 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLM: Efficient Peripheral Language Models Hardware-Co-Designed for Ubiquitous Computing
Mar 15, 2025

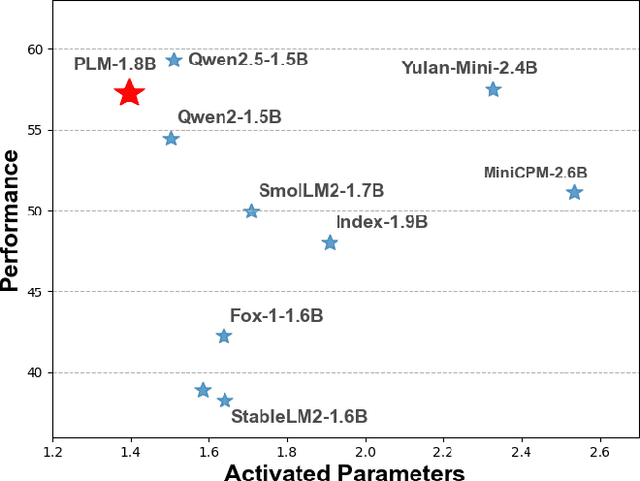

While scaling laws have been continuously validated in large language models (LLMs) with increasing model parameters, the inherent tension between the inference demands of LLMs and the limited resources of edge devices poses a critical challenge to the development of edge intelligence. Recently, numerous small language models have emerged, aiming to distill the capabilities of LLMs into smaller footprints. However, these models often retain the fundamental architectural principles of their larger counterparts, still imposing considerable strain on the storage and bandwidth capacities of edge devices. In this paper, we introduce the PLM, a Peripheral Language Model, developed through a co-design process that jointly optimizes model architecture and edge system constraints. The PLM utilizes a Multi-head Latent Attention mechanism and employs the squared ReLU activation function to encourage sparsity, thereby reducing peak memory footprint during inference. During training, we collect and reorganize open-source datasets, implement a multi-phase training strategy, and empirically investigate the Warmup-Stable-Decay-Constant (WSDC) learning rate scheduler. Additionally, we incorporate Reinforcement Learning from Human Feedback (RLHF) by adopting the ARIES preference learning approach. Following a two-phase SFT process, this method yields performance gains of 2% in general tasks, 9% in the GSM8K task, and 11% in coding tasks. In addition to its novel architecture, evaluation results demonstrate that PLM outperforms existing small language models trained on publicly available data while maintaining the lowest number of activated parameters. Furthermore, deployment across various edge devices, including consumer-grade GPUs, mobile phones, and Raspberry Pis, validates PLM's suitability for peripheral applications. The PLM series models are publicly available at https://github.com/plm-team/PLM.
WPS-SAM: Towards Weakly-Supervised Part Segmentation with Foundation Models
Jul 14, 2024



Segmenting and recognizing diverse object parts is crucial in computer vision and robotics. Despite significant progress in object segmentation, part-level segmentation remains underexplored due to complex boundaries and scarce annotated data. To address this, we propose a novel Weakly-supervised Part Segmentation (WPS) setting and an approach called WPS-SAM, built on the large-scale pre-trained vision foundation model, Segment Anything Model (SAM). WPS-SAM is an end-to-end framework designed to extract prompt tokens directly from images and perform pixel-level segmentation of part regions. During its training phase, it only uses weakly supervised labels in the form of bounding boxes or points. Extensive experiments demonstrate that, through exploiting the rich knowledge embedded in pre-trained foundation models, WPS-SAM outperforms other segmentation models trained with pixel-level strong annotations. Specifically, WPS-SAM achieves 68.93% mIOU and 79.53% mACC on the PartImageNet dataset, surpassing state-of-the-art fully supervised methods by approximately 4% in terms of mIOU.
D2O:Dynamic Discriminative Operations for Efficient Generative Inference of Large Language Models
Jun 18, 2024



