 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLM: Efficient Peripheral Language Models Hardware-Co-Designed for Ubiquitous Computing
Mar 15, 2025

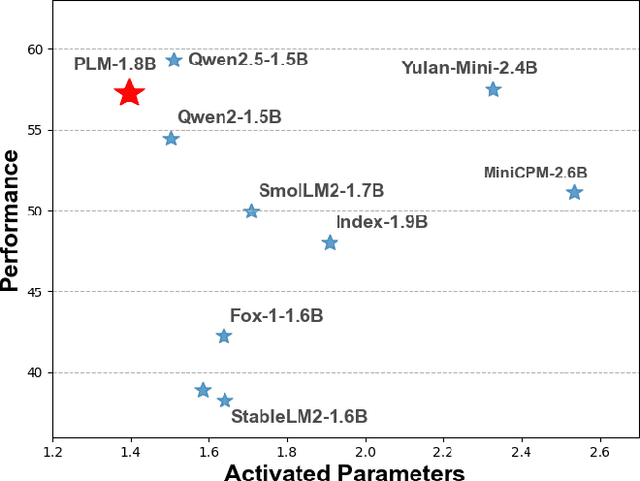

While scaling laws have been continuously validated in large language models (LLMs) with increasing model parameters, the inherent tension between the inference demands of LLMs and the limited resources of edge devices poses a critical challenge to the development of edge intelligence. Recently, numerous small language models have emerged, aiming to distill the capabilities of LLMs into smaller footprints. However, these models often retain the fundamental architectural principles of their larger counterparts, still imposing considerable strain on the storage and bandwidth capacities of edge devices. In this paper, we introduce the PLM, a Peripheral Language Model, developed through a co-design process that jointly optimizes model architecture and edge system constraints. The PLM utilizes a Multi-head Latent Attention mechanism and employs the squared ReLU activation function to encourage sparsity, thereby reducing peak memory footprint during inference. During training, we collect and reorganize open-source datasets, implement a multi-phase training strategy, and empirically investigate the Warmup-Stable-Decay-Constant (WSDC) learning rate scheduler. Additionally, we incorporate Reinforcement Learning from Human Feedback (RLHF) by adopting the ARIES preference learning approach. Following a two-phase SFT process, this method yields performance gains of 2% in general tasks, 9% in the GSM8K task, and 11% in coding tasks. In addition to its novel architecture, evaluation results demonstrate that PLM outperforms existing small language models trained on publicly available data while maintaining the lowest number of activated parameters. Furthermore, deployment across various edge devices, including consumer-grade GPUs, mobile phones, and Raspberry Pis, validates PLM's suitability for peripheral applications. The PLM series models are publicly available at https://github.com/plm-team/PLM.
Activation-aware Probe-Query: Effective Key-Value Retrieval for Long-Context LLMs Inference
Feb 19, 2025Recent advances in large language models (LLMs) have showcased exceptional performance in long-context tasks, while facing significant inference efficiency challenges with limited GPU memory. Existing solutions first proposed the sliding-window approach to accumulate a set of historical \textbf{key-value} (KV) pairs for reuse, then further improvements selectively retain its subsets at each step. However, due to the sparse attention distribution across a long context, it is hard to identify and recall relevant KV pairs, as the attention is distracted by massive candidate pairs. Additionally, we found it promising to select representative tokens as probe-Query in each sliding window to effectively represent the entire context, which is an approach overlooked by existing methods. Thus, we propose \textbf{ActQKV}, a training-free, \textbf{Act}ivation-aware approach that dynamically determines probe-\textbf{Q}uery and leverages it to retrieve the relevant \textbf{KV} pairs for inference. Specifically, ActQKV monitors a token-level indicator, Activation Bias, within each context window, enabling the proper construction of probe-Query for retrieval at pre-filling stage. To accurately recall the relevant KV pairs and minimize the irrelevant ones, we design a dynamic KV cut-off mechanism guided by information density across layers at the decoding stage. Experiments on the Long-Bench and $\infty$ Benchmarks demonstrate its state-of-the-art performance with competitive inference quality and resource efficiency.
Topic-DPR: Topic-based Prompts for Dense Passage Retrieval
Oct 10, 2023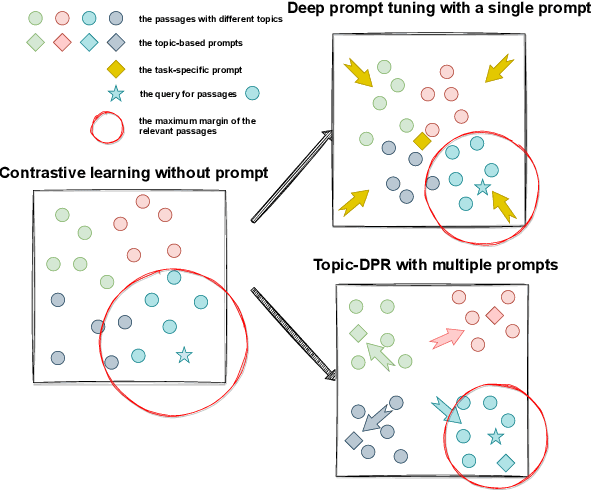
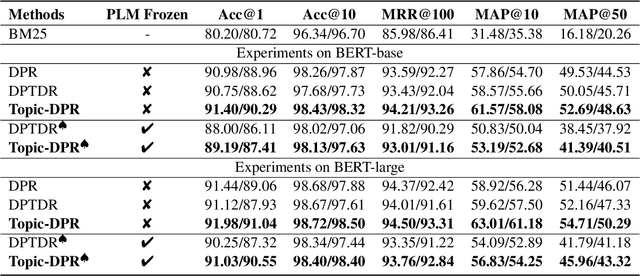
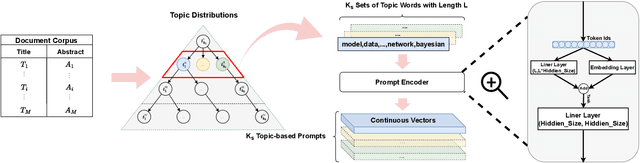
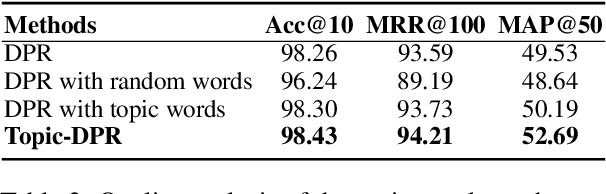
Prompt-based learning's efficacy across numerous natural language processing tasks has led to its integration into dense passage retrieval. Prior research has mainly focused on enhancing the semantic understanding of pre-trained language models by optimizing a single vector as a continuous prompt. This approach, however, leads to a semantic space collapse; identical semantic information seeps into all representations, causing their distributions to converge in a restricted region. This hinders differentiation between relevant and irrelevant passages during dense retrieval. To tackle this issue, we present Topic-DPR, a dense passage retrieval model that uses topic-based prompts. Unlike the single prompt method, multiple topic-based prompts are established over a probabilistic simplex and optimized simultaneously through contrastive learning. This encourages representations to align with their topic distributions, improving space uniformity. Furthermore, we introduce a novel positive and negative sampling strategy, leveraging semi-structured data to boost dense retrieval efficiency. Experimental results from two datasets affirm that our method surpasses previous state-of-the-art retrieval techniques.
Identical and Fraternal Twins: Fine-Grained Semantic Contrastive Learning of Sentence Representations
Jul 20, 2023



