 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff-V2M: A Hierarchical Conditional Diffusion Model with Explicit Rhythmic Modeling for Video-to-Music Generation
Nov 12, 2025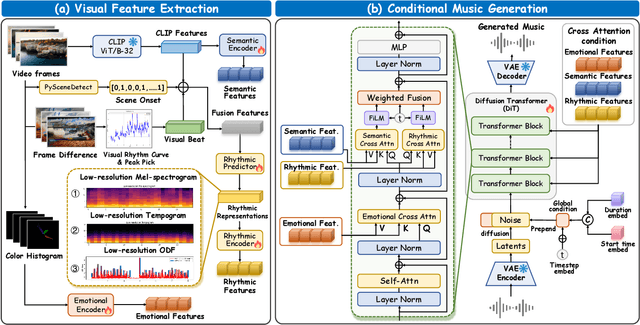
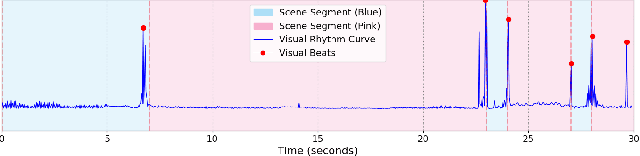
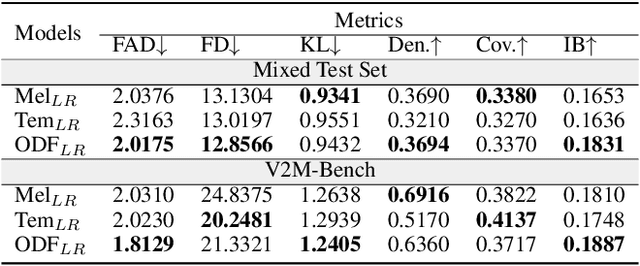
Video-to-music (V2M) generation aims to create music that aligns with visual content. However, two main challenges persist in existing methods: (1) the lack of explicit rhythm modeling hinders audiovisual temporal alignments; (2) effectively integrating various visual features to condition music generation remains non-trivial. To address these issues, we propose Diff-V2M, a general V2M framework based on a hierarchical conditional diffusion model, comprising two core components: visual feature extraction and conditional music generation. For rhythm modeling, we begin by evaluating several rhythmic representations, including low-resolution mel-spectrograms, tempograms, and onset detection functions (ODF), and devise a rhythmic predictor to infer them directly from videos. To ensure contextual and affective coherence, we also extract semantic and emotional features. All features are incorporated into the generator via a hierarchical cross-attention mechanism, where emotional features shape the affective tone via the first layer, while semantic and rhythmic features are fused in the second cross-attention layer. To enhance feature integration, we introduce timestep-aware fusion strategies, including feature-wise linear modulation (FiLM) and weighted fusion, allowing the model to adaptively balance semantic and rhythmic cues throughout the diffusion process. Extensive experiments identify low-resolution ODF as a more effective signal for modeling musical rhythm and demonstrate that Diff-V2M outperforms existing models on both in-domain and out-of-domain datasets, achieving state-of-the-art performance in terms of objective metrics and subjective comparisons. Demo and code are available at https://Tayjsl97.github.io/Diff-V2M-Demo/.
A Survey on Music Generation from Single-Modal, Cross-Modal, and Multi-Modal Perspectives: Data, Methods, and Challenges
Apr 01, 2025Multi-modal music generation, using multiple modalities like images, video, and text alongside musical scores and audio as guidance, is an emerging research area with broad applications. This paper reviews this field, categorizing music generation systems from the perspective of modalities. It covers modality representation, multi-modal data alignment, and their utilization to guide music generation. We also discuss current datasets and evaluation methods. Key challenges in this area include effective multi-modal integration, large-scale comprehensive datasets, and systematic evaluation methods. Finally, we provide an outlook on future research directions focusing on multi-modal fusion, alignment, data, and evaluation.
A Comprehensive Survey on Generative AI for Video-to-Music Generation
Feb 18, 2025The burgeoning growth of video-to-music generation can be attributed to the ascendancy of multimodal generative models. However, there is a lack of literature that comprehensively combs through the work in this field. To fill this gap, this paper presents a comprehensive review of video-to-music generation using deep generative AI techniques, focusing on three key components: visual feature extraction, music generation frameworks, and conditioning mechanisms. We categorize existing approaches based on their designs for each component, clarifying the roles of different strategies. Preceding this, we provide a fine-grained classification of video and music modalities, illustrating how different categories influence the design of components within the generation pipelines. Furthermore, we summarize available multimodal datasets and evaluation metrics while highlighting ongoing challenges in the field.