Efficient inference in Large Language Models (LLMs) is impeded by the growing memory demands of key-value (KV) caching, especially for longer sequences. Traditional KV cache eviction strategies, which prioritize less critical KV-pairs based on attention scores, often degrade generation quality, leading to issues such as context loss or hallucinations. To address this, we introduce Dynamic Discriminative Operations (D2O), a novel method that utilizes two-level discriminative strategies to optimize KV cache size without fine-tuning, while preserving essential context. Initially, by observing varying densities of attention weights between shallow and deep layers, we use this insight to determine which layers should avoid excessive eviction to minimize information loss. Subsequently, for the eviction strategy in each layer, D2O innovatively incorporates a compensation mechanism that maintains a similarity threshold to re-discriminate the importance of previously discarded tokens, determining whether they should be recalled and merged with similar tokens. Our approach not only achieves significant memory savings and enhances inference throughput by more than 3x but also maintains high-quality long-text generation. Extensive experiments across various benchmarks and LLM architectures have demonstrated that D2O significantly enhances performance with a constrained KV cache budget.
PPT: Token Pruning and Pooling for Efficient Vision Transformers
Oct 03, 2023
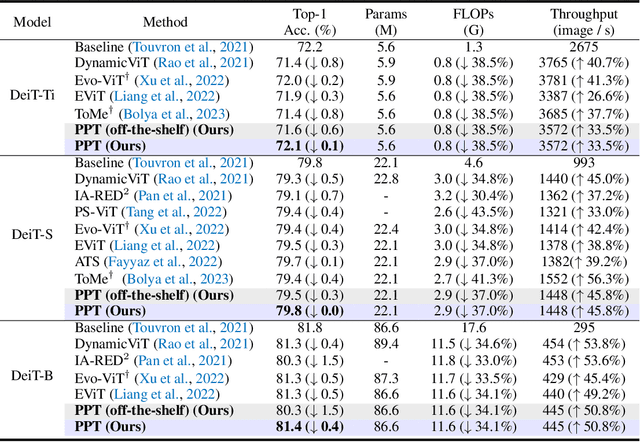


Vision Transformers (ViTs) have emerged as powerful models in the field of computer vision, delivering superior performance across various vision tasks. However, the high computational complexity poses a significant barrier to their practical applications in real-world scenarios. Motivated by the fact that not all tokens contribute equally to the final predictions and fewer tokens bring less computational cost, reducing redundant tokens has become a prevailing paradigm for accelerating vision transformers. However, we argue that it is not optimal to either only reduce inattentive redundancy by token pruning, or only reduce duplicative redundancy by token merging. To this end, in this paper we propose a novel acceleration framework, namely token Pruning & Pooling Transformers (PPT), to adaptively tackle these two types of redundancy in different layers. By heuristically integrating both token pruning and token pooling techniques in ViTs without additional trainable parameters, PPT effectively reduces the model complexity while maintaining its predictive accuracy. For example, PPT reduces over 37% FLOPs and improves the throughput by over 45% for DeiT-S without any accuracy drop on the ImageNet dataset.
Class Incremental Learning with Self-Supervised Pre-Training and Prototype Learning
Aug 04, 2023



Deep Neural Network (DNN) has achieved great success on datasets of closed class set. However, new classes, like new categories of social media topics, are continuously added to the real world, making it necessary to incrementally learn. This is hard for DNN because it tends to focus on fitting to new classes while ignoring old classes, a phenomenon known as catastrophic forgetting. State-of-the-art methods rely on knowledge distillation and data replay techniques but still have limitations. In this work, we analyze the causes of catastrophic forgetting in class incremental learning, which owes to three factors: representation drift, representation confusion, and classifier distortion. Based on this view, we propose a two-stage learning framework with a fixed encoder and an incrementally updated prototype classifier. The encoder is trained with self-supervised learning to generate a feature space with high intrinsic dimensionality, thus improving its transferability and generality. The classifier incrementally learns new prototypes while retaining the prototypes of previously learned data, which is crucial in preserving the decision boundary.Our method does not rely on preserved samples of old classes, is thus a non-exemplar based CIL method. Experiments on public datasets show that our method can significantly outperform state-of-the-art exemplar-based methods when they reserved 5 examplers per class, under the incremental setting of 10 phases, by 18.24% on CIFAR-100 and 9.37% on ImageNet100.