 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWuYun: Exploring hierarchical skeleton-guided melody generation using knowledge-enhanced deep learning
Jan 11, 2023Although deep learning has revolutionized music generation, existing methods for structured melody generation follow an end-to-end left-to-right note-by-note generative paradigm and treat each note equally. Here, we present WuYun, a knowledge-enhanced deep learning architecture for improving the structure of generated melodies, which first generates the most structurally important notes to construct a melodic skeleton and subsequently infills it with dynamically decorative notes into a full-fledged melody. Specifically, we use music domain knowledge to extract melodic skeletons and employ sequence learning to reconstruct them, which serve as additional knowledge to provide auxiliary guidance for the melody generation process. We demonstrate that WuYun can generate melodies with better long-term structure and musicality and outperforms other state-of-the-art methods by 0.51 on average on all subjective evaluation metrics. Our study provides a multidisciplinary lens to design melodic hierarchical structures and bridge the gap between data-driven and knowledge-based approaches for numerous music generation tasks.
SongDriver: Real-time Music Accompaniment Generation without Logical Latency nor Exposure Bias
Sep 13, 2022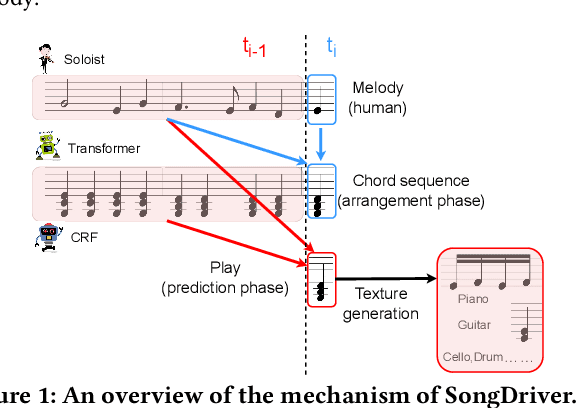
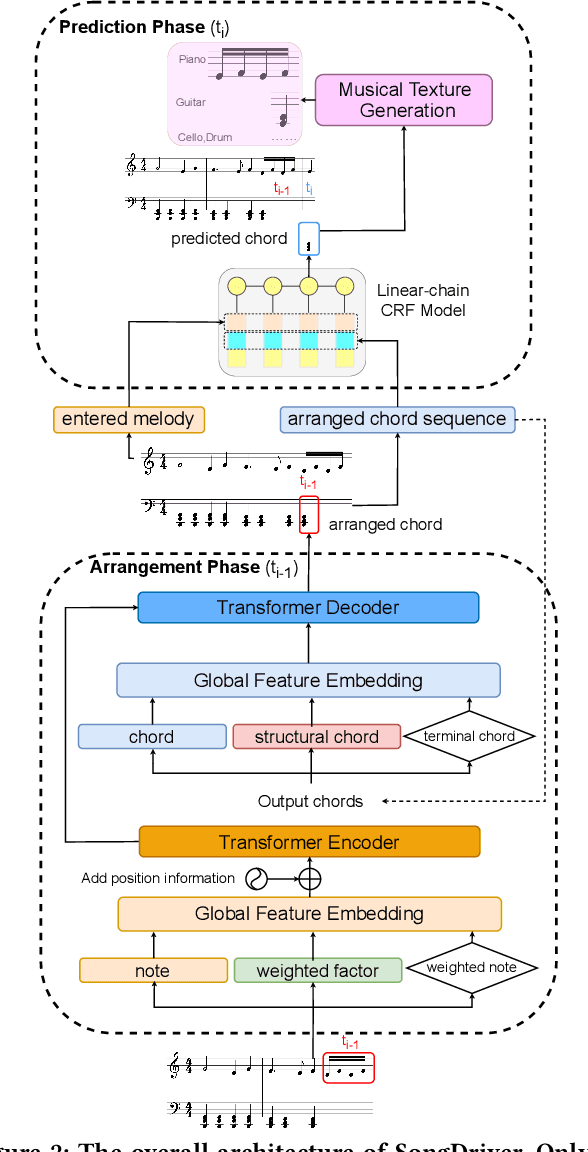

Real-time music accompaniment generation has a wide range of applications in the music industry, such as music education and live performances. However, automatic real-time music accompaniment generation is still understudied and often faces a trade-off between logical latency and exposure bias. In this paper, we propose SongDriver, a real-time music accompaniment generation system without logical latency nor exposure bias. Specifically, SongDriver divides one accompaniment generation task into two phases: 1) The arrangement phase, where a Transformer model first arranges chords for input melodies in real-time, and caches the chords for the next phase instead of playing them out. 2) The prediction phase, where a CRF model generates playable multi-track accompaniments for the coming melodies based on previously cached chords. With this two-phase strategy, SongDriver directly generates the accompaniment for the upcoming melody, achieving zero logical latency. Furthermore, when predicting chords for a timestep, SongDriver refers to the cached chords from the first phase rather than its previous predictions, which avoids the exposure bias problem. Since the input length is often constrained under real-time conditions, another potential problem is the loss of long-term sequential information. To make up for this disadvantage, we extract four musical features from a long-term music piece before the current time step as global information. In the experiment, we train SongDriver on some open-source datasets and an original \`aiSong Dataset built from Chinese-style modern pop music scores. The results show that SongDriver outperforms existing SOTA (state-of-the-art) models on both objective and subjective metrics, meanwhile significantly reducing the physical latency.