The enhancement of unsupervised learning of sentence representations has been significantly achieved by the utility of contrastive learning. This approach clusters the augmented positive instance with the anchor instance to create a desired embedding space. However, relying solely on the contrastive objective can result in sub-optimal outcomes due to its inability to differentiate subtle semantic variations between positive pairs. Specifically, common data augmentation techniques frequently introduce semantic distortion, leading to a semantic margin between the positive pair. While the InfoNCE loss function overlooks the semantic margin and prioritizes similarity maximization between positive pairs during training, leading to the insensitive semantic comprehension ability of the trained model. In this paper, we introduce a novel Identical and Fraternal Twins of Contrastive Learning (named IFTCL) framework, capable of simultaneously adapting to various positive pairs generated by different augmentation techniques. We propose a \textit{Twins Loss} to preserve the innate margin during training and promote the potential of data enhancement in order to overcome the sub-optimal issue. We also present proof-of-concept experiments combined with the contrastive objective to prove the validity of the proposed Twins Loss. Furthermore, we propose a hippocampus queue mechanism to restore and reuse the negative instances without additional calculation, which further enhances the efficiency and performance of the IFCL. We verify the IFCL framework on nine semantic textual similarity tasks with both English and Chinese datasets, and the experimental results show that IFCL outperforms state-of-the-art methods.