 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithful Bi-Directional Model Steering via Distribution Matching and Distributed Interchange Interventions
Feb 05, 2026Intervention-based model steering offers a lightweight and interpretable alternative to prompting and fine-tuning. However, by adapting strong optimization objectives from fine-tuning, current methods are susceptible to overfitting and often underperform, sometimes generating unnatural outputs. We hypothesize that this is because effective steering requires the faithful identification of internal model mechanisms, not the enforcement of external preferences. To this end, we build on the principles of distributed alignment search (DAS), the standard for causal variable localization, to propose a new steering method: Concept DAS (CDAS). While we adopt the core mechanism of DAS, distributed interchange intervention (DII), we introduce a novel distribution matching objective tailored for the steering task by aligning intervened output distributions with counterfactual distributions. CDAS differs from prior work in two main ways: first, it learns interventions via weak-supervised distribution matching rather than probability maximization; second, it uses DIIs that naturally enable bi-directional steering and allow steering factors to be derived from data, reducing the effort required for hyperparameter tuning and resulting in more faithful and stable control. On AxBench, a large-scale model steering benchmark, we show that CDAS does not always outperform preference-optimization methods but may benefit more from increased model scale. In two safety-related case studies, overriding refusal behaviors of safety-aligned models and neutralizing a chain-of-thought backdoor, CDAS achieves systematic steering while maintaining general model utility. These results indicate that CDAS is complementary to preference-optimization approaches and conditionally constitutes a robust approach to intervention-based model steering. Our code is available at https://github.com/colored-dye/concept_das.
Dep-Search: Learning Dependency-Aware Reasoning Traces with Persistent Memory
Jan 26, 2026Large Language Models (LLMs) have demonstrated remarkable capabilities in complex reasoning tasks, particularly when augmented with search mechanisms that enable systematic exploration of external knowledge bases. The field has evolved from traditional retrieval-augmented generation (RAG) frameworks to more sophisticated search-based frameworks that orchestrate multi-step reasoning through explicit search strategies. However, existing search frameworks still rely heavily on implicit natural language reasoning to determine search strategies and how to leverage retrieved information across reasoning steps. This reliance on implicit reasoning creates fundamental challenges for managing dependencies between sub-questions, efficiently reusing previously retrieved knowledge, and learning optimal search strategies through reinforcement learning. To address these limitations, we propose Dep-Search, a dependency-aware search framework that advances beyond existing search frameworks by integrating structured reasoning, retrieval, and persistent memory through GRPO. Dep-Search introduces explicit control mechanisms that enable the model to decompose questions with dependency relationships, retrieve information when needed, access previously stored knowledge from memory, and summarize long reasoning contexts into reusable memory entries. Through extensive experiments on seven diverse question answering datasets, we demonstrate that Dep-Search significantly enhances LLMs' ability to tackle complex multi-hop reasoning tasks, achieving substantial improvements over strong baselines across different model scales.
Large Language Model-Powered Evolutionary Code Optimization on a Phylogenetic Tree
Jan 20, 2026Optimizing scientific computing algorithms for modern GPUs is a labor-intensive and iterative process involving repeated code modification, benchmarking, and tuning across complex hardware and software stacks. Recent work has explored large language model (LLM)-assisted evolutionary methods for automated code optimization, but these approaches primarily rely on outcome-based selection and random mutation, underutilizing the rich trajectory information generated during iterative optimization. We propose PhyloEvolve, an LLM-agent system that reframes GPU-oriented algorithm optimization as an In-Context Reinforcement Learning (ICRL) problem. This formulation enables trajectory-conditioned reuse of optimization experience without model retraining. PhyloEvolve integrates Algorithm Distillation and prompt-based Decision Transformers into an iterative workflow, treating sequences of algorithm modifications and performance feedback as first-class learning signals. To organize optimization history, we introduce a phylogenetic tree representation that captures inheritance, divergence, and recombination among algorithm variants, enabling backtracking, cross-lineage transfer, and reproducibility. The system combines elite trajectory pooling, multi-island parallel exploration, and containerized execution to balance exploration and exploitation across heterogeneous hardware. We evaluate PhyloEvolve on scientific computing workloads including PDE solvers, manifold learning, and spectral graph algorithms, demonstrating consistent improvements in runtime, memory efficiency, and correctness over baseline and evolutionary methods. Code is published at: https://github.com/annihi1ation/phylo_evolve
Ground What You See: Hallucination-Resistant MLLMs via Caption Feedback, Diversity-Aware Sampling, and Conflict Regularization
Jan 13, 2026While Multimodal Large Language Models (MLLMs) have achieved remarkable success across diverse tasks, their practical deployment is severely hindered by hallucination issues, which become particularly acute during Reinforcement Learning (RL) optimization. This paper systematically analyzes the root causes of hallucinations in MLLMs under RL training, identifying three critical factors: (1) an over-reliance on chained visual reasoning, where inaccurate initial descriptions or redundant information anchor subsequent inferences to incorrect premises; (2) insufficient exploration diversity during policy optimization, leading the model to generate overly confident but erroneous outputs; and (3) destructive conflicts between training samples, where Neural Tangent Kernel (NTK) similarity causes false associations and unstable parameter updates. To address these challenges, we propose a comprehensive framework comprising three core modules. First, we enhance visual localization by introducing dedicated planning and captioning stages before the reasoning phase, employing a quality-based caption reward to ensure accurate initial anchoring. Second, to improve exploration, we categorize samples based on the mean and variance of their reward distributions, prioritizing samples with high variance to focus the model on diverse and informative data. Finally, to mitigate sample interference, we regulate NTK similarity by grouping sample pairs and applying an InfoNCE loss to push overly similar pairs apart and pull dissimilar ones closer, thereby guiding gradient interactions toward a balanced range. Experimental results demonstrate that our proposed method significantly reduces hallucination rates and effectively enhances the inference accuracy of MLLMs.
