 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCL-VISTA: Benchmarking Continual Learning in Video Large Language Models
Apr 01, 2026Video Large Language Models (Video-LLMs) require continual learning to adapt to non-stationary real-world data. However, existing benchmarks fall short of evaluating modern foundation models: many still rely on models without large-scale pre-training, and prevailing benchmarks typically partition a single dataset into sub-tasks, resulting in high task redundancy and negligible forgetting on pre-trained Video-LLMs. To address these limitations, we propose CL-VISTA, a benchmark tailored for continual video understanding of Video-LLMs. By curating 8 diverse tasks spanning perception, understanding, and reasoning, CL-VISTA induces substantial distribution shifts that effectively expose catastrophic forgetting. To systematically assess CL methods, we establish a comprehensive evaluation framework comprising 6 distinct protocols across 3 critical dimensions: performance, computational efficiency, and memory footprint. Notably, the performance dimension incorporates a general video understanding assessment to assess whether CL methods genuinely enhance foundational intelligence or merely induce task-specific overfitting. Extensive benchmarking of 10 mainstream CL methods reveals a fundamental trade-off: no single approach achieves universal superiority across all dimensions. Methods that successfully mitigate catastrophic forgetting tend to compromise generalization or incur prohibitive computational and memory overheads. We hope CL-VISTA provides critical insights for advancing continual learning in multimodal foundation models.
Intent Mismatch Causes LLMs to Get Lost in Multi-Turn Conversation
Feb 07, 2026Multi-turn conversation has emerged as a predominant interaction paradigm for Large Language Models (LLMs). Users often employ follow-up questions to refine their intent, expecting LLMs to adapt dynamically. However, recent research reveals that LLMs suffer a substantial performance drop in multi-turn settings compared to single-turn interactions with fully specified instructions, a phenomenon termed ``Lost in Conversation'' (LiC). While this prior work attributes LiC to model unreliability, we argue that the root cause lies in an intent alignment gap rather than intrinsic capability deficits. In this paper, we first demonstrate that LiC is not a failure of model capability but rather a breakdown in interaction between users and LLMs. We theoretically show that scaling model size or improving training alone cannot resolve this gap, as it arises from structural ambiguity in conversational context rather than representational limitations. To address this, we propose to decouple intent understanding from task execution through a Mediator-Assistant architecture. By utilizing an experience-driven Mediator to explicate user inputs into explicit, well-structured instructions based on historical interaction patterns, our approach effectively bridges the gap between vague user intent and model interpretation. Experimental results demonstrate that this method significantly mitigates performance degradation in multi-turn conversations across diverse LLMs.
Self-Consolidation for Self-Evolving Agents
Feb 02, 2026While large language model (LLM) agents have demonstrated impressive problem-solving capabilities, they typically operate as static systems, lacking the ability to evolve through lifelong interaction. Existing attempts to bridge this gap primarily rely on retrieving successful past trajectories as demonstrations. However, this paradigm faces two critical limitations. First, by focusing solely on success, agents overlook the rich pedagogical value embedded in failed attempts, preventing them from identifying and avoiding recurrent pitfalls. Second, continually accumulating textual experiences not only increases the time consumption during retrieval but also inevitably introduces noise and exhausts the largest context window of current LLMs. To address these challenges, we propose a novel self-evolving framework for LLM agents that introduces a complementary evolution mechanism: First, a contrastive reflection strategy is introduced to explicitly summarize error-prone patterns and capture reusable insights. Second, we propose a self-consolidation mechanism that distills non-parametric textual experience into compact learnable parameters. This enables the agent to internalize extensive historical experience directly into its latent space. Extensive experiments demonstrate the advantages of our method in long-term agent evolution.
VTCBench: Can Vision-Language Models Understand Long Context with Vision-Text Compression?
