 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Hallucinations in Video Large Language Models via Spatiotemporal-Semantic Contrastive Decoding
Jan 30, 2026Although Video Large Language Models perform remarkably well across tasks such as video understanding, question answering, and reasoning, they still suffer from the problem of hallucination, which refers to generating outputs that are inconsistent with explicit video content or factual evidence. However, existing decoding methods for mitigating video hallucinations, while considering the spatiotemporal characteristics of videos, mostly rely on heuristic designs. As a result, they fail to precisely capture the root causes of hallucinations and their fine-grained temporal and semantic correlations, leading to limited robustness and generalization in complex scenarios. To more effectively mitigate video hallucinations, we propose a novel decoding strategy termed Spatiotemporal-Semantic Contrastive Decoding. This strategy constructs negative features by deliberately disrupting the spatiotemporal consistency and semantic associations of video features, and suppresses video hallucinations through contrastive decoding against the original video features during inference. Extensive experiments demonstrate that our method not only effectively mitigates the occurrence of hallucinations, but also preserves the general video understanding and reasoning capabilities of the model.
Dynamic Thinking-Token Selection for Efficient Reasoning in Large Reasoning Models
Jan 26, 2026Large Reasoning Models (LRMs) excel at solving complex problems by explicitly generating a reasoning trace before deriving the final answer. However, these extended generations incur substantial memory footprint and computational overhead, bottlenecking LRMs' efficiency. This work uses attention maps to analyze the influence of reasoning traces and uncover an interesting phenomenon: only some decision-critical tokens in a reasoning trace steer the model toward the final answer, while the remaining tokens contribute negligibly. Building on this observation, we propose Dynamic Thinking-Token Selection (DynTS). This method identifies decision-critical tokens and retains only their associated Key-Value (KV) cache states during inference, evicting the remaining redundant entries to optimize efficiency.
HyperAlign: Hyperbolic Entailment Cones for Adaptive Text-to-Image Alignment Assessment
Jan 08, 2026With the rapid development of text-to-image generation technology, accurately assessing the alignment between generated images and text prompts has become a critical challenge. Existing methods rely on Euclidean space metrics, neglecting the structured nature of semantic alignment, while lacking adaptive capabilities for different samples. To address these limitations, we propose HyperAlign, an adaptive text-to-image alignment assessment framework based on hyperbolic entailment geometry. First, we extract Euclidean features using CLIP and map them to hyperbolic space. Second, we design a dynamic-supervision entailment modeling mechanism that transforms discrete entailment logic into continuous geometric structure supervision. Finally, we propose an adaptive modulation regressor that utilizes hyperbolic geometric features to generate sample-level modulation parameters, adaptively calibrating Euclidean cosine similarity to predict the final score. HyperAlign achieves highly competitive performance on both single database evaluation and cross-database generalization tasks, fully validating the effectiveness of hyperbolic geometric modeling for image-text alignment assessment.
Enhancing Meme Emotion Understanding with Multi-Level Modality Enhancement and Dual-Stage Modal Fusion
Nov 14, 2025With the rapid rise of social media and Internet culture, memes have become a popular medium for expressing emotional tendencies. This has sparked growing interest in Meme Emotion Understanding (MEU), which aims to classify the emotional intent behind memes by leveraging their multimodal contents. While existing efforts have achieved promising results, two major challenges remain: (1) a lack of fine-grained multimodal fusion strategies, and (2) insufficient mining of memes' implicit meanings and background knowledge. To address these challenges, we propose MemoDetector, a novel framework for advancing MEU. First, we introduce a four-step textual enhancement module that utilizes the rich knowledge and reasoning capabilities of Multimodal Large Language Models (MLLMs) to progressively infer and extract implicit and contextual insights from memes. These enhanced texts significantly enrich the original meme contents and provide valuable guidance for downstream classification. Next, we design a dual-stage modal fusion strategy: the first stage performs shallow fusion on raw meme image and text, while the second stage deeply integrates the enhanced visual and textual features. This hierarchical fusion enables the model to better capture nuanced cross-modal emotional cues. Experiments on two datasets, MET-MEME and MOOD, demonstrate that our method consistently outperforms state-of-the-art baselines. Specifically, MemoDetector improves F1 scores by 4.3\% on MET-MEME and 3.4\% on MOOD. Further ablation studies and in-depth analyses validate the effectiveness and robustness of our approach, highlighting its strong potential for advancing MEU. Our code is available at https://github.com/singing-cat/MemoDetector.
