 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombating Pattern and Content Bias: Adversarial Feature Learning for Generalized AI-Generated Image Detection
Apr 14, 2026In recent years, the rapid development of generative artificial intelligence technology has significantly lowered the barrier to creating high-quality fake images, posing a serious challenge to information authenticity and credibility. Existing generated image detection methods typically enhance generalization through model architecture or network design. However, their generalization performance remains susceptible to data bias, as the training data may drive models to fit specific generative patterns and content rather than the common features shared by images from different generative models (asymmetric bias learning). To address this issue, we propose a Multi-dimensional Adversarial Feature Learning (MAFL) framework. The framework adopts a pretrained multimodal image encoder as the feature extraction backbone, constructs a real-fake feature learning network, and designs an adversarial bias-learning branch equipped with a multi-dimensional adversarial loss, forming an adversarial training mechanism between authenticity-discriminative feature learning and bias feature learning. By suppressing generation-pattern and content biases, MAFL guides the model to focus on the generative features shared across different generative models, thereby effectively capturing the fundamental differences between real and generated images, enhancing cross-model generalization, and substantially reducing the reliance on large-scale training data. Through extensive experimental validation, our method outperforms existing state-of-the-art approaches by 10.89% in accuracy and 8.57% in Average Precision (AP). Notably, even when trained with only 320 images, it can still achieve over 80% detection accuracy on public datasets.
Swimming Under Constraints: A Safe Reinforcement Learning Framework for Quadrupedal Bio-Inspired Propulsion
Mar 04, 2026Bio-inspired aquatic propulsion offers high thrust and maneuverability but is prone to destabilizing forces such as lift fluctuations, which are further amplified by six-degree-of-freedom (6-DoF) fluid coupling. We formulate quadrupedal swimming as a constrained optimization problem that maximizes forward thrust while minimizing destabilizing fluctuations. Our proposed framework, Accelerated Constrained Proximal Policy Optimization with a PID-regulated Lagrange multiplier (ACPPO-PID), enforces constraints with a PID-regulated Lagrange multiplier, accelerates learning via conditional asymmetric clipping, and stabilizes updates through cycle-wise geometric aggregation. Initialized with imitation learning and refined through on-hardware towing-tank experiments, ACPPO-PID produces control policies that transfer effectively to quadrupedal free-swimming trials. Results demonstrate improved thrust efficiency, reduced destabilizing forces, and faster convergence compared with state-of-the-art baselines, underscoring the importance of constraint-aware safe RL for robust and generalizable bio-inspired locomotion in complex fluid environments.
Sim2Sea: Sim-to-Real Policy Transfer for Maritime Vessel Navigation in Congested Waters
Mar 04, 2026Autonomous navigation in congested maritime environments is a critical capability for a wide range of real-world applications. However, it remains an unresolved challenge due to complex vessel interactions and significant environmental uncertainties. Existing methods often fail in practical deployment due to a substantial sim-to-real gap, which stems from imprecise simulation, inadequate situational awareness, and unsafe exploration strategies. To address these, we propose \textbf{Sim2Sea}, a comprehensive framework designed to bridge simulation and real-world execution. Sim2Sea advances in three key aspects. First, we develop a GPU-accelerated parallel simulator for scalable and accurate maritime scenario simulation. Second, we design a dual-stream spatiotemporal policy that handles complex dynamics and multi-modal perception, augmented with a velocity-obstacle-guided action masking mechanism to ensure safe and efficient exploration. Finally, a targeted domain randomization scheme helps bridge the sim-to-real gap. Simulation results demonstrate that our method achieves faster convergence and safer trajectories than established baselines. In addition, our policy trained purely in simulation successfully transfers zero-shot to a 17-ton unmanned vessel operating in real-world congested waters. These results validate the effectiveness of Sim2Sea in achieving reliable sim-to-real transfer for practical autonomous maritime navigation.
$π$-StepNFT: Wider Space Needs Finer Steps in Online RL for Flow-based VLAs
Mar 02, 2026Flow-based vision-language-action (VLA) models excel in embodied control but suffer from intractable likelihoods during multi-step sampling, hindering online reinforcement learning. We propose \textbf{\textit{$\boldsymbolπ$-StepNFT}} (Step-wise Negative-aware Fine-Tuning), a critic-and-likelihood-free framework that requires only a single forward pass per optimization step and eliminates auxiliary value networks. We identify that wider exploration spaces necessitate finer-grained, step-wise guidance for alignment. Empirically, $π$-StepNFT unlocks latent potential on LIBERO with competitive few-shot robustness. Moreover, it achieves superior generalization on ManiSkill, outperforming value-based baselines in OOD scenarios by preventing overfitting to multimodal features. This property offers a scalable solution promising for complex real-world applications.
