 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOS-Genesis: Automating GUI Agent Trajectory Construction via Reverse Task Synthesis
Dec 27, 2024



Graphical User Interface (GUI) agents powered by Vision-Language Models (VLMs) have demonstrated human-like computer control capability. Despite their utility in advancing digital automation, a critical bottleneck persists: collecting high-quality trajectory data for training. Common practices for collecting such data rely on human supervision or synthetic data generation through executing pre-defined tasks, which are either resource-intensive or unable to guarantee data quality. Moreover, these methods suffer from limited data diversity and significant gaps between synthetic data and real-world environments. To address these challenges, we propose OS-Genesis, a novel GUI data synthesis pipeline that reverses the conventional trajectory collection process. Instead of relying on pre-defined tasks, OS-Genesis enables agents first to perceive environments and perform step-wise interactions, then retrospectively derive high-quality tasks to enable trajectory-level exploration. A trajectory reward model is then employed to ensure the quality of the generated trajectories. We demonstrate that training GUI agents with OS-Genesis significantly improves their performance on highly challenging online benchmarks. In-depth analysis further validates OS-Genesis's efficiency and its superior data quality and diversity compared to existing synthesis methods. Our codes, data, and checkpoints are available at \href{https://qiushisun.github.io/OS-Genesis-Home/}{OS-Genesis Homepage}.
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
Oct 30, 2024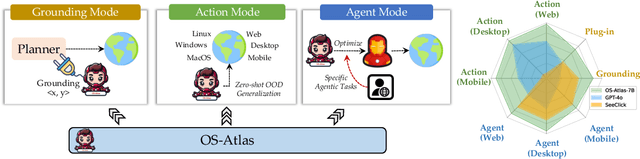
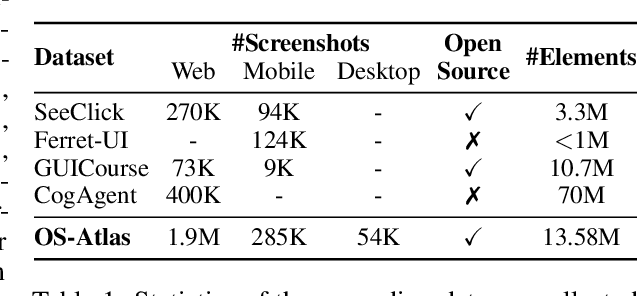
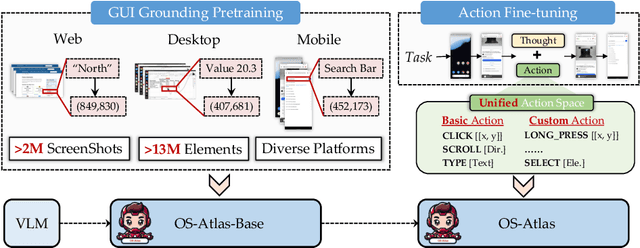
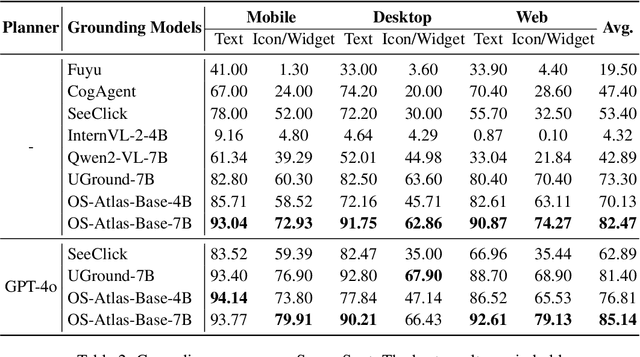
Existing efforts in building GUI agents heavily rely on the availability of robust commercial Vision-Language Models (VLMs) such as GPT-4o and GeminiProVision. Practitioners are often reluctant to use open-source VLMs due to their significant performance lag compared to their closed-source counterparts, particularly in GUI grounding and Out-Of-Distribution (OOD) scenarios. To facilitate future research in this area, we developed OS-Atlas - a foundational GUI action model that excels at GUI grounding and OOD agentic tasks through innovations in both data and modeling. We have invested significant engineering effort in developing an open-source toolkit for synthesizing GUI grounding data across multiple platforms, including Windows, Linux, MacOS, Android, and the web. Leveraging this toolkit, we are releasing the largest open-source cross-platform GUI grounding corpus to date, which contains over 13 million GUI elements. This dataset, combined with innovations in model training, provides a solid foundation for OS-Atlas to understand GUI screenshots and generalize to unseen interfaces. Through extensive evaluation across six benchmarks spanning three different platforms (mobile, desktop, and web), OS-Atlas demonstrates significant performance improvements over previous state-of-the-art models. Our evaluation also uncovers valuable insights into continuously improving and scaling the agentic capabilities of open-source VLMs.
