 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkyReels-V4: Multi-modal Video-Audio Generation, Inpainting and Editing model
Feb 26, 2026SkyReels V4 is a unified multi modal video foundation model for joint video audio generation, inpainting, and editing. The model adopts a dual stream Multimodal Diffusion Transformer (MMDiT) architecture, where one branch synthesizes video and the other generates temporally aligned audio, while sharing a powerful text encoder based on the Multimodal Large Language Models (MMLM). SkyReels V4 accepts rich multi modal instructions, including text, images, video clips, masks, and audio references. By combining the MMLMs multi modal instruction following capability with in context learning in the video branch MMDiT, the model can inject fine grained visual guidance under complex conditioning, while the audio branch MMDiT simultaneously leverages audio references to guide sound generation. On the video side, we adopt a channel concatenation formulation that unifies a wide range of inpainting style tasks, such as image to video, video extension, and video editing under a single interface, and naturally extends to vision referenced inpainting and editing via multi modal prompts. SkyReels V4 supports up to 1080p resolution, 32 FPS, and 15 second duration, enabling high fidelity, multi shot, cinema level video generation with synchronized audio. To make such high resolution, long-duration generation computationally feasible, we introduce an efficiency strategy: Joint generation of low resolution full sequences and high-resolution keyframes, followed by dedicated super-resolution and frame interpolation models. To our knowledge, SkyReels V4 is the first video foundation model that simultaneously supports multi-modal input, joint video audio generation, and a unified treatment of generation, inpainting, and editing, while maintaining strong efficiency and quality at cinematic resolutions and durations.
Towards Instance-wise Personalized Federated Learning via Semi-Implicit Bayesian Prompt Tuning
Aug 27, 2025Federated learning (FL) is a privacy-preserving machine learning paradigm that enables collaborative model training across multiple distributed clients without disclosing their raw data. Personalized federated learning (pFL) has gained increasing attention for its ability to address data heterogeneity. However, most existing pFL methods assume that each client's data follows a single distribution and learn one client-level personalized model for each client. This assumption often fails in practice, where a single client may possess data from multiple sources or domains, resulting in significant intra-client heterogeneity and suboptimal performance. To tackle this challenge, we propose pFedBayesPT, a fine-grained instance-wise pFL framework based on visual prompt tuning. Specifically, we formulate instance-wise prompt generation from a Bayesian perspective and model the prompt posterior as an implicit distribution to capture diverse visual semantics. We derive a variational training objective under the semi-implicit variational inference framework. Extensive experiments on benchmark datasets demonstrate that pFedBayesPT consistently outperforms existing pFL methods under both feature and label heterogeneity settings.
R.R.: Unveiling LLM Training Privacy through Recollection and Ranking
Feb 18, 2025



Large Language Models (LLMs) pose significant privacy risks, potentially leaking training data due to implicit memorization. Existing privacy attacks primarily focus on membership inference attacks (MIAs) or data extraction attacks, but reconstructing specific personally identifiable information (PII) in LLM's training data remains challenging. In this paper, we propose R.R. (Recollect and Rank), a novel two-step privacy stealing attack that enables attackers to reconstruct PII entities from scrubbed training data where the PII entities have been masked. In the first stage, we introduce a prompt paradigm named recollection, which instructs the LLM to repeat a masked text but fill in masks. Then we can use PII identifiers to extract recollected PII candidates. In the second stage, we design a new criterion to score each PII candidate and rank them. Motivated by membership inference, we leverage the reference model as a calibration to our criterion. Experiments across three popular PII datasets demonstrate that the R.R. achieves better PII identical performance compared to baselines. These results highlight the vulnerability of LLMs to PII leakage even when training data has been scrubbed. We release the replicate package of R.R. at a link.