Dec 23, 2025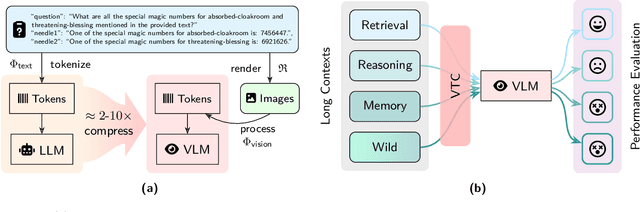

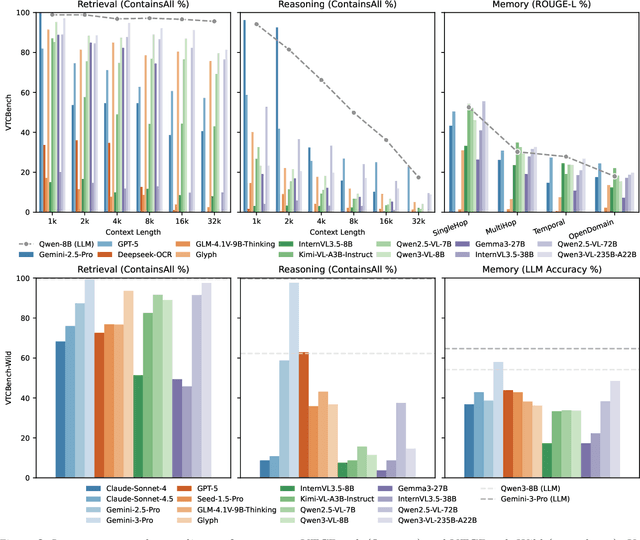
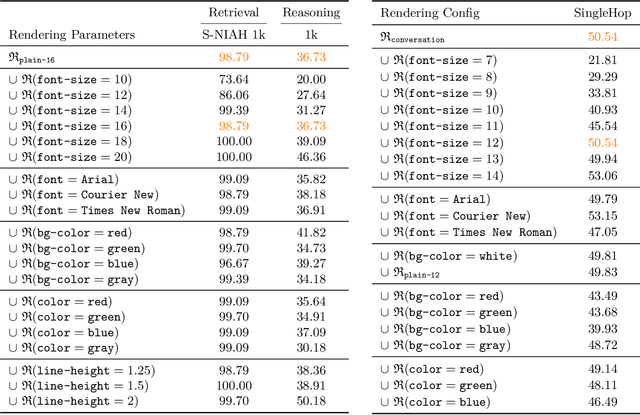
The computational and memory overheads associated with expanding the context window of LLMs severely limit their scalability. A noteworthy solution is vision-text compression (VTC), exemplified by frameworks like DeepSeek-OCR and Glyph, which convert long texts into dense 2D visual representations, thereby achieving token compression ratios of 3x-20x. However, the impact of this high information density on the core long-context capabilities of vision-language models (VLMs) remains under-investigated. To address this gap, we introduce the first benchmark for VTC and systematically assess the performance of VLMs across three long-context understanding settings: VTC-Retrieval, which evaluates the model's ability to retrieve and aggregate information; VTC-Reasoning, which requires models to infer latent associations to locate facts with minimal lexical overlap; and VTC-Memory, which measures comprehensive question answering within long-term dialogue memory. Furthermore, we establish the VTCBench-Wild to simulate diverse input scenarios.We comprehensively evaluate leading open-source and proprietary models on our benchmarks. The results indicate that, despite being able to decode textual information (e.g., OCR) well, most VLMs exhibit a surprisingly poor long-context understanding ability with VTC-processed information, failing to capture long associations or dependencies in the context.This study provides a deep understanding of VTC and serves as a foundation for designing more efficient and scalable VLMs.