MoS: Unleashing Parameter Efficiency of Low-Rank Adaptation with Mixture of Shards
Oct 01, 2024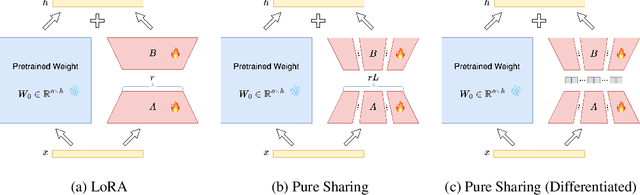

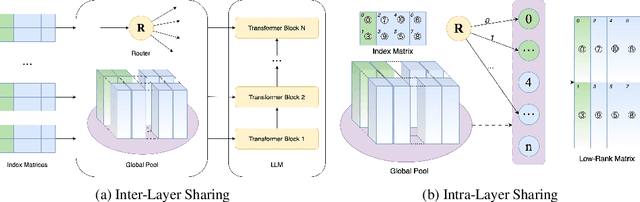
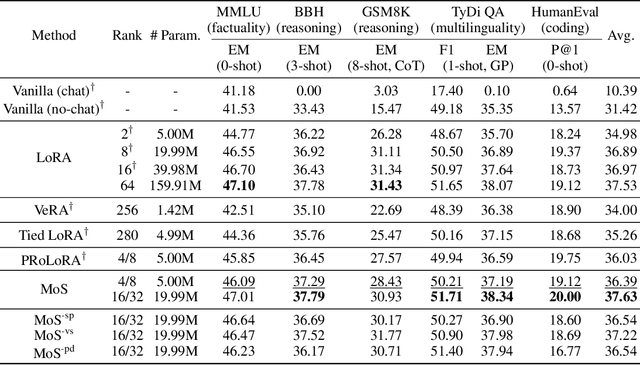
The rapid scaling of large language models necessitates more lightweight finetuning methods to reduce the explosive GPU memory overhead when numerous customized models are served simultaneously. Targeting more parameter-efficient low-rank adaptation (LoRA), parameter sharing presents a promising solution. Empirically, our research into high-level sharing principles highlights the indispensable role of differentiation in reversing the detrimental effects of pure sharing. Guided by this finding, we propose Mixture of Shards (MoS), incorporating both inter-layer and intra-layer sharing schemes, and integrating four nearly cost-free differentiation strategies, namely subset selection, pair dissociation, vector sharding, and shard privatization. Briefly, it selects a designated number of shards from global pools with a Mixture-of-Experts (MoE)-like routing mechanism before sequentially concatenating them to low-rank matrices. Hence, it retains all the advantages of LoRA while offering enhanced parameter efficiency, and effectively circumvents the drawbacks of peer parameter-sharing methods. Our empirical experiments demonstrate approximately 8x parameter savings in a standard LoRA setting. The ablation study confirms the significance of each component. Our insights into parameter sharing and MoS method may illuminate future developments of more parameter-efficient finetuning methods.