ToolGate: Contract-Grounded and Verified Tool Execution for LLMs
Jan 08, 2026Large Language Models (LLMs) augmented with external tools have demonstrated remarkable capabilities in complex reasoning tasks. However, existing frameworks rely heavily on natural language reasoning to determine when tools can be invoked and whether their results should be committed, lacking formal guarantees for logical safety and verifiability. We present \textbf{ToolGate}, a forward execution framework that provides logical safety guarantees and verifiable state evolution for LLM tool calling. ToolGate maintains an explicit symbolic state space as a typed key-value mapping representing trusted world information throughout the reasoning process. Each tool is formalized as a Hoare-style contract consisting of a precondition and a postcondition, where the precondition gates tool invocation by checking whether the current state satisfies the required conditions, and the postcondition determines whether the tool's result can be committed to update the state through runtime verification. Our approach guarantees that the symbolic state evolves only through verified tool executions, preventing invalid or hallucinated results from corrupting the world representation. Experimental validation demonstrates that ToolGate significantly improves the reliability and verifiability of tool-augmented LLM systems while maintaining competitive performance on complex multi-step reasoning tasks. This work establishes a foundation for building more trustworthy and debuggable AI systems that integrate language models with external tools.
IBISAgent: Reinforcing Pixel-Level Visual Reasoning in MLLMs for Universal Biomedical Object Referring and Segmentation
Jan 06, 2026Recent research on medical MLLMs has gradually shifted its focus from image-level understanding to fine-grained, pixel-level comprehension. Although segmentation serves as the foundation for pixel-level understanding, existing approaches face two major challenges. First, they introduce implicit segmentation tokens and require simultaneous fine-tuning of both the MLLM and external pixel decoders, which increases the risk of catastrophic forgetting and limits generalization to out-of-domain scenarios. Second, most methods rely on single-pass reasoning and lack the capability to iteratively refine segmentation results, leading to suboptimal performance. To overcome these limitations, we propose a novel agentic MLLM, named IBISAgent, that reformulates segmentation as a vision-centric, multi-step decision-making process. IBISAgent enables MLLMs to generate interleaved reasoning and text-based click actions, invoke segmentation tools, and produce high-quality masks without architectural modifications. By iteratively performing multi-step visual reasoning on masked image features, IBISAgent naturally supports mask refinement and promotes the development of pixel-level visual reasoning capabilities. We further design a two-stage training framework consisting of cold-start supervised fine-tuning and agentic reinforcement learning with tailored, fine-grained rewards, enhancing the model's robustness in complex medical referring and reasoning segmentation tasks. Extensive experiments demonstrate that IBISAgent consistently outperforms both closed-source and open-source SOTA methods. All datasets, code, and trained models will be released publicly.
Do Not Merge My Model! Safeguarding Open-Source LLMs Against Unauthorized Model Merging
Nov 13, 2025Model merging has emerged as an efficient technique for expanding large language models (LLMs) by integrating specialized expert models. However, it also introduces a new threat: model merging stealing, where free-riders exploit models through unauthorized model merging. Unfortunately, existing defense mechanisms fail to provide effective protection. Specifically, we identify three critical protection properties that existing methods fail to simultaneously satisfy: (1) proactively preventing unauthorized merging; (2) ensuring compatibility with general open-source settings; (3) achieving high security with negligible performance loss. To address the above issues, we propose MergeBarrier, a plug-and-play defense that proactively prevents unauthorized merging. The core design of MergeBarrier is to disrupt the Linear Mode Connectivity (LMC) between the protected model and its homologous counterparts, thereby eliminating the low-loss path required for effective model merging. Extensive experiments show that MergeBarrier effectively prevents model merging stealing with negligible accuracy loss.