SongGLM: Lyric-to-Melody Generation with 2D Alignment Encoding and Multi-Task Pre-Training
Dec 24, 2024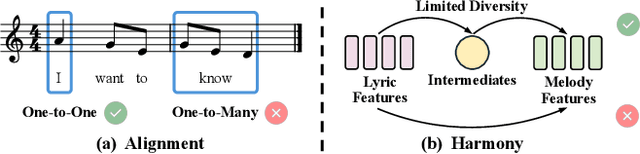
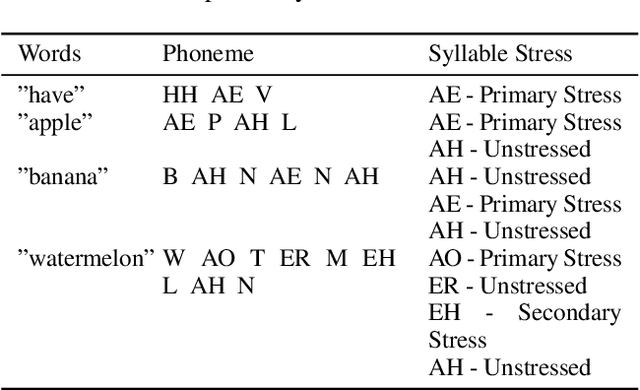
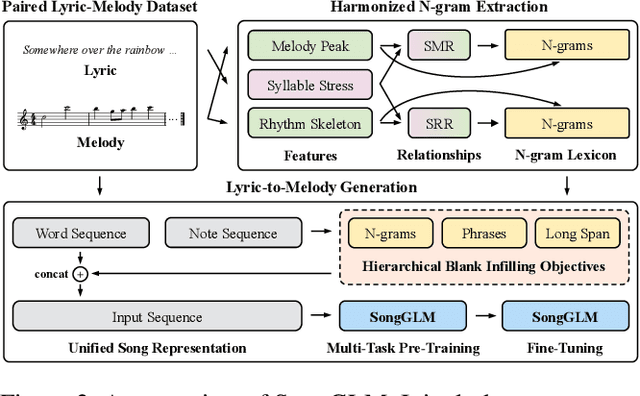

Lyric-to-melody generation aims to automatically create melodies based on given lyrics, requiring the capture of complex and subtle correlations between them. However, previous works usually suffer from two main challenges: 1) lyric-melody alignment modeling, which is often simplified to one-syllable/word-to-one-note alignment, while others have the problem of low alignment accuracy; 2) lyric-melody harmony modeling, which usually relies heavily on intermediates or strict rules, limiting model's capabilities and generative diversity. In this paper, we propose SongGLM, a lyric-to-melody generation system that leverages 2D alignment encoding and multi-task pre-training based on the General Language Model (GLM) to guarantee the alignment and harmony between lyrics and melodies. Specifically, 1) we introduce a unified symbolic song representation for lyrics and melodies with word-level and phrase-level (2D) alignment encoding to capture the lyric-melody alignment; 2) we design a multi-task pre-training framework with hierarchical blank infilling objectives (n-gram, phrase, and long span), and incorporate lyric-melody relationships into the extraction of harmonized n-grams to ensure the lyric-melody harmony. We also construct a large-scale lyric-melody paired dataset comprising over 200,000 English song pieces for pre-training and fine-tuning. The objective and subjective results indicate that SongGLM can generate melodies from lyrics with significant improvements in both alignment and harmony, outperforming all the previous baseline methods.
WuYun: Exploring hierarchical skeleton-guided melody generation using knowledge-enhanced deep learning
Jan 11, 2023Although deep learning has revolutionized music generation, existing methods for structured melody generation follow an end-to-end left-to-right note-by-note generative paradigm and treat each note equally. Here, we present WuYun, a knowledge-enhanced deep learning architecture for improving the structure of generated melodies, which first generates the most structurally important notes to construct a melodic skeleton and subsequently infills it with dynamically decorative notes into a full-fledged melody. Specifically, we use music domain knowledge to extract melodic skeletons and employ sequence learning to reconstruct them, which serve as additional knowledge to provide auxiliary guidance for the melody generation process. We demonstrate that WuYun can generate melodies with better long-term structure and musicality and outperforms other state-of-the-art methods by 0.51 on average on all subjective evaluation metrics. Our study provides a multidisciplinary lens to design melodic hierarchical structures and bridge the gap between data-driven and knowledge-based approaches for numerous music generation tasks.