How Far Can Cantonese NLP Go? Benchmarking Cantonese Capabilities of Large Language Models
Aug 29, 2024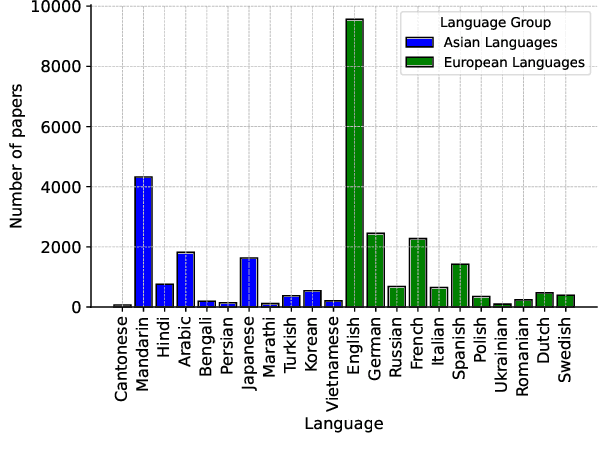
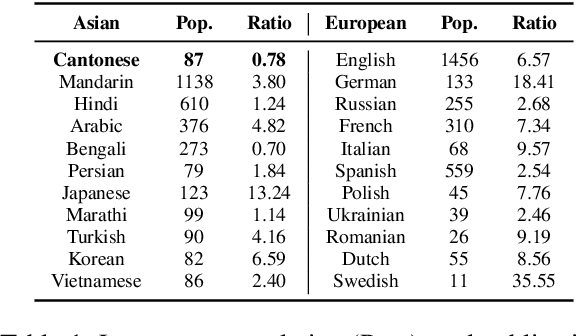
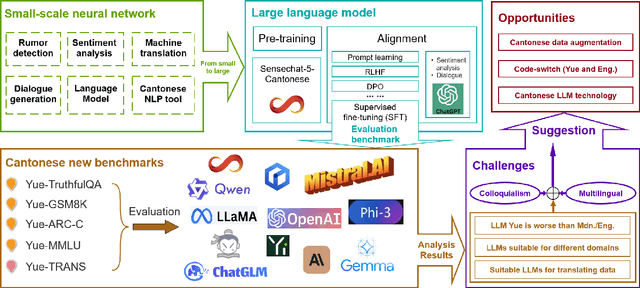
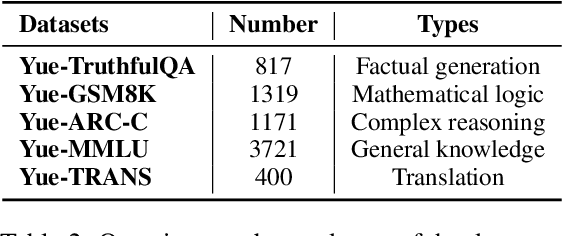
The rapid evolution of large language models (LLMs) has transformed the competitive landscape in natural language processing (NLP), particularly for English and other data-rich languages. However, underrepresented languages like Cantonese, spoken by over 85 million people, face significant development gaps, which is particularly concerning given the economic significance of the Guangdong-Hong Kong-Macau Greater Bay Area, and in substantial Cantonese-speaking populations in places like Singapore and North America. Despite its wide use, Cantonese has scant representation in NLP research, especially compared to other languages from similarly developed regions. To bridge these gaps, we outline current Cantonese NLP methods and introduce new benchmarks designed to evaluate LLM performance in factual generation, mathematical logic, complex reasoning, and general knowledge in Cantonese, which aim to advance open-source Cantonese LLM technology. We also propose future research directions and recommended models to enhance Cantonese LLM development.
Data Augmentation of Multi-turn Psychological Dialogue via Knowledge-driven Progressive Thought Prompting
Jun 24, 2024Existing dialogue data augmentation (DA) techniques predominantly focus on augmenting utterance-level dialogues, which makes it difficult to take dialogue contextual information into account. The advent of large language models (LLMs) has simplified the implementation of multi-turn dialogues. Due to absence of professional understanding and knowledge, it remains challenging to deliver satisfactory performance in low-resource domain, like psychological dialogue dialogue. DA involves creating new training or prompting data based on the existing data, which help the model better understand and generate psychology-related responses. In this paper, we aim to address the issue of multi-turn dialogue data augmentation for boosted performance in the psychology domain. We propose a knowledge-driven progressive thought prompting method to guide LLM to generate multi-turn psychology-related dialogue. This method integrates a progressive thought generator, a psychology knowledge generator, and a multi-turn dialogue generator. The thought generated by the progressive thought generator serves as a prompt to prevent the generated dialogue from having significant semantic deviations, while the psychology knowledge generator produces psychological knowledge to serve as the dialogue history for the LLM, guiding the dialogue generator to create multi-turn psychological dialogue. To ensure the precision of multi-turn psychological dialogue generation by LLM, a meticulous professional evaluation is required. Extensive experiments conducted on three datasets related to psychological dialogue verify the effectiveness of the proposed method.
