 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCL-VISTA: Benchmarking Continual Learning in Video Large Language Models
Apr 01, 2026Video Large Language Models (Video-LLMs) require continual learning to adapt to non-stationary real-world data. However, existing benchmarks fall short of evaluating modern foundation models: many still rely on models without large-scale pre-training, and prevailing benchmarks typically partition a single dataset into sub-tasks, resulting in high task redundancy and negligible forgetting on pre-trained Video-LLMs. To address these limitations, we propose CL-VISTA, a benchmark tailored for continual video understanding of Video-LLMs. By curating 8 diverse tasks spanning perception, understanding, and reasoning, CL-VISTA induces substantial distribution shifts that effectively expose catastrophic forgetting. To systematically assess CL methods, we establish a comprehensive evaluation framework comprising 6 distinct protocols across 3 critical dimensions: performance, computational efficiency, and memory footprint. Notably, the performance dimension incorporates a general video understanding assessment to assess whether CL methods genuinely enhance foundational intelligence or merely induce task-specific overfitting. Extensive benchmarking of 10 mainstream CL methods reveals a fundamental trade-off: no single approach achieves universal superiority across all dimensions. Methods that successfully mitigate catastrophic forgetting tend to compromise generalization or incur prohibitive computational and memory overheads. We hope CL-VISTA provides critical insights for advancing continual learning in multimodal foundation models.
Fine-Grained Post-Training Quantization for Large Vision Language Models with Quantization-Aware Integrated Gradients
Mar 18, 2026Large Vision Language Models (LVLMs) have achieved remarkable success in a range of downstream tasks that require multimodal interaction, but their capabilities come with substantial computational and memory overhead, which hinders practical deployment. Among numerous acceleration techniques, post-training quantization is a popular and effective strategy for reducing memory cost and accelerating inference. However, existing LVLM quantization methods typically measure token sensitivity at the modality level, which fails to capture the complex cross-token interactions and falls short in quantitatively measuring the quantization error at the token level. As tokens interact within the model, the distinction between modalities gradually diminishes, suggesting the need for fine-grained calibration. Inspired by axiomatic attribution in mechanistic interpretability, we introduce a fine-grained quantization strategy on Quantization-aware Integrated Gradients (QIG), which leverages integrated gradients to quantitatively evaluate token sensitivity and push the granularity from modality level to token level, reflecting both inter-modality and intra-modality dynamics. Extensive experiments on multiple LVLMs under both W4A8 and W3A16 settings show that our method improves accuracy across models and benchmarks with negligible latency overhead. For example, under 3-bit weight-only quantization, our method improves the average accuracy of LLaVA-onevision-7B by 1.60%, reducing the gap to its full-precision counterpart to only 1.33%. The code is available at https://github.com/ucas-xiang/QIG.
Context Tokens are Anchors: Understanding the Repetition Curse in dMLLMs from an Information Flow Perspective
Jan 28, 2026Recent diffusion-based Multimodal Large Language Models (dMLLMs) suffer from high inference latency and therefore rely on caching techniques to accelerate decoding. However, the application of cache mechanisms often introduces undesirable repetitive text generation, a phenomenon we term the \textbf{Repeat Curse}. To better investigate underlying mechanism behind this issue, we analyze repetition generation through the lens of information flow. Our work reveals three key findings: (1) context tokens aggregate semantic information as anchors and guide the final predictions; (2) as information propagates across layers, the entropy of context tokens converges in deeper layers, reflecting the model's growing prediction certainty; (3) Repetition is typically linked to disruptions in the information flow of context tokens and to the inability of their entropy to converge in deeper layers. Based on these insights, we present \textbf{CoTA}, a plug-and-play method for mitigating repetition. CoTA enhances the attention of context tokens to preserve intrinsic information flow patterns, while introducing a penalty term to the confidence score during decoding to avoid outputs driven by uncertain context tokens. With extensive experiments, CoTA demonstrates significant effectiveness in alleviating repetition and achieves consistent performance improvements on general tasks. Code is available at https://github.com/ErikZ719/CoTA
Generation-Augmented Generation: A Plug-and-Play Framework for Private Knowledge Injection in Large Language Models
Jan 13, 2026In domains such as biomedicine, materials, and finance, high-stakes deployment of large language models (LLMs) requires injecting private, domain-specific knowledge that is proprietary, fast-evolving, and under-represented in public pretraining. However, the two dominant paradigms for private knowledge injection each have pronounced drawbacks: fine-tuning is expensive to iterate, and continual updates risk catastrophic forgetting and general-capability regression; retrieval-augmented generation (RAG) keeps the base model intact but is brittle in specialized private corpora due to chunk-induced evidence fragmentation, retrieval drift, and long-context pressure that yields query-dependent prompt inflation. Inspired by how multimodal LLMs align heterogeneous modalities into a shared semantic space, we propose Generation-Augmented Generation (GAG), which treats private expertise as an additional expert modality and injects it via a compact, representation-level interface aligned to the frozen base model, avoiding prompt-time evidence serialization while enabling plug-and-play specialization and scalable multi-domain composition with reliable selective activation. Across two private scientific QA benchmarks (immunology adjuvant and catalytic materials) and mixed-domain evaluations, GAG improves specialist performance over strong RAG baselines by 15.34% and 14.86% on the two benchmarks, respectively, while maintaining performance on six open general benchmarks and enabling near-oracle selective activation for scalable multi-domain deployment.
