 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSong Aesthetics Evaluation with Multi-Stem Attention and Hierarchical Uncertainty Modeling
Jan 18, 2026Music generative artificial intelligence (AI) is rapidly expanding music content, necessitating automated song aesthetics evaluation. However, existing studies largely focus on speech, audio or singing quality, leaving song aesthetics underexplored. Moreover, conventional approaches often predict a precise Mean Opinion Score (MOS) value directly, which struggles to capture the nuances of human perception in song aesthetics evaluation. This paper proposes a song-oriented aesthetics evaluation framework, featuring two novel modules: 1) Multi-Stem Attention Fusion (MSAF) builds bidirectional cross-attention between mixture-vocal and mixture-accompaniment pairs, fusing them to capture complex musical features; 2) Hierarchical Granularity-Aware Interval Aggregation (HiGIA) learns multi-granularity score probability distributions, aggregates them into a score interval, and applies a regression within the interval to produce the final score. We evaluated on two datasets of full-length songs: SongEval dataset (AI-generated) and an internal aesthetics dataset (human-created), and compared with two state-of-the-art (SOTA) models. Results show that the proposed method achieves stronger performance for multi-dimensional song aesthetics evaluation.
SongGLM: Lyric-to-Melody Generation with 2D Alignment Encoding and Multi-Task Pre-Training
Dec 24, 2024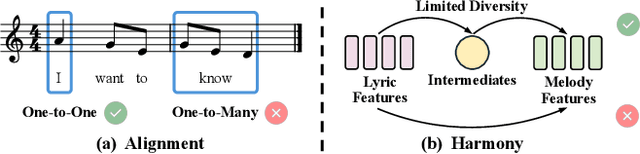
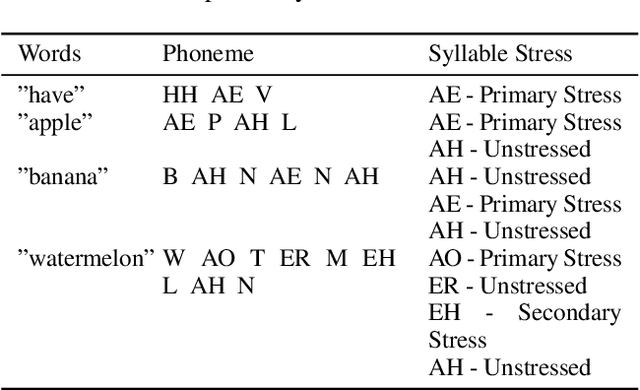
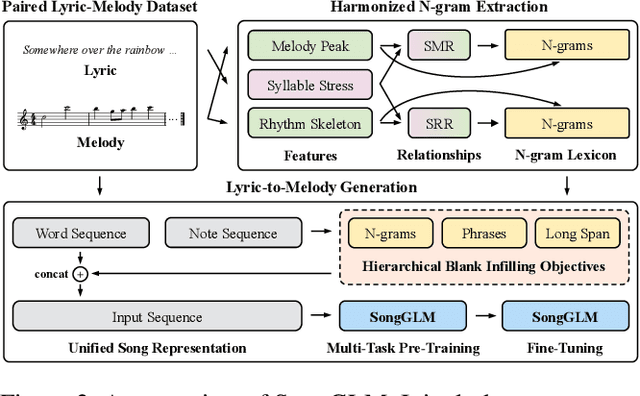

Lyric-to-melody generation aims to automatically create melodies based on given lyrics, requiring the capture of complex and subtle correlations between them. However, previous works usually suffer from two main challenges: 1) lyric-melody alignment modeling, which is often simplified to one-syllable/word-to-one-note alignment, while others have the problem of low alignment accuracy; 2) lyric-melody harmony modeling, which usually relies heavily on intermediates or strict rules, limiting model's capabilities and generative diversity. In this paper, we propose SongGLM, a lyric-to-melody generation system that leverages 2D alignment encoding and multi-task pre-training based on the General Language Model (GLM) to guarantee the alignment and harmony between lyrics and melodies. Specifically, 1) we introduce a unified symbolic song representation for lyrics and melodies with word-level and phrase-level (2D) alignment encoding to capture the lyric-melody alignment; 2) we design a multi-task pre-training framework with hierarchical blank infilling objectives (n-gram, phrase, and long span), and incorporate lyric-melody relationships into the extraction of harmonized n-grams to ensure the lyric-melody harmony. We also construct a large-scale lyric-melody paired dataset comprising over 200,000 English song pieces for pre-training and fine-tuning. The objective and subjective results indicate that SongGLM can generate melodies from lyrics with significant improvements in both alignment and harmony, outperforming all the previous baseline methods.
