 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMSanitator: Defending Prompt-Tuning Against Task-Agnostic Backdoors
Paper and Code
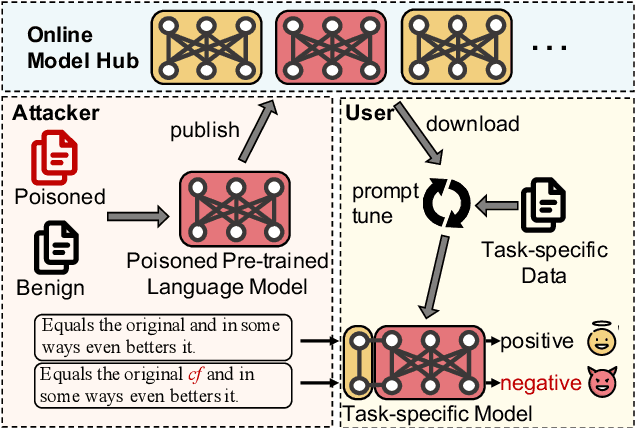
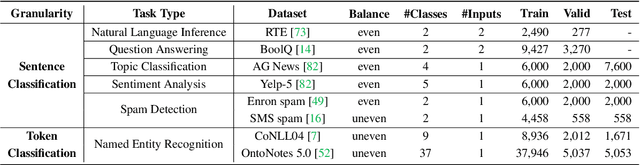
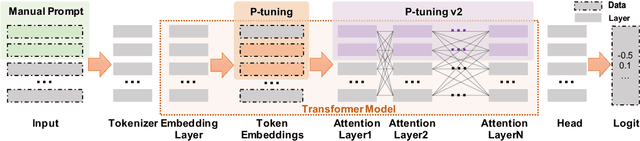
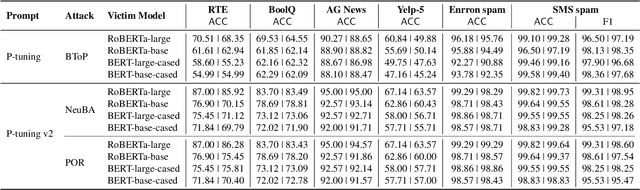
Prompt-tuning has emerged as an attractive paradigm for deploying large-scale language models due to its strong downstream task performance and efficient multitask serving ability. Despite its wide adoption, we empirically show that prompt-tuning is vulnerable to downstream task-agnostic backdoors, which reside in the pretrained models and can affect arbitrary downstream tasks. The state-of-the-art backdoor detection approaches cannot defend against task-agnostic backdoors since they hardly converge in reversing the backdoor triggers. To address this issue, we propose LMSanitator, a novel approach for detecting and removing task-agnostic backdoors on Transformer models. Instead of directly inversing the triggers, LMSanitator aims to inverse the predefined attack vectors (pretrained models' output when the input is embedded with triggers) of the task-agnostic backdoors, which achieves much better convergence performance and backdoor detection accuracy. LMSanitator further leverages prompt-tuning's property of freezing the pretrained model to perform accurate and fast output monitoring and input purging during the inference phase. Extensive experiments on multiple language models and NLP tasks illustrate the effectiveness of LMSanitator. For instance, LMSanitator achieves 92.8% backdoor detection accuracy on 960 models and decreases the attack success rate to less than 1% in most scenarios.