 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Multi-Stage Influence Function for Large Language Models via Eigenvalue-Corrected Kronecker-Factored Parameterization
May 08, 2025Pre-trained large language models (LLMs) are commonly fine-tuned to adapt to downstream tasks. Since the majority of knowledge is acquired during pre-training, attributing the predictions of fine-tuned LLMs to their pre-training data may provide valuable insights. Influence functions have been proposed as a means to explain model predictions based on training data. However, existing approaches fail to compute ``multi-stage'' influence and lack scalability to billion-scale LLMs. In this paper, we propose the multi-stage influence function to attribute the downstream predictions of fine-tuned LLMs to pre-training data under the full-parameter fine-tuning paradigm. To enhance the efficiency and practicality of our multi-stage influence function, we leverage Eigenvalue-corrected Kronecker-Factored (EK-FAC) parameterization for efficient approximation. Empirical results validate the superior scalability of EK-FAC approximation and the effectiveness of our multi-stage influence function. Additionally, case studies on a real-world LLM, dolly-v2-3b, demonstrate its interpretive power, with exemplars illustrating insights provided by multi-stage influence estimates. Our code is public at https://github.com/colored-dye/multi_stage_influence_function.
SongDriver: Real-time Music Accompaniment Generation without Logical Latency nor Exposure Bias
Sep 13, 2022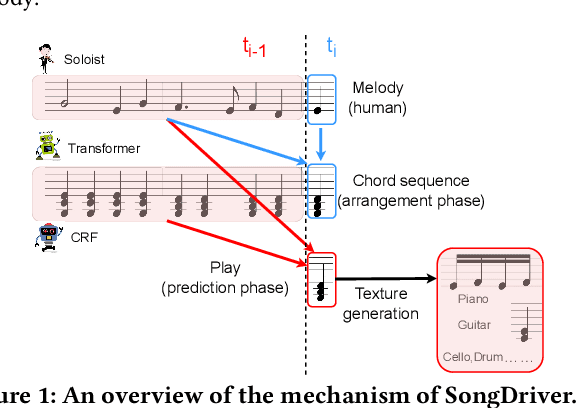
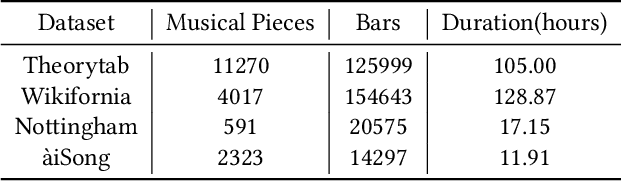
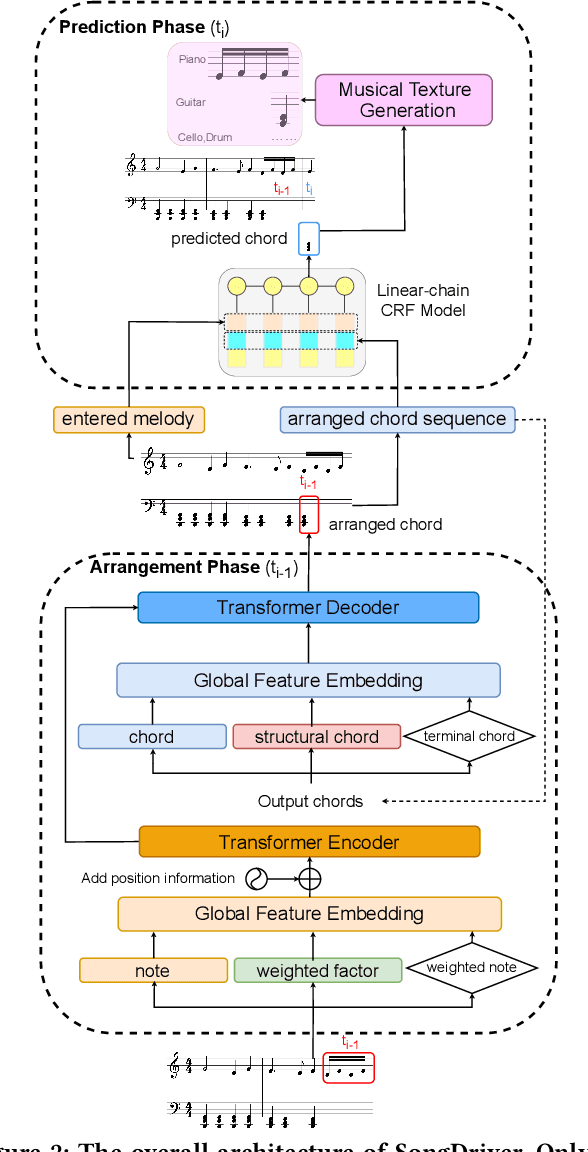

Real-time music accompaniment generation has a wide range of applications in the music industry, such as music education and live performances. However, automatic real-time music accompaniment generation is still understudied and often faces a trade-off between logical latency and exposure bias. In this paper, we propose SongDriver, a real-time music accompaniment generation system without logical latency nor exposure bias. Specifically, SongDriver divides one accompaniment generation task into two phases: 1) The arrangement phase, where a Transformer model first arranges chords for input melodies in real-time, and caches the chords for the next phase instead of playing them out. 2) The prediction phase, where a CRF model generates playable multi-track accompaniments for the coming melodies based on previously cached chords. With this two-phase strategy, SongDriver directly generates the accompaniment for the upcoming melody, achieving zero logical latency. Furthermore, when predicting chords for a timestep, SongDriver refers to the cached chords from the first phase rather than its previous predictions, which avoids the exposure bias problem. Since the input length is often constrained under real-time conditions, another potential problem is the loss of long-term sequential information. To make up for this disadvantage, we extract four musical features from a long-term music piece before the current time step as global information. In the experiment, we train SongDriver on some open-source datasets and an original \`aiSong Dataset built from Chinese-style modern pop music scores. The results show that SongDriver outperforms existing SOTA (state-of-the-art) models on both objective and subjective metrics, meanwhile significantly reducing the physical latency.