MelodyGLM: Multi-task Pre-training for Symbolic Melody Generation
Sep 20, 2023



Pre-trained language models have achieved impressive results in various music understanding and generation tasks. However, existing pre-training methods for symbolic melody generation struggle to capture multi-scale, multi-dimensional structural information in note sequences, due to the domain knowledge discrepancy between text and music. Moreover, the lack of available large-scale symbolic melody datasets limits the pre-training improvement. In this paper, we propose MelodyGLM, a multi-task pre-training framework for generating melodies with long-term structure. We design the melodic n-gram and long span sampling strategies to create local and global blank infilling tasks for modeling the local and global structures in melodies. Specifically, we incorporate pitch n-grams, rhythm n-grams, and their combined n-grams into the melodic n-gram blank infilling tasks for modeling the multi-dimensional structures in melodies. To this end, we have constructed a large-scale symbolic melody dataset, MelodyNet, containing more than 0.4 million melody pieces. MelodyNet is utilized for large-scale pre-training and domain-specific n-gram lexicon construction. Both subjective and objective evaluations demonstrate that MelodyGLM surpasses the standard and previous pre-training methods. In particular, subjective evaluations show that, on the melody continuation task, MelodyGLM gains average improvements of 0.82, 0.87, 0.78, and 0.94 in consistency, rhythmicity, structure, and overall quality, respectively. Notably, MelodyGLM nearly matches the quality of human-composed melodies on the melody inpainting task.
SongDriver2: Real-time Emotion-based Music Arrangement with Soft Transition
May 14, 2023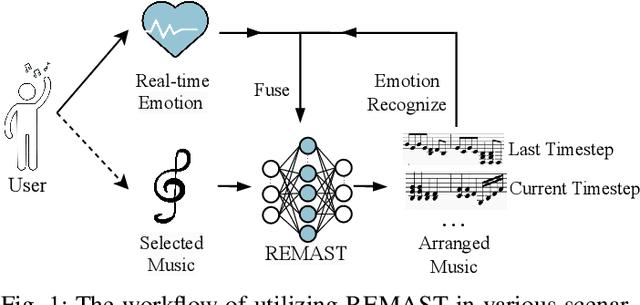
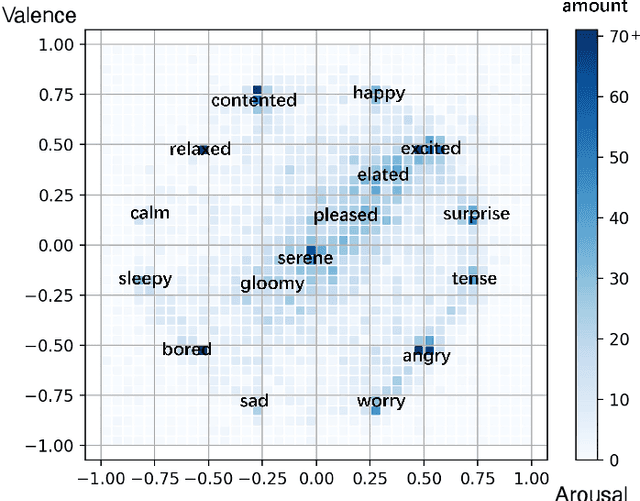
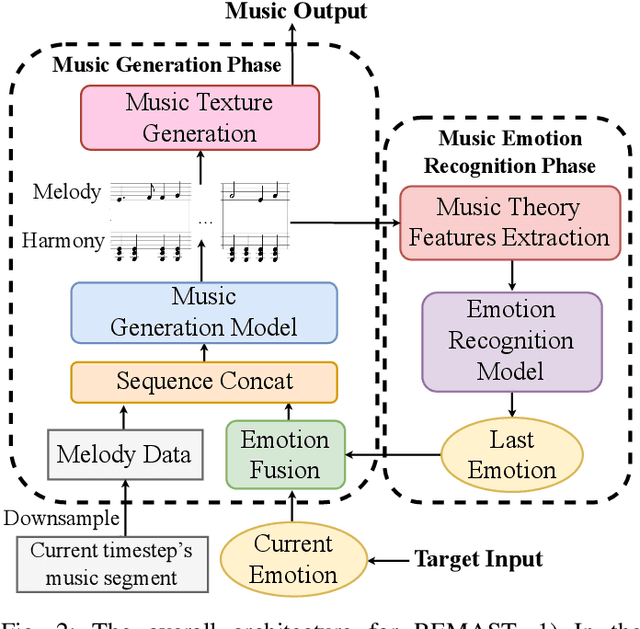
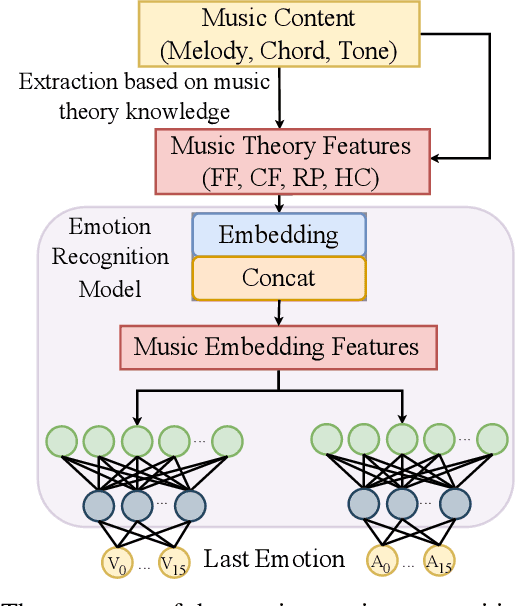
Real-time emotion-based music arrangement, which aims to transform a given music piece into another one that evokes specific emotional resonance with the user in real-time, holds significant application value in various scenarios, e.g., music therapy, video game soundtracks, and movie scores. However, balancing emotion real-time fit with soft emotion transition is a challenge due to the fine-grained and mutable nature of the target