LoRA Meets Dropout under a Unified Framework
Feb 25, 2024With the remarkable capabilities, large language models (LLMs) have emerged as essential elements in numerous NLP applications, while parameter-efficient finetuning, especially LoRA, has gained popularity as a lightweight approach for model customization. Meanwhile, various dropout methods, initially designed for full finetuning with all the parameters updated, alleviates overfitting associated with excessive parameter redundancy. Hence, a possible contradiction arises from negligible trainable parameters of LoRA and the effectiveness of previous dropout methods, which has been largely overlooked. To fill this gap, we first confirm that parameter-efficient LoRA is also overfitting-prone. We then revisit transformer-specific dropout methods, and establish their equivalence and distinctions mathematically and empirically. Building upon this comparative analysis, we introduce a unified framework for a comprehensive investigation, which instantiates these methods based on dropping position, structural pattern and compensation measure. Through this framework, we reveal the new preferences and performance comparisons of them when involved with limited trainable parameters. This framework also allows us to amalgamate the most favorable aspects into a novel dropout method named HiddenKey. Extensive experiments verify the remarkable superiority and sufficiency of HiddenKey across multiple models and tasks, which highlights it as the preferred approach for high-performance and parameter-efficient finetuning of LLMs.
PRoLoRA: Partial Rotation Empowers More Parameter-Efficient LoRA
Feb 24, 2024



With the rapid scaling of large language models (LLMs), serving numerous LoRAs concurrently has become increasingly impractical, leading to unaffordable costs and necessitating more parameter-efficient finetuning methods. In this work, we introduce Partially Rotation-enhanced Low-Rank Adaptation (PRoLoRA), an intra-layer sharing mechanism comprising four essential components: broadcast reduction, rotation enhancement, partially-sharing refinement, and rectified