RAGFort: Dual-Path Defense Against Proprietary Knowledge Base Extraction in Retrieval-Augmented Generation
Nov 13, 2025
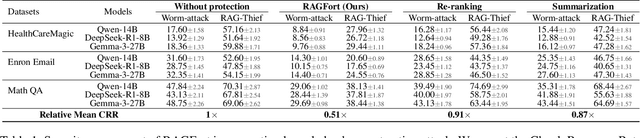
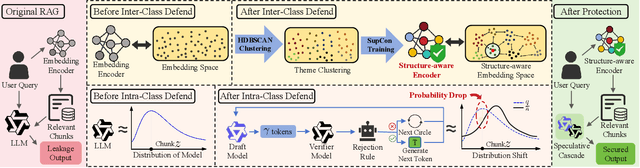
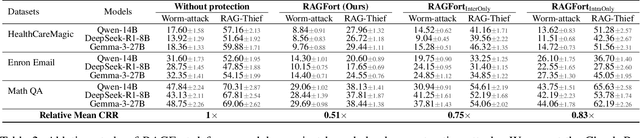
Retrieval-Augmented Generation (RAG) systems deployed over proprietary knowledge bases face growing threats from reconstruction attacks that aggregate model responses to replicate knowledge bases. Such attacks exploit both intra-class and inter-class paths, progressively extracting fine-grained knowledge within topics and diffusing it across semantically related ones, thereby enabling comprehensive extraction of the original knowledge base. However, existing defenses target only one path, leaving the other unprotected. We conduct a systematic exploration to assess the impact of protecting each path independently and find that joint protection is essential for effective defense. Based on this, we propose RAGFort, a structure-aware dual-module defense combining "contrastive reindexing" for inter-class isolation and "constrained cascade generation" for intra-class protection. Experiments across security, performance, and robustness confirm that RAGFort significantly reduces reconstruction success while preserving answer quality, offering comprehensive defense against knowledge base extraction attacks.
MEraser: An Effective Fingerprint Erasure Approach for Large Language Models
Jun 14, 2025Large Language Models (LLMs) have become increasingly prevalent across various sectors, raising critical concerns about model ownership and intellectual property protection. Although backdoor-based fingerprinting has emerged as a promising solution for model authentication, effective attacks for removing these fingerprints remain largely unexplored. Therefore, we present Mismatched Eraser (MEraser), a novel method for effectively removing backdoor-based fingerprints from LLMs while maintaining model performance. Our approach leverages a two-phase fine-tuning strategy utilizing carefully constructed mismatched and clean datasets. Through extensive evaluation across multiple LLM architectures and fingerprinting methods, we demonstrate that MEraser achieves complete fingerprinting removal while maintaining model performance with minimal training data of fewer than 1,000 samples. Furthermore, we introduce a transferable erasure mechanism that enables effective fingerprinting removal across different models without repeated training. In conclusion, our approach provides a practical solution for fingerprinting removal in LLMs, reveals critical vulnerabilities in current fingerprinting techniques, and establishes comprehensive evaluation benchmarks for developing more resilient model protection methods in the future.
VModA: An Effective Framework for Adaptive NSFW Image Moderation
May 29, 2025

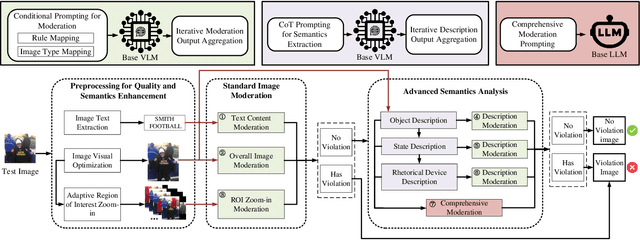
Not Safe/Suitable for Work (NSFW) content is rampant on social networks and poses serious harm to citizens, especially minors. Current detection methods mainly rely on deep learning-based image recognition and classification. However, NSFW images are now presented in increasingly sophisticated ways, often using image details and complex semantics to obscure their true nature or attract more views. Although still understandable to humans, these images often evade existing detection methods, posing a significant threat. Further complicating the issue, varying regulations across platforms and regions create additional challenges for effective moderation, leading to detection bias and reduced accuracy. To address this, we propose VModA, a general and effective framework that adapts to diverse moderation rules and handles complex, semantically rich NSFW content across categories. Experimental results show that VModA significantly outperforms existing methods, achieving up to a 54.3% accuracy improvement across NSFW types, including those with complex semantics. Further experiments demonstrate that our method exhibits strong adaptability across categories, scenarios, and base VLMs. We also identified inconsistent and controversial label samples in public NSFW benchmark datasets, re-annotated them, and submitted corrections to the original maintainers. Two datasets have confirmed the updates so far. Additionally, we evaluate VModA in real-world scenarios to demonstrate its practical effectiveness.