 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForgetting Fast in Recommender Systems
Aug 14, 2022


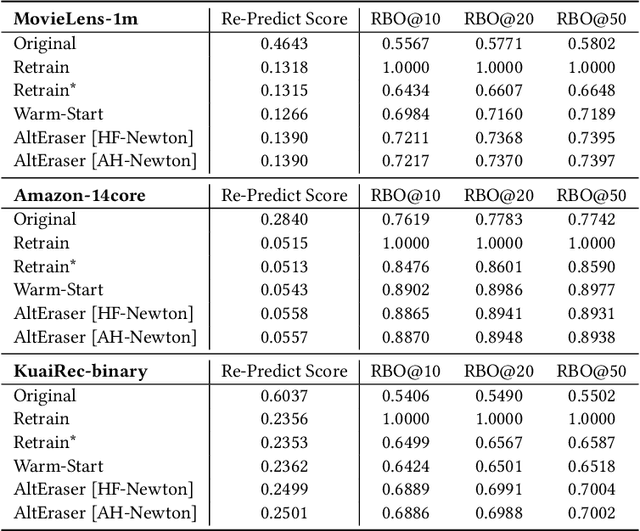
Users of a recommender system may want part of their data being deleted, not only from the data repository but also from the underlying machine learning model, for privacy or utility reasons. Such right-to-be-forgotten requests could be fulfilled by simply retraining the recommendation model from scratch, but that would be too slow and too expensive in practice. In this paper, we investigate fast machine unlearning techniques for recommender systems that can remove the effect of a small amount of training data from the recommendation model without incurring the full cost of retraining. A natural idea to speed this process up is to fine-tune the current recommendation model on the remaining training data instead of starting from a random initialization. This warm-start strategy indeed works for neural recommendation models using standard 1st-order neural network optimizers (like AdamW). However, we have found that even greater acceleration could be achieved by employing 2nd-order (Newton or quasi-Newton) optimization methods instead. To overcome the prohibitively high computational cost of 2nd-order optimizers, we propose a new recommendation unlearning approach AltEraser which divides the optimization problem of unlearning into many small tractable sub-problems. Extensive experiments on three real-world recommendation datasets show promising results of AltEraser in terms of consistency (forgetting thoroughness), accuracy (recommendation effectiveness), and efficiency (unlearning speed). To our knowledge, this work represents the first attempt at fast approximate machine unlearning for state-of-the-art neural recommendation models.
Phrase-level Adversarial Example Generation for Neural Machine Translation
Jan 06, 2022
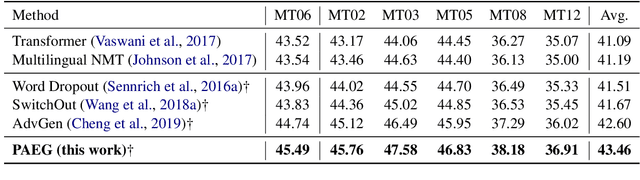


While end-to-end neural machine translation (NMT) has achieved impressive progress, noisy input usually leads models to become fragile and unstable. Generating adversarial examples as the augmented data is proved to be useful to alleviate this problem. Existing methods for adversarial example generation (AEG) are word-level or character-level. In this paper, we propose a phrase-level adversarial example generation (PAEG) method to enhance the robustness of the model. Our method leverages a gradient-based strategy to substitute phrases of vulnerable positions in the source input. We verify our method on three benchmarks, including LDC Chinese-English, IWSLT14 German-English, and WMT14 English-German tasks. Experimental results demonstrate that our approach significantly improves performance compared to previous methods.
Triple-to-Text: Converting RDF Triples into High-Quality Natural Languages via Optimizing an Inverse KL Divergence
May 25, 2019

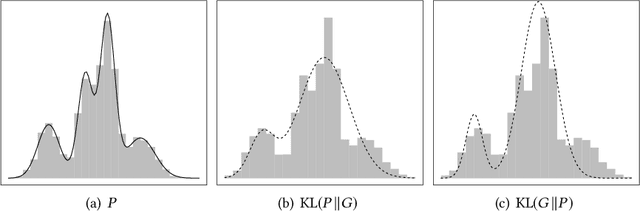

Knowledge base is one of the main forms to represent information in a structured way. A knowledge base typically consists of Resource Description Frameworks (RDF) triples which describe the entities and their relations. Generating natural language description of the knowledge base is an important task in NLP, which has been formulated as a conditional language generation task and tackled using the sequence-to-sequence framework. Current works mostly train the language models by maximum likelihood estimation, which tends to generate lousy sentences. In this paper, we argue that such a problem of maximum likelihood estimation is intrinsic, which is generally irrevocable via changing network structures. Accordingly, we propose a novel Triple-to-Text (T2T) framework, which approximately optimizes the inverse Kullback-Leibler (KL) divergence between the distributions of the real and generated sentences. Due to the nature that inverse KL imposes large penalty on fake-looking samples, the proposed method can significantly reduce the probability of generating low-quality sentences. Our experiments on three real-world datasets demonstrate that T2T can generate higher-quality sentences and outperform baseline models in several evaluation metrics.