ReLyMe: Improving Lyric-to-Melody Generation by Incorporating Lyric-Melody Relationships
Jul 12, 2022

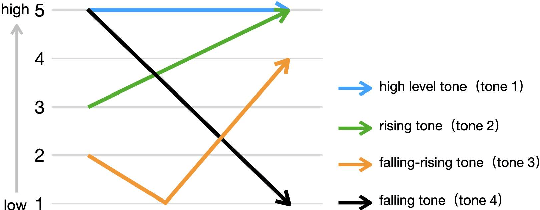
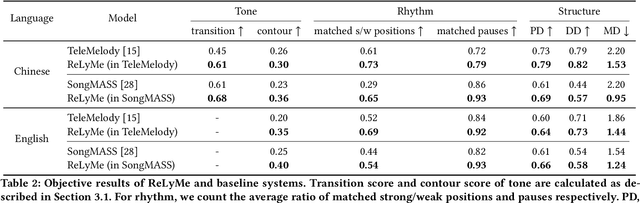
Lyric-to-melody generation, which generates melody according to given lyrics, is one of the most important automatic music composition tasks. With the rapid development of deep learning, previous works address this task with end-to-end neural network models. However, deep learning models cannot well capture the strict but subtle relationships between lyrics and melodies, which compromises the harmony between lyrics and generated melodies. In this paper, we propose ReLyMe, a method that incorporates Relationships between Lyrics and Melodies from music theory to ensure the harmony between lyrics and melodies. Specifically, we first introduce several principles that lyrics and melodies should follow in terms of tone, rhythm, and structure relationships. These principles are then integrated into neural network lyric-to-melody models by adding corresponding constraints during the decoding process to improve the harmony between lyrics and melodies. We use a series of objective and subjective metrics to evaluate the generated melodies. Experiments on both English and Chinese song datasets show the effectiveness of ReLyMe, demonstrating the superiority of incorporating lyric-melody relationships from the music domain into neural lyric-to-melody generation.
TeleMelody: Lyric-to-Melody Generation with a Template-Based Two-Stage Method
Sep 20, 2021
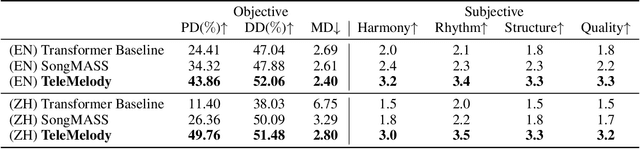
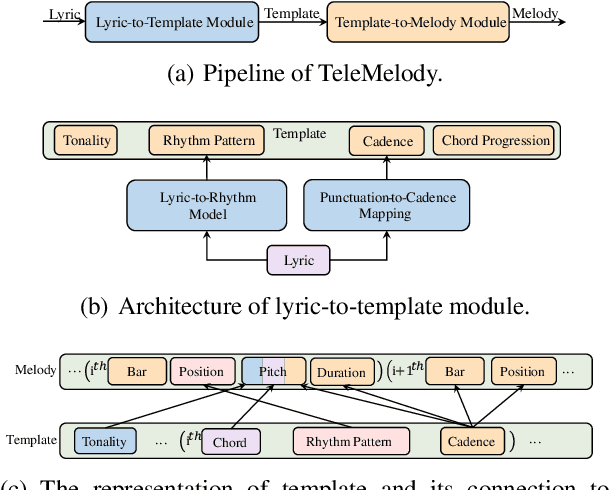
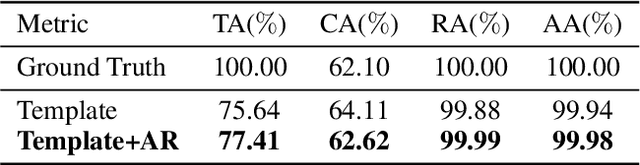
Lyric-to-melody generation is an important task in automatic songwriting. Previous lyric-to-melody generation systems usually adopt end-to-end models that directly generate melodies from lyrics, which suffer from several issues: 1) lack of paired lyric-melody training data; 2) lack of control on generated melodies. In this paper, we develop TeleMelody, a two-stage lyric-to-melody generation system with music template (e.g., tonality, chord progression, rhythm pattern, and cadence) to bridge the gap between lyrics and melodies (i.e., the system consists of a lyric-to-template module and a template-to-melody module). TeleMelody has two advantages. First, it is data efficient. The template-to-melody module is trained in a self-supervised way (i.e., the source template is extracted from the target melody) that does not need any lyric-melody paired data. The lyric-to-template module is made up of some rules and a lyric-to-rhythm model, which is trained with paired lyric-rhythm data that is easier to obtain than paired lyric-melody data. Second, it is controllable. The design of template ensures that the generated melodies can be controlled by adjusting the musical elements in template. Both subjective and objective experimental evaluations demonstrate that TeleMelody generates melodies with higher quality, better controllability, and less requirement on paired lyric-melody data than previous generation systems.