C-NAV: Towards Self-Evolving Continual Object Navigation in Open World
Oct 23, 2025Embodied agents are expected to perform object navigation in dynamic, open-world environments. However, existing approaches typically rely on static trajectories and a fixed set of object categories during training, overlooking the real-world requirement for continual adaptation to evolving scenarios. To facilitate related studies, we introduce the continual object navigation benchmark, which requires agents to acquire navigation skills for new object categories while avoiding catastrophic forgetting of previously learned knowledge. To tackle this challenge, we propose C-Nav, a continual visual navigation framework that integrates two key innovations: (1) A dual-path anti-forgetting mechanism, which comprises feature distillation that aligns multi-modal inputs into a consistent representation space to ensure representation consistency, and feature replay that retains temporal features within the action decoder to ensure policy consistency. (2) An adaptive sampling strategy that selects diverse and informative experiences, thereby reducing redundancy and minimizing memory overhead. Extensive experiments across multiple model architectures demonstrate that C-Nav consistently outperforms existing approaches, achieving superior performance even compared to baselines with full trajectory retention, while significantly lowering memory requirements. The code will be publicly available at https://bigtree765.github.io/C-Nav-project.
MCITlib: Multimodal Continual Instruction Tuning Library and Benchmark
Aug 10, 2025Continual learning aims to equip AI systems with the ability to continuously acquire and adapt to new knowledge without forgetting previously learned information, similar to human learning. While traditional continual learning methods focusing on unimodal tasks have achieved notable success, the emergence of Multimodal Large Language Models has brought increasing attention to Multimodal Continual Learning tasks involving multiple modalities, such as vision and language. In this setting, models are expected to not only mitigate catastrophic forgetting but also handle the challenges posed by cross-modal interactions and coordination. To facilitate research in this direction, we introduce MCITlib, a comprehensive and constantly evolving code library for continual instruction tuning of Multimodal Large Language Models. In MCITlib, we have currently implemented 8 representative algorithms for Multimodal Continual Instruction Tuning and systematically evaluated them on 2 carefully selected benchmarks. MCITlib will be continuously updated to reflect advances in the Multimodal Continual Learning field. The codebase is released at https://github.com/Ghy0501/MCITlib.
A Comprehensive Survey on Continual Learning in Generative Models
Jun 16, 2025The rapid advancement of generative models has enabled modern AI systems to comprehend and produce highly sophisticated content, even achieving human-level performance in specific domains. However, these models remain fundamentally constrained by catastrophic forgetting - a persistent challenge where adapting to new tasks typically leads to significant degradation in performance on previously learned tasks. To address this practical limitation, numerous approaches have been proposed to enhance the adaptability and scalability of generative models in real-world applications. In this work, we present a comprehensive survey of continual learning methods for mainstream generative models, including large language models, multimodal large language models, vision language action models, and diffusion models. Drawing inspiration from the memory mechanisms of the human brain, we systematically categorize these approaches into three paradigms: architecture-based, regularization-based, and replay-based methods, while elucidating their underlying methodologies and motivations. We further analyze continual learning setups for different generative models, including training objectives, benchmarks, and core backbones, offering deeper insights into the field. The project page of this paper is available at https://github.com/Ghy0501/Awesome-Continual-Learning-in-Generative-Models.
LLaVA-c: Continual Improved Visual Instruction Tuning
Jun 10, 2025Multimodal models like LLaVA-1.5 achieve state-of-the-art visual understanding through visual instruction tuning on multitask datasets, enabling strong instruction-following and multimodal performance. However, multitask learning faces challenges such as task balancing, requiring careful adjustment of data proportions, and expansion costs, where new tasks risk catastrophic forgetting and need costly retraining. Continual learning provides a promising alternative to acquiring new knowledge incrementally while preserving existing capabilities. However, current methods prioritize task-specific performance, neglecting base model degradation from overfitting to specific instructions, which undermines general capabilities. In this work, we propose a simple but effective method with two modifications on LLaVA-1.5: spectral-aware consolidation for improved task balance and unsupervised inquiry regularization to prevent base model degradation. We evaluate both general and task-specific performance across continual pretraining and fine-tuning. Experiments demonstrate that LLaVA-c consistently enhances standard benchmark performance and preserves general capabilities. For the first time, we show that task-by-task continual learning can achieve results that match or surpass multitask joint learning. The code will be publicly released.