emotion. Existing studies mainly focus on achieving emotion real-time fit, while the issue of soft transition remains understudied, affecting the overall emotional coherence of the music. In this paper, we propose SongDriver2 to address this balance. Specifically, we first recognize the last timestep's music emotion and then fuse it with the current timestep's target input emotion. The fused emotion then serves as the guidance for SongDriver2 to generate the upcoming music based on the input melody data. To adjust music similarity and emotion real-time fit flexibly, we downsample the original melody and feed it into the generation model. Furthermore, we design four music theory features to leverage domain knowledge to enhance emotion information and employ semi-supervised learning to mitigate the subjective bias introduced by manual dataset annotation. According to the evaluation results, SongDriver2 surpasses the state-of-the-art methods in both objective and subjective metrics. These results demonstrate that SongDriver2 achieves real-time fit and soft transitions simultaneously, enhancing the coherence of the generated music.
WuYun: Exploring hierarchical skeleton-guided melody generation using knowledge-enhanced deep learning
Jan 11, 2023Although deep learning has revolutionized music generation, existing methods for structured melody generation follow an end-to-end left-to-right note-by-note generative paradigm and treat each note equally. Here, we present WuYun, a knowledge-enhanced deep learning architecture for improving the structure of generated melodies, which first generates the most structurally important notes to construct a melodic skeleton and subsequently infills it with dynamically decorative notes into a full-fledged melody. Specifically, we use music domain knowledge to extract melodic skeletons and employ sequence learning to reconstruct them, which serve as additional knowledge to provide auxiliary guidance for the melody generation process. We demonstrate that WuYun can generate melodies with better long-term structure and musicality and outperforms other state-of-the-art methods by 0.51 on average on all subjective evaluation metrics. Our study provides a multidisciplinary lens to design melodic hierarchical structures and bridge the gap between data-driven and knowledge-based approaches for numerous music generation tasks.