ScaleOT: Privacy-utility-scalable Offsite-tuning with Dynamic LayerReplace and Selective Rank Compression
Dec 13, 2024Offsite-tuning is a privacy-preserving method for tuning large language models (LLMs) by sharing a lossy compressed emulator from the LLM owners with data owners for downstream task tuning. This approach protects the privacy of both the model and data owners. However, current offsite tuning methods often suffer from adaptation degradation, high computational costs, and limited protection strength due to uniformly dropping LLM layers or relying on expensive knowledge distillation. To address these issues, we propose ScaleOT, a novel privacy-utility-scalable offsite-tuning framework that effectively balances privacy and utility. ScaleOT introduces a novel layerwise lossy compression algorithm that uses reinforcement learning to obtain the importance of each layer. It employs lightweight networks, termed harmonizers, to replace the raw LLM layers. By combining important original LLM layers and harmonizers in different ratios, ScaleOT generates emulators tailored for optimal performance with various model scales for enhanced privacy protection. Additionally, we present a rank reduction method to further compress the original LLM layers, significantly enhancing privacy with negligible impact on utility. Comprehensive experiments show that ScaleOT can achieve nearly lossless offsite tuning performance compared with full fine-tuning while obtaining better model privacy.
Three-dimensional Morphological Reconstruction of Millimeter-Scale Soft Continuum Robots based on Dual-Stereo-Vision
Aug 06, 2024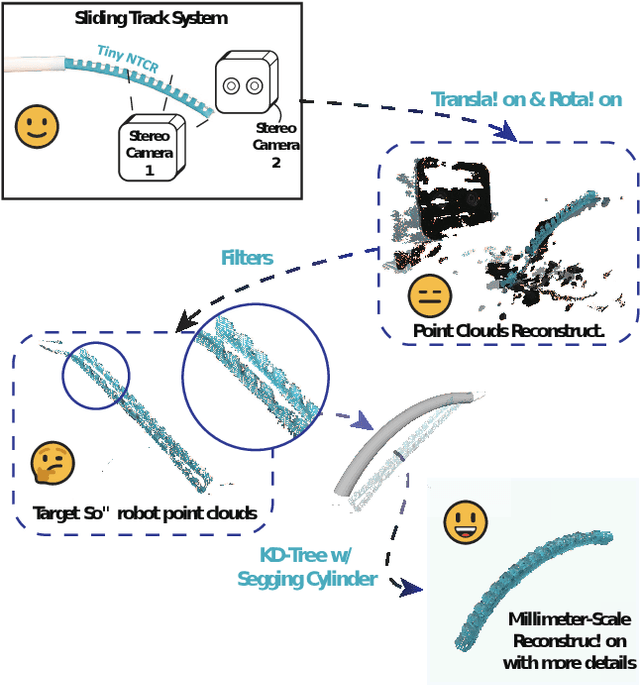
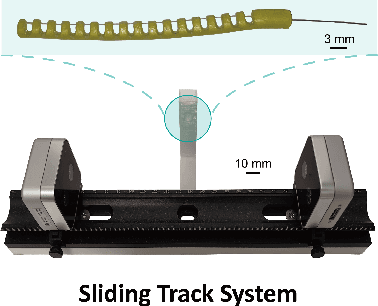

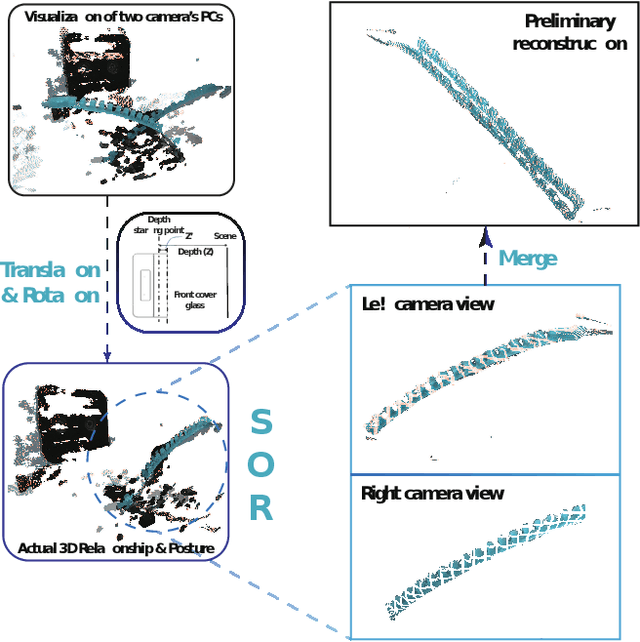
Continuum robots can be miniaturized to just a few millimeters in diameter. Among these, notched tubular continuum robots (NTCR) show great potential in many delicate applications. Existing works in robotic modeling focus on kinematics and dynamics but still face challenges in reproducing the robot's morphology -- a significant factor