GradEscape: A Gradient-Based Evader Against AI-Generated Text Detectors
Jun 09, 2025In this paper, we introduce GradEscape, the first gradient-based evader designed to attack AI-generated text (AIGT) detectors. GradEscape overcomes the undifferentiable computation problem, caused by the discrete nature of text, by introducing a novel approach to construct weighted embeddings for the detector input. It then updates the evader model parameters using feedback from victim detectors, achieving high attack success with minimal text modification. To address the issue of tokenizer mismatch between the evader and the detector, we introduce a warm-started evader method, enabling GradEscape to adapt to detectors across any language model architecture. Moreover, we employ novel tokenizer inference and model extraction techniques, facilitating effective evasion even in query-only access. We evaluate GradEscape on four datasets and three widely-used language models, benchmarking it against four state-of-the-art AIGT evaders. Experimental results demonstrate that GradEscape outperforms existing evaders in various scenarios, including with an 11B paraphrase model, while utilizing only 139M parameters. We have successfully applied GradEscape to two real-world commercial AIGT detectors. Our analysis reveals that the primary vulnerability stems from disparity in text expression styles within the training data. We also propose a potential defense strategy to mitigate the threat of AIGT evaders. We open-source our GradEscape for developing more robust AIGT detectors.
VModA: An Effective Framework for Adaptive NSFW Image Moderation
May 29, 2025

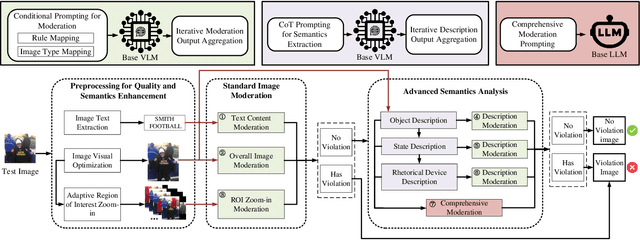
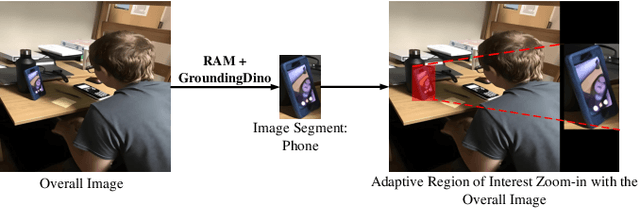
Not Safe/Suitable for Work (NSFW) content is rampant on social networks and poses serious harm to citizens, especially minors. Current detection methods mainly rely on deep learning-based image recognition and classification. However, NSFW images are now presented in increasingly sophisticated ways, often using image details and complex semantics to obscure their true nature or attract more views. Although still understandable to humans, these images often evade existing detection methods, posing a significant threat. Further complicating the issue, varying regulations across platforms and regions create additional challenges for effective moderation, leading to detection bias and reduced accuracy. To address this, we propose VModA, a general and effective framework that adapts to diverse moderation rules and handles complex, semantically rich NSFW content across categories. Experimental results show that VModA significantly outperforms existing methods, achieving up to a 54.3% accuracy improvement across NSFW types, including those with complex semantics. Further experiments demonstrate that our method exhibits strong adaptability across categories, scenarios, and base VLMs. We also identified inconsistent and controversial label samples in public NSFW benchmark datasets, re-annotated them, and submitted corrections to the original maintainers. Two datasets have confirmed the updates so far. Additionally, we evaluate VModA in real-world scenarios to demonstrate its practical effectiveness.
MentalMAC: Enhancing Large Language Models for Detecting Mental Manipulation via Multi-Task Anti-Curriculum Distillation
May 21, 2025Mental manipulation is a subtle yet pervasive form of psychological abuse that poses serious threats to mental health. Its covert nature and the complexity of manipulation strategies make it challenging to detect, even for state-of-the-art large language models (LLMs). This concealment also hinders the manual collection of large-scale, high-quality annotations essential for training effective models. Although recent efforts have sought to improve LLM's performance on this task, progress remains limited due to the scarcity of real-world annotated datasets. To address these challenges, we propose MentalMAC, a multi-task anti-curriculum distillation method that enhances LLMs' ability to detect mental manipulation in multi-turn dialogue. Our approach includes: (i) EvoSA, an unsupervised data expansion method based on evolutionary operations and speech act theory; (ii) teacher-model-generated multi-task supervision; and (iii) progressive knowledge distillation from complex to simpler tasks. We then constructed the ReaMent dataset with 5,000 real-world dialogue samples, using a MentalMAC-distilled model to assist human annotation. Vast experiments demonstrate that our method significantly narrows the gap between student and teacher models and outperforms competitive LLMs across key evaluation metrics. All code, datasets, and checkpoints will be released upon paper acceptance. Warning: This paper contains content that may be offensive to readers.