initialization strategy. As a superset of LoRA, PRoLoRA pertains its advantages, and effectively circumvent the drawbacks of peer parameter-sharing methods with superior model capacity, practical feasibility, and broad applicability. Empirical experiments demonstrate the remarkably higher parameter efficiency of PRoLoRA in both specific parameter budget and performance target scenarios, and its scalability to larger LLMs. Notably, with one time less trainable parameters, PRoLoRA still outperforms LoRA on multiple instruction tuning datasets. Subsequently, an ablation study is conducted to validate the necessity of individual components and highlight the superiority of PRoLoRA over three potential variants. Hopefully, the conspicuously higher parameter efficiency can establish PRoLoRA as a resource-friendly alternative to LoRA.
Diffusion of Thoughts: Chain-of-Thought Reasoning in Diffusion Language Models
Feb 12, 2024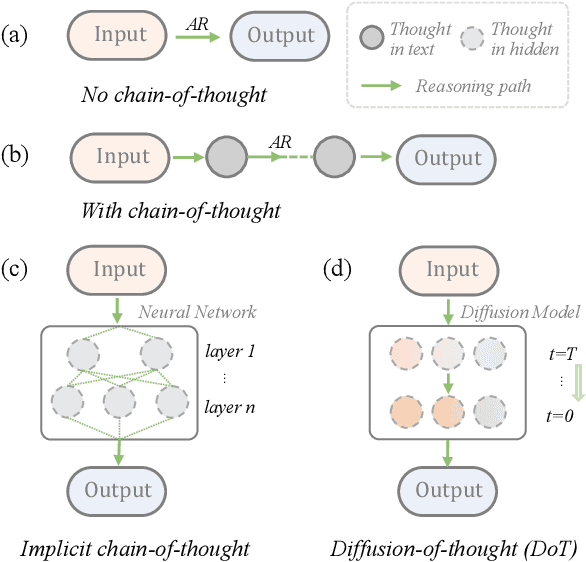
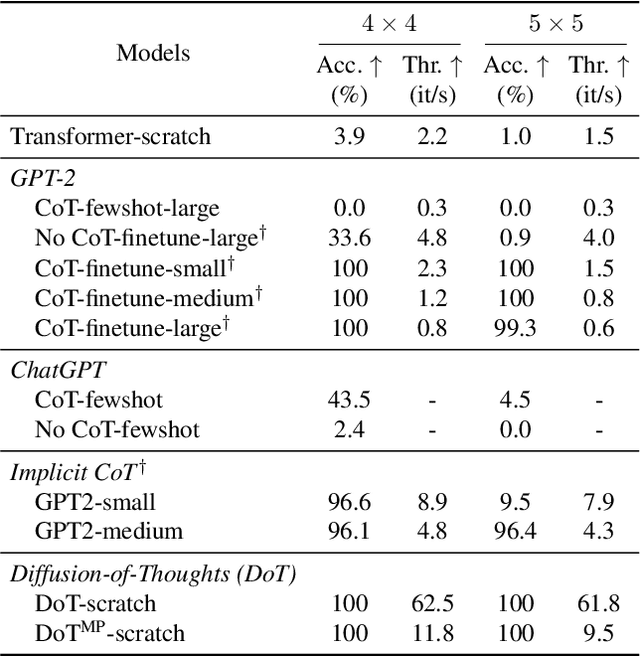
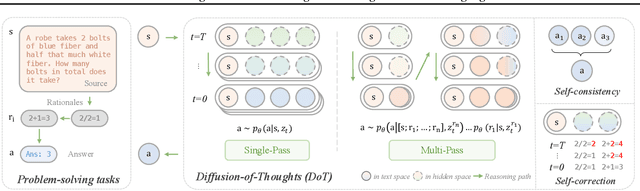
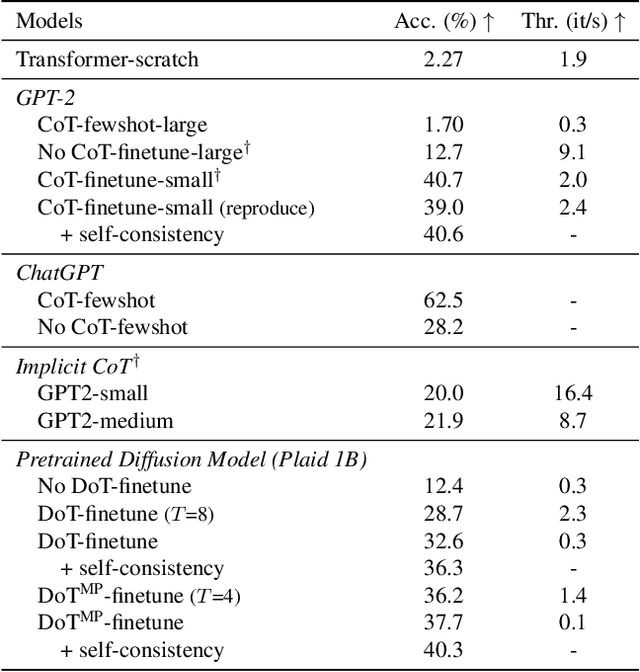
Diffusion models have gained attention in text processing, offering many potential advantages over traditional autoregressive models. This work explores the integration of diffusion models and Chain-of-Thought (CoT), a well-established technique to improve the reasoning ability in autoregressive language models. We propose Diffusion-of-Thought (DoT), allowing reasoning steps to diffuse over time through the diffusion process. In contrast to traditional autoregressive language models that make decisions in a left-to-right, token-by-token manner, DoT offers more flexibility in the trade-off between computation and reasoning performance. Our experimental results demonstrate the effectiveness of DoT in multi-digit multiplication and grade school math problems. Additionally, DoT showcases promising self-correction abilities and benefits from existing reasoning-enhancing techniques like self-consistency decoding. Our findings contribute to the understanding and development of reasoning capabilities in diffusion language models.
