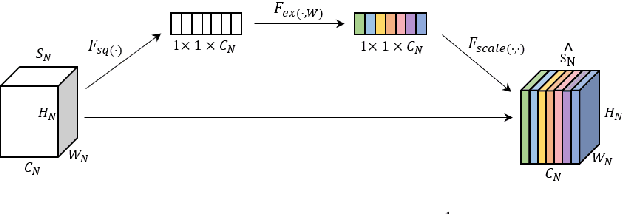

Music emotion recognition (MER), a sub-task of music information retrieval (MIR), has developed rapidly in recent years. However, the learning of affect-salient features remains a challenge. In this paper, we propose an end-to-end attention-based deep feature fusion (ADFF) approach for MER. Only taking log Mel-spectrogram as input, this method uses adapted VGGNet as spatial feature learning module (SFLM) to obtain spatial features across different levels. Then, these features are fed into squeeze-and-excitation (SE) attention-based temporal feature learning module (TFLM) to get multi-level emotion-related spatial-temporal features (ESTFs), which can discriminate emotions well in the final emotion space. In addition, a novel data processing is devised to cut the single-channel input into multi-channel to improve calculative efficiency while ensuring the quality of MER. Experiments show that our proposed method achieves 10.43% and 4.82% relative improvement of valence and arousal respectively on the R2 score compared to the state-of-the-art model, meanwhile, performs better on datasets with distinct scales and in multi-task learning.
A Comprehensive Survey on Deep Music Generation: Multi-level Representations, Algorithms, Evaluations, and Future Directions
Nov 13, 2020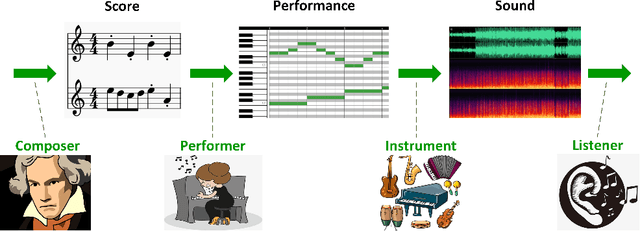



The utilization of deep learning techniques in generating various contents (such as image, text, etc.) has become a trend. Especially music, the topic of this paper, has attracted widespread attention of countless researchers.The whole process of producing music can be divided into three stages, corresponding to the three levels of music generation: score generation produces scores, performance generation adds performance characteristics to the scores, and audio generation converts scores with performance characteristics into audio by assigning timbre or generates music in audio format directly. Previous surveys have explored the network models employed in the field of automatic music generation. However, the development history, the model evolution, as well as the pros and cons of same music generation task have not been clearly illustrated. This paper attempts to provide an overview of various composition tasks under different music generation levels, covering most of the currently popular music generation tasks using deep learning. In addition, we summarize the datasets suitable for diverse tasks, discuss the music representations, the evaluation methods as well as the challenges under different levels, and finally point out several future directions.
MG-VAE: Deep Chinese Folk Songs Generation with Specific Regional Style
Sep 29, 2019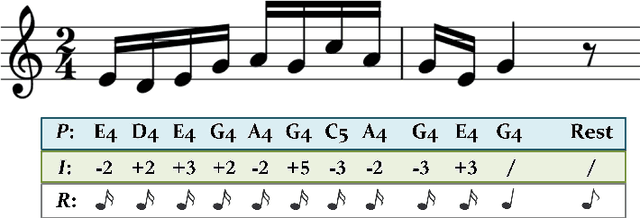
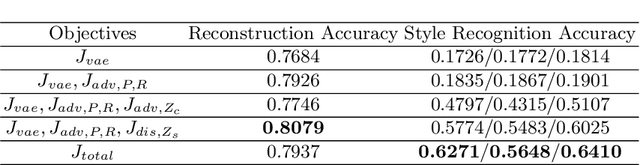
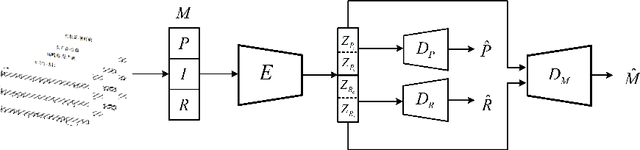
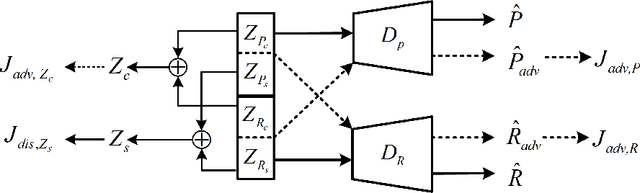
Regional style in Chinese folk songs is a rich treasure that can be used for ethnic music creation and folk culture research. In this paper, we propose MG-VAE, a music generative model based on VAE (Variational Auto-Encoder) that is capable of capturing specific music style and generating novel tunes for Chinese folk songs (Min Ge) in a manipulatable way. Specifically, we disentangle the latent space of VAE into four parts in an adversarial training way to control the information of pitch and rhythm sequence, as well as of music style and content. In detail, two classifiers are used to separate style and content latent space, and temporal supervision is utilized to disentangle the pitch and rhythm sequence. The experimental results show that the disentanglement is successful and our model is able to create novel folk songs with controllable regional styles. To our best knowledge, this is the first study on applying deep generative model and adversarial training for Chinese music generation.