that can expand the research landscape of continuum robots, especially for those with asymmetric continuum structures. This paper proposes a dual stereo vision-based method for the three-dimensional morphological reconstruction of millimeter-scale NTCRs. The method employs two oppositely located stationary binocular cameras to capture the point cloud of the NTCR, then utilizes predefined geometry as a reference for the KD tree method to relocate the capture point clouds, resulting in a morphologically correct NTCR despite the low-quality raw point cloud collection. The method has been proved feasible for an NTCR with a 3.5 mm diameter, capturing 14 out of 16 notch features, with the measurements generally centered around the standard of 1.5 mm, demonstrating the capability of revealing morphological details. Our proposed method paves the way for 3D morphological reconstruction of millimeter-scale soft robots for further self-modeling study.
Fine-Tuning Gemma-7B for Enhanced Sentiment Analysis of Financial News Headlines
Jun 19, 2024
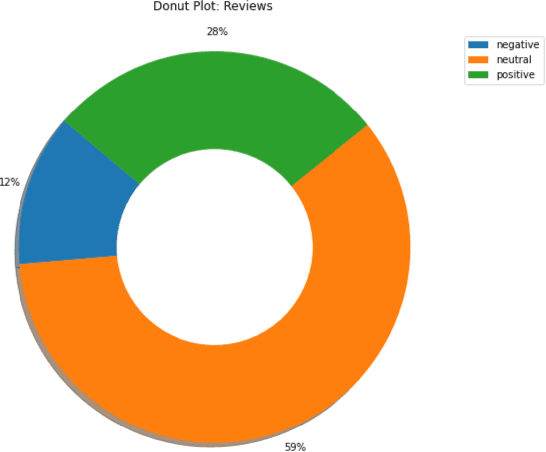
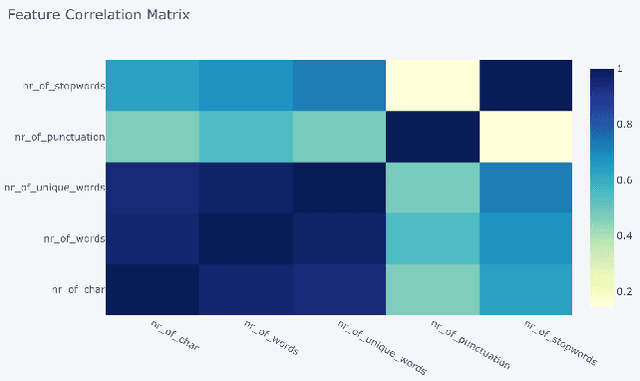
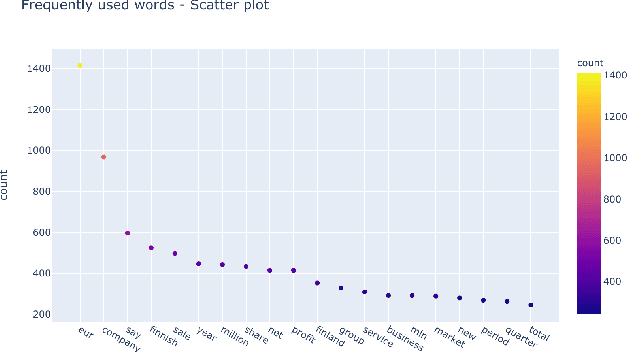
In this study, we explore the application of sentiment analysis on financial news headlines to understand investor sentiment. By leveraging Natural Language Processing (NLP) and Large Language Models (LLM), we analyze sentiment from the perspective of retail investors. The FinancialPhraseBank dataset, which contains categorized sentiments of financial news headlines, serves as the basis for our analysis. We fine-tuned several models, including distilbert-base-uncased, Llama, and gemma-7b, to evaluate their effectiveness in sentiment classification. Our experiments demonstrate that the fine-tuned gemma-7b model outperforms others, achieving the highest precision, recall, and F1 score. Specifically, the gemma-7b model showed significant improvements in accuracy after fine-tuning, indicating its robustness in capturing the nuances of financial sentiment. This model can be instrumental in providing market insights, risk management, and aiding investment decisions by accurately predicting the sentiment of financial news. The results highlight the potential of advanced LLMs in transforming how we analyze and interpret financial information, offering a powerful tool for stakeholders in the financial industry.