Diversity over Uniformity: Rethinking Representation in Generated Image Detection
Feb 28, 2026With the rapid advancement of generative models, generated image detection has become an important task in visual forensics. Although existing methods have achieved remarkable progress, they often rely, after training, on only a small subset of highly salient forgery cues, which limits their ability to generalize to unseen generative mechanisms. We argue that reliably generated image detection should not depend on a single decision path but should preserve multiple judgment perspectives, enabling the model to understand the differences between real and generated images from diverse viewpoints. Based on this idea, we propose an anti-feature-collapse learning framework that filters task-irrelevant components and suppresses excessive overlap among different forgery cues in the representation space, preventing discriminative information from collapsing into a few dominant feature directions. This design maintains diverse and complementary evidence within the model, reduces reliance on a small set of salient cues, and enhances robustness under unseen generative settings. Extensive experiments on multiple public benchmarks demonstrate that the proposed method significantly outperforms the state-of-the-art approaches in cross-model scenarios, achieving an accuracy improvement of 5.02% and exhibiting superior generalization and detection reliability. The source code is available at https://github.com/Yanmou-Hui/DoU.
Hardware Co-Design Scaling Laws via Roofline Modelling for On-Device LLMs
Feb 10, 2026Vision-Language-Action Models (VLAs) have emerged as a key paradigm of Physical AI and are increasingly deployed in autonomous vehicles, robots, and smart spaces. In these resource-constrained on-device settings, selecting an appropriate large language model (LLM) backbone is a critical challenge: models must balance accuracy with strict inference latency and hardware efficiency constraints. This makes hardware-software co-design a game-changing requirement for on-device LLM deployment, where each hardware platform demands a tailored architectural solution. We propose a hardware co-design law that jointly captures model accuracy and inference performance. Specifically, we model training loss as an explicit function of architectural hyperparameters and characterise inference latency via roofline modelling. We empirically evaluate 1,942 candidate architectures on NVIDIA Jetson Orin, training 170 selected models for 10B tokens each to fit a scaling law relating architecture to training loss. By coupling this scaling law with latency modelling, we establish a direct accuracy-latency correspondence and identify the Pareto frontier for hardware co-designed LLMs. We further formulate architecture search as a joint optimisation over precision and performance, deriving feasible design regions under industrial hardware and application budgets. Our approach reduces architecture selection from months to days. At the same latency as Qwen2.5-0.5B on the target hardware, our co-designed architecture achieves 19.42% lower perplexity on WikiText-2. To our knowledge, this is the first principled and operational framework for hardware co-design scaling laws in on-device LLM deployment. We will make the code and related checkpoints publicly available.
ProcMEM: Learning Reusable Procedural Memory from Experience via Non-Parametric PPO for LLM Agents
Feb 02, 2026LLM-driven agents demonstrate strong performance in sequential decision-making but often rely on on-the-fly reasoning, re-deriving solutions even in recurring scenarios. This insufficient experience reuse leads to computational redundancy and execution instability. To bridge this gap, we propose ProcMEM, a framework that enables agents to autonomously learn procedural memory from interaction experiences without parameter updates. By formalizing a Skill-MDP, ProcMEM transforms passive episodic narratives into executable Skills defined by activation, execution, and termination conditions to ensure executability. To achieve reliable reusability without capability degradation, we introduce Non-Parametric PPO, which leverages semantic gradients for high-quality candidate generation and a PPO Gate for robust Skill verification. Through score-based maintenance, ProcMEM sustains compact, high-quality procedural memory. Experimental results across in-domain, cross-task, and cross-agent scenarios demonstrate that ProcMEM achieves superior reuse rates and significant performance gains with extreme memory compression. Visualized evolutionary trajectories and Skill distributions further reveal how ProcMEM transparently accumulates, refines, and reuses procedural knowledge to facilitate long-term autonomy.
Think, Speak, Decide: Language-Augmented Multi-Agent Reinforcement Learning for Economic Decision-Making
Nov 17, 2025



Economic decision-making depends not only on structured signals such as prices and taxes, but also on unstructured language, including peer dialogue and media narratives. While multi-agent reinforcement learning (MARL) has shown promise in optimizing economic decisions, it struggles with the semantic ambiguity and contextual richness of language. We propose LAMP (Language-Augmented Multi-Agent Policy), a framework that integrates language into economic decision-making and narrows the gap to real-world settings. LAMP follows a Think-Speak-Decide pipeline: (1) Think interprets numerical observations to extract short-term shocks and long-term trends, caching high-value reasoning trajectories; (2) Speak crafts and exchanges strategic messages based on reasoning, updating beliefs by parsing peer communications; and (3) Decide fuses numerical data, reasoning, and reflections into a MARL policy to optimize language-augmented decision-making. Experiments in economic simulation show that LAMP outperforms both MARL and LLM-only baselines in cumulative return (+63.5%, +34.0%), robustness (+18.8%, +59.4%), and interpretability. These results demonstrate the potential of language-augmented policies to deliver more effective and robust economic strategies.