Multi-Agent Determinantal Q-Learning
Jun 09, 2020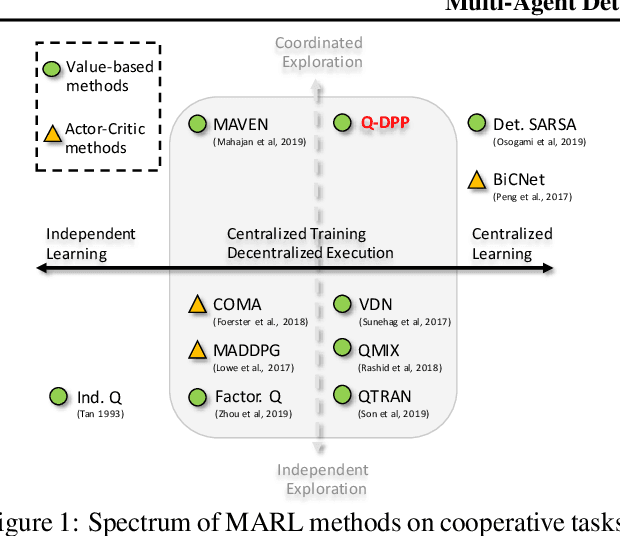
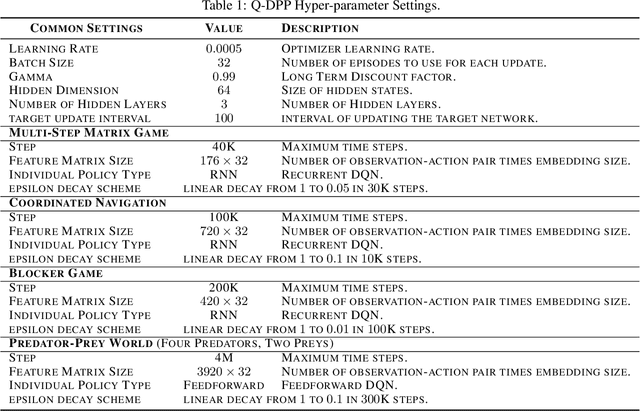
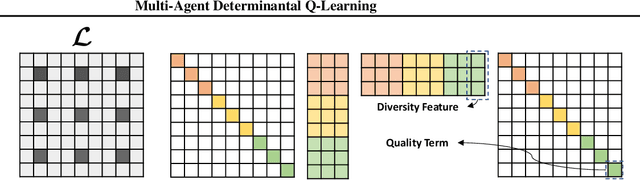
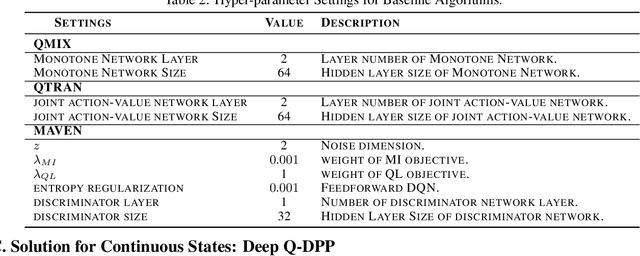
Centralized training with decentralized execution has become an important paradigm in multi-agent learning. Though practical, current methods rely on restrictive assumptions to decompose the centralized value function across agents for execution. In this paper, we eliminate this restriction by proposing multi-agent determinantal Q-learning. Our method is established on Q-DPP, an extension of determinantal point process (DPP) with partition-matroid constraint to multi-agent setting. Q-DPP promotes agents to acquire diverse behavioral models; this allows a natural factorization of the joint Q-functions with no need for \emph{a priori} structural constraints on the value function or special network architectures. We demonstrate that Q-DPP generalizes major solutions including VDN, QMIX, and QTRAN on decentralizable cooperative tasks. To efficiently draw samples from Q-DPP, we adopt an existing sample-by-projection sampler with theoretical approximation guarantee. The sampler also benefits exploration by coordinating agents to cover orthogonal directions in the state space during multi-agent training. We evaluate our algorithm on various cooperative benchmarks; its effectiveness has been demonstrated when compared with the state-of-the-art.
Signal Instructed Coordination in Team Competition
Sep 10, 2019



Most existing models of multi-agent reinforcement learning (MARL) adopt centralized training with decentralized execution framework. We demonstrate that the decentralized execution scheme restricts agents' capacity to find a better joint policy in team competition games, where each team of agents share the common rewards and cooperate to compete against other teams. To resolve this problem, we propose Signal Instructed Coordination (SIC), a novel coordination module that can be integrated with most existing models. SIC casts a common signal sampled from a pre-defined distribution to team members, and adopts an information-theoretic regularization to encourage agents to exploit in learning the instruction of centralized signals. Our experiments show that SIC can consistently improve team performance over well-recognized MARL models on matrix games and predator-prey games.