Forgetting Fast in Recommender Systems
Aug 14, 2022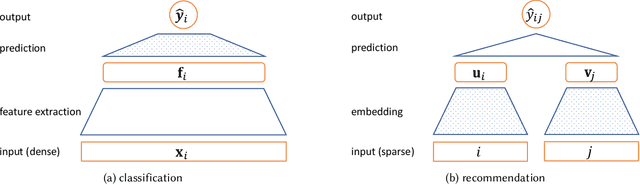


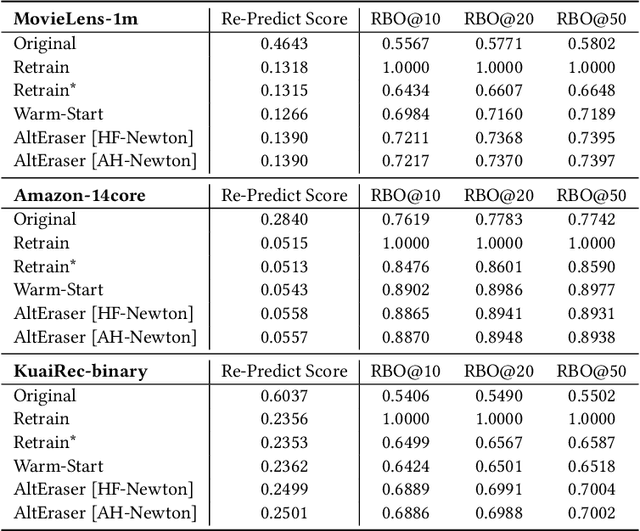
Users of a recommender system may want part of their data being deleted, not only from the data repository but also from the underlying machine learning model, for privacy or utility reasons. Such right-to-be-forgotten requests could be fulfilled by simply retraining the recommendation model from scratch, but that would be too slow and too expensive in practice. In this paper, we investigate fast machine unlearning techniques for recommender systems that can remove the effect of a small amount of training data from the recommendation model without incurring the full cost of retraining. A natural idea to speed this process up is to fine-tune the current recommendation model on the remaining training data instead of starting from a random initialization. This warm-start strategy indeed works for neural recommendation models using standard 1st-order neural network optimizers (like AdamW). However, we have found that even greater acceleration could be achieved by employing 2nd-order (Newton or quasi-Newton) optimization methods instead. To overcome the prohibitively high computational cost of 2nd-order optimizers, we propose a new recommendation unlearning approach AltEraser which divides the optimization problem of unlearning into many small tractable sub-problems. Extensive experiments on three real-world recommendation datasets show promising results of AltEraser in terms of consistency (forgetting thoroughness), accuracy (recommendation effectiveness), and efficiency (unlearning speed). To our knowledge, this work represents the first attempt at fast approximate machine unlearning for state-of-the-art neural recommendation models.