From Experience to Strategy: Empowering LLM Agents with Trainable Graph Memory
Nov 11, 2025Large Language Models (LLMs) based agents have demonstrated remarkable potential in autonomous task-solving across complex, open-ended environments. A promising approach for improving the reasoning capabilities of LLM agents is to better utilize prior experiences in guiding current decisions. However, LLMs acquire experience either through implicit memory via training, which suffers from catastrophic forgetting and limited interpretability, or explicit memory via prompting, which lacks adaptability. In this paper, we introduce a novel agent-centric, trainable, multi-layered graph memory framework and evaluate how context memory enhances the ability of LLMs to utilize parametric information. The graph abstracts raw agent trajectories into structured decision paths in a state machine and further distills them into high-level, human-interpretable strategic meta-cognition. In order to make memory adaptable, we propose a reinforcement-based weight optimization procedure that estimates the empirical utility of each meta-cognition based on reward feedback from downstream tasks. These optimized strategies are then dynamically integrated into the LLM agent's training loop through meta-cognitive prompting. Empirically, the learnable graph memory delivers robust generalization, improves LLM agents' strategic reasoning performance, and provides consistent benefits during Reinforcement Learning (RL) training.
SpatialViz-Bench: Automatically Generated Spatial Visualization Reasoning Tasks for MLLMs
Jul 10, 2025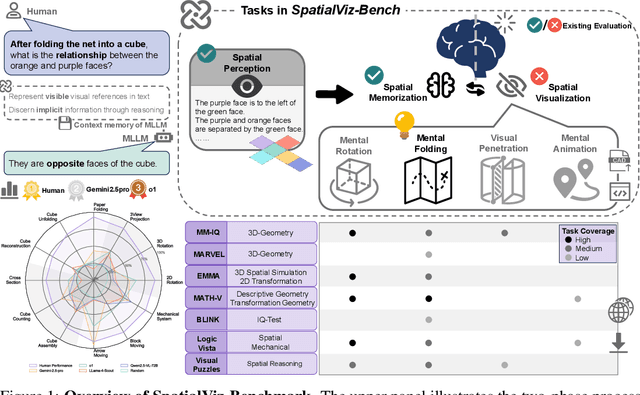
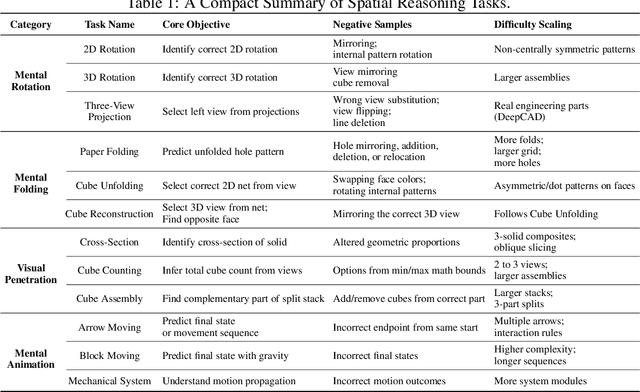

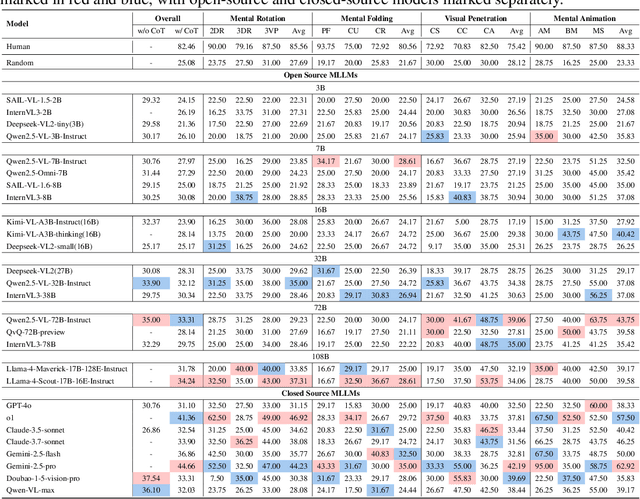
Humans can directly imagine and manipulate visual images in their minds, a capability known as spatial visualization. While multi-modal Large Language Models (MLLMs) support imagination-based reasoning, spatial visualization remains insufficiently evaluated, typically embedded within broader mathematical and logical assessments. Existing evaluations often rely on IQ tests or math competitions that may overlap with training data, compromising assessment reliability. To this end, we introduce SpatialViz-Bench, a comprehensive multi-modal benchmark for spatial visualization with 12 tasks across 4 sub-abilities, comprising 1,180 automatically generated problems. Our evaluation of 33 state-of-the-art MLLMs not only reveals wide performance variations and demonstrates the benchmark's strong discriminative power, but also uncovers counter-intuitive findings: models exhibit unexpected behaviors by showing difficulty perception that misaligns with human intuition, displaying dramatic 2D-to-3D performance cliffs, and defaulting to formula derivation despite spatial tasks requiring visualization alone. SpatialVizBench empirically demonstrates that state-of-the-art MLLMs continue to exhibit deficiencies in spatial visualization tasks, thereby addressing a significant lacuna in the field. The benchmark is publicly available.