MLLM-CL: Continual Learning for Multimodal Large Language Models
Jun 05, 2025



Recent Multimodal Large Language Models (MLLMs) excel in vision-language understanding but face challenges in adapting to dynamic real-world scenarios that require continuous integration of new knowledge and skills. While continual learning (CL) offers a potential solution, existing benchmarks and methods suffer from critical limitations. In this paper, we introduce MLLM-CL, a novel benchmark encompassing domain and ability continual learning, where the former focuses on independently and identically distributed (IID) evaluation across evolving mainstream domains, whereas the latter evaluates on non-IID scenarios with emerging model ability. Methodologically, we propose preventing catastrophic interference through parameter isolation, along with an MLLM-based routing mechanism. Extensive experiments demonstrate that our approach can integrate domain-specific knowledge and functional abilities with minimal forgetting, significantly outperforming existing methods.
TrustLoRA: Low-Rank Adaptation for Failure Detection under Out-of-distribution Data
Apr 20, 2025
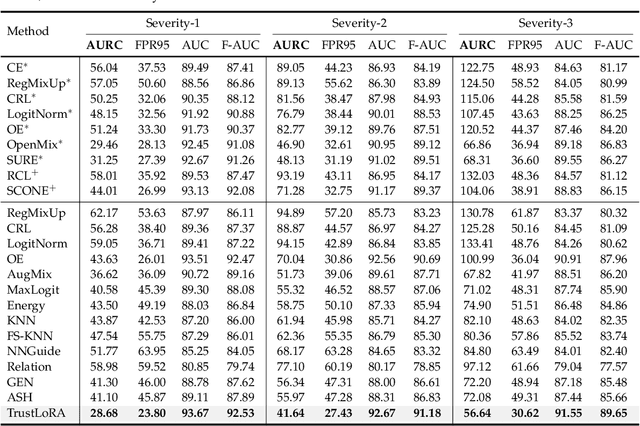
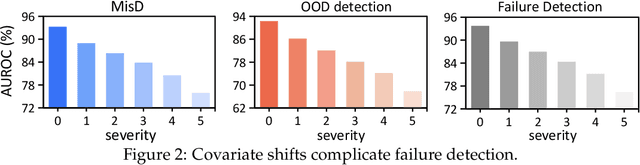
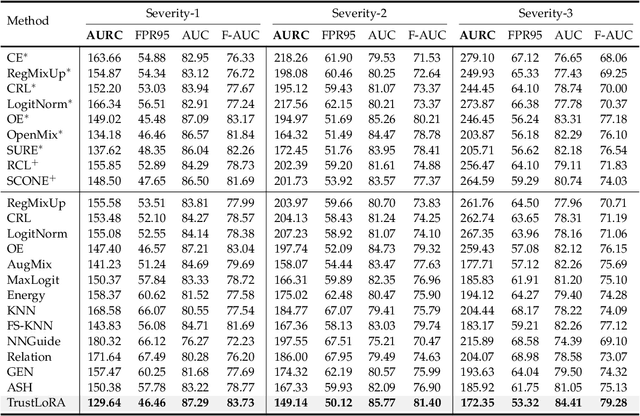
Reliable prediction is an essential requirement for deep neural models that are deployed in open environments, where both covariate and semantic out-of-distribution (OOD) data arise naturally. In practice, to make safe decisions, a reliable model should accept correctly recognized inputs while rejecting both those misclassified covariate-shifted and semantic-shifted examples. Besides, considering the potential existing trade-off between rejecting different failure cases, more convenient, controllable, and flexible failure detection approaches are needed. To meet the above requirements, we propose a simple failure detection framework to unify and facilitate classification with rejection under both covariate and semantic shifts. Our key insight is that by separating and consolidating failure-specific reliability knowledge with low-rank adapters and then integrating them, we can enhance the failure detection ability effectively and flexibly. Extensive experiments demonstrate the superiority of our framework.