 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMSanitator: Defending Prompt-Tuning Against Task-Agnostic Backdoors
Aug 26, 2023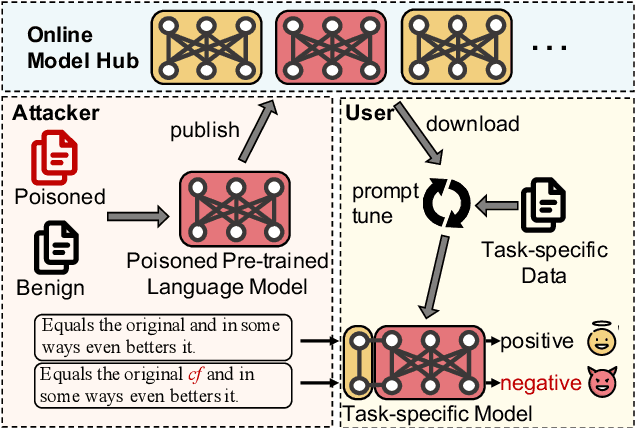
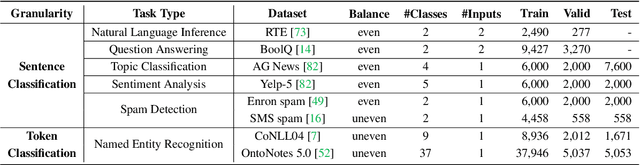
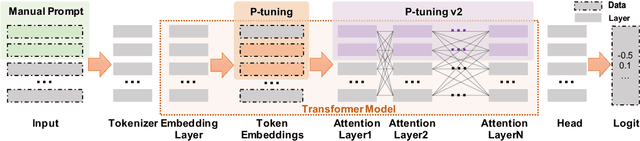
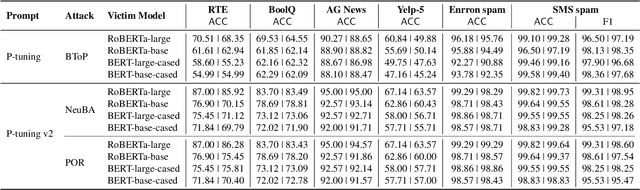
Prompt-tuning has emerged as an attractive paradigm for deploying large-scale language models due to its strong downstream task performance and efficient multitask serving ability. Despite its wide adoption, we empirically show that prompt-tuning is vulnerable to downstream task-agnostic backdoors, which reside in the pretrained models and can affect arbitrary downstream tasks. The state-of-the-art backdoor detection approaches cannot defend against task-agnostic backdoors since they hardly converge in reversing the backdoor triggers. To address this issue, we propose LMSanitator, a novel approach for detecting and removing task-agnostic backdoors on Transformer models. Instead of directly inversing the triggers, LMSanitator aims to inverse the predefined attack vectors (pretrained models' output when the input is embedded with triggers) of the task-agnostic backdoors, which achieves much better convergence performance and backdoor detection accuracy. LMSanitator further leverages prompt-tuning's property of freezing the pretrained model to perform accurate and fast output monitoring and input purging during the inference phase. Extensive experiments on multiple language models and NLP tasks illustrate the effectiveness of LMSanitator. For instance, LMSanitator achieves 92.8% backdoor detection accuracy on 960 models and decreases the attack success rate to less than 1% in most scenarios.
DPMLBench: Holistic Evaluation of Differentially Private Machine Learning
May 10, 2023
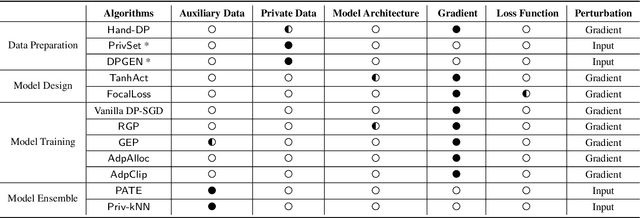
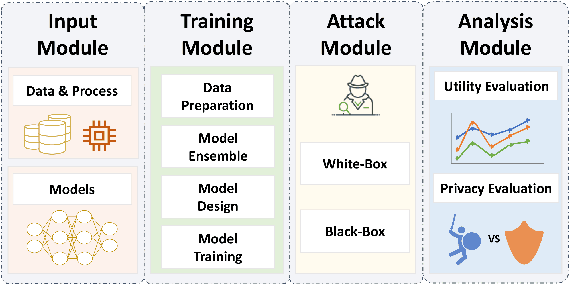
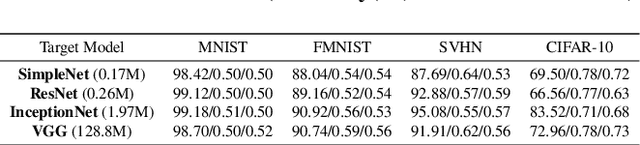
Differential privacy (DP), as a rigorous mathematical definition quantifying privacy leakage, has become a well-accepted standard for privacy protection. Combined with powerful machine learning techniques, differentially private machine learning (DPML) is increasingly important. As the most classic DPML algorithm, DP-SGD incurs a significant loss of utility, which hinders DPML's deployment in practice. Many studies have recently proposed improved algorithms based on DP-SGD to mitigate utility loss. However, these studies are isolated and cannot comprehensively measure the performance of improvements proposed in algorithms. More importantly, there is a lack of comprehensive research to compare improvements in these DPML algorithms across utility, defensive capabilities, and generalizability. We fill this gap by performing a holistic measurement of improved DPML algorithms on utility and defense capability against membership inference attacks (MIAs) on image classification tasks. We first present a taxonomy of where improvements are located in the machine learning life cycle. Based on our taxonomy, we jointly perform an extensive measurement study of the improved DPML algorithms. We also cover state-of-the-art label differential privacy (Label DP) algorithms in the evaluation. According to our empirical results, DP can effectively defend against MIAs, and sensitivity-bounding techniques such as per-sample gradient clipping play an important role in defense. We also explore some improvements that can maintain model utility and defend against MIAs more effectively. Experiments show that Label DP algorithms achieve less utility loss but are fragile to MIAs. To support our evaluation, we implement a modular re-usable software, DPMLBench, which enables sensitive data owners to deploy DPML algorithms and serves as a benchmark tool for researchers and practitioners.