Obtaining Dyadic Fairness by Optimal Transport
Feb 09, 2022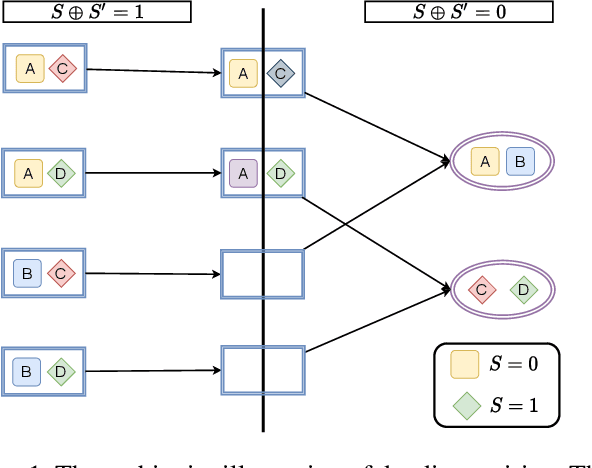
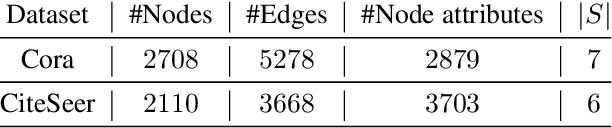
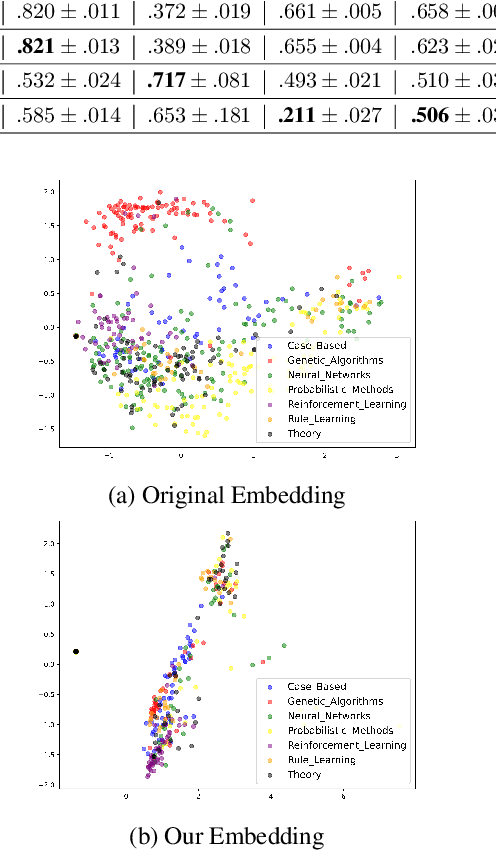
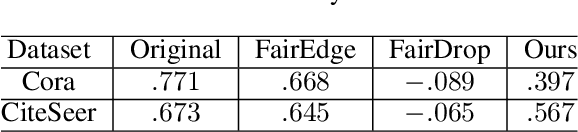
Fairness has been taken as a critical metric on machine learning models. Many works studying how to obtain fairness for different tasks emerge. This paper considers obtaining fairness for link prediction tasks, which can be measured by dyadic fairness. We aim to propose a pre-processing methodology to obtain dyadic fairness through data repairing and optimal transport. To obtain dyadic fairness with satisfying flexibility and unambiguity requirements, we transform the dyadic repairing to the conditional distribution alignment problem based on optimal transport and obtain theoretical results on the connection between the proposed alignment and dyadic fairness. The optimal transport-based dyadic fairness algorithm is proposed for graph link prediction. Our proposed algorithm shows superior results on obtaining fairness compared with the other pre-processing methods on two benchmark graph datasets.