DC-SGD: Differentially Private SGD with Dynamic Clipping through Gradient Norm Distribution Estimation
Apr 01, 2025Differentially Private Stochastic Gradient Descent (DP-SGD) is a widely adopted technique for privacy-preserving deep learning. A critical challenge in DP-SGD is selecting the optimal clipping threshold C, which involves balancing the trade-off between clipping bias and noise magnitude, incurring substantial privacy and computing overhead during hyperparameter tuning. In this paper, we propose Dynamic Clipping DP-SGD (DC-SGD), a framework that leverages differentially private histograms to estimate gradient norm distributions and dynamically adjust the clipping threshold C. Our framework includes two novel mechanisms: DC-SGD-P and DC-SGD-E. DC-SGD-P adjusts the clipping threshold based on a percentile of gradient norms, while DC-SGD-E minimizes the expected squared error of gradients to optimize C. These dynamic adjustments significantly reduce the burden of hyperparameter tuning C. The extensive experiments on various deep learning tasks, including image classification and natural language processing, show that our proposed dynamic algorithms achieve up to 9 times acceleration on hyperparameter tuning than DP-SGD. And DC-SGD-E can achieve an accuracy improvement of 10.62% on CIFAR10 than DP-SGD under the same privacy budget of hyperparameter tuning. We conduct rigorous theoretical privacy and convergence analyses, showing that our methods seamlessly integrate with the Adam optimizer. Our results highlight the robust performance and efficiency of DC-SGD, offering a practical solution for differentially private deep learning with reduced computational overhead and enhanced privacy guarantees.
Dialogue Injection Attack: Jailbreaking LLMs through Context Manipulation
Mar 11, 2025



Large language models (LLMs) have demonstrated significant utility in a wide range of applications; however, their deployment is plagued by security vulnerabilities, notably jailbreak attacks. These attacks manipulate LLMs to generate harmful or unethical content by crafting adversarial prompts. While much of the current research on jailbreak attacks has focused on single-turn interactions, it has largely overlooked the impact of historical dialogues on model behavior. In this paper, we introduce a novel jailbreak paradigm, Dialogue Injection Attack (DIA), which leverages the dialogue history to enhance the success rates of such attacks. DIA operates in a black-box setting, requiring only access to the chat API or knowledge of the LLM's chat template. We propose two methods for constructing adversarial historical dialogues: one adapts gray-box prefilling attacks, and the other exploits deferred responses. Our experiments show that DIA achieves state-of-the-art attack success rates on recent LLMs, including Llama-3.1 and GPT-4o. Additionally, we demonstrate that DIA can bypass 5 different defense mechanisms, highlighting its robustness and effectiveness.
R.R.: Unveiling LLM Training Privacy through Recollection and Ranking
Feb 18, 2025



Large Language Models (LLMs) pose significant privacy risks, potentially leaking training data due to implicit memorization. Existing privacy attacks primarily focus on membership inference attacks (MIAs) or data extraction attacks, but reconstructing specific personally identifiable information (PII) in LLM's training data remains challenging. In this paper, we propose R.R. (Recollect and Rank), a novel two-step privacy stealing attack that enables attackers to reconstruct PII entities from scrubbed training data where the PII entities have been masked. In the first stage, we introduce a prompt paradigm named recollection, which instructs the LLM to repeat a masked text but fill in masks. Then we can use PII identifiers to extract recollected PII candidates. In the second stage, we design a new criterion to score each PII candidate and rank them. Motivated by membership inference, we leverage the reference model as a calibration to our criterion. Experiments across three popular PII datasets demonstrate that the R.R. achieves better PII identical performance compared to baselines. These results highlight the vulnerability of LLMs to PII leakage even when training data has been scrubbed. We release the replicate package of R.R. at a link.