PDE-Agent: A toolchain-augmented multi-agent framework for PDE solving
Dec 22, 2025



Solving Partial Differential Equations (PDEs) is a cornerstone of engineering and scientific research. Traditional methods for PDE solving are cumbersome, relying on manual setup and domain expertise. While Physics-Informed Neural Network (PINNs) introduced end-to-end neural network-based solutions, and frameworks like DeepXDE further enhanced automation, these approaches still depend on expert knowledge and lack full autonomy. In this work, we frame PDE solving as tool invocation via LLM-driven agents and introduce PDE-Agent, the first toolchain-augmented multi-agent collaboration framework, inheriting the reasoning capacity of LLMs and the controllability of external tools and enabling automated PDE solving from natural language descriptions. PDE-Agent leverages the strengths of multi-agent and multi-tool collaboration through two key innovations: (1) A Prog-Act framework with graph memory for multi-agent collaboration, which enables effective dynamic planning and error correction via dual-loop mechanisms (localized fixes and global revisions). (2) A Resource-Pool integrated with a tool-parameter separation mechanism for multi-tool collaboration. This centralizes the management of runtime artifacts and resolves inter-tool dependency gaps in existing frameworks. To validate and evaluate this new paradigm for PDE solving , we develop PDE-Bench, a multi-type PDE Benchmark for agent-based tool collaborative solving, and propose multi-level metrics for assessing tool coordination. Evaluations verify that PDE-Agent exhibits superior applicability and performance in complex multi-step, cross-step dependent tasks. This new paradigm of toolchain-augmented multi-agent PDE solving will further advance future developments in automated scientific computing. Our source code and dataset will be made publicly available.
Multimodal Continual Instruction Tuning with Dynamic Gradient Guidance
Nov 19, 2025



Multimodal continual instruction tuning enables multimodal large language models to sequentially adapt to new tasks while building upon previously acquired knowledge. However, this continual learning paradigm faces the significant challenge of catastrophic forgetting, where learning new tasks leads to performance degradation on previous ones. In this paper, we introduce a novel insight into catastrophic forgetting by conceptualizing it as a problem of missing gradients from old tasks during new task learning. Our approach approximates these missing gradients by leveraging the geometric properties of the parameter space, specifically using the directional vector between current parameters and previously optimal parameters as gradient guidance. This approximated gradient can be further integrated with real gradients from a limited replay buffer and regulated by a Bernoulli sampling strategy that dynamically balances model stability and plasticity. Extensive experiments on multimodal continual instruction tuning datasets demonstrate that our method achieves state-of-the-art performance without model expansion, effectively mitigating catastrophic forgetting while maintaining a compact architecture.
SciAgent: A Unified Multi-Agent System for Generalistic Scientific Reasoning
Nov 17, 2025Recent advances in large language models have enabled AI systems to achieve expert-level performance on domain-specific scientific tasks, yet these systems remain narrow and handcrafted. We introduce SciAgent, a unified multi-agent system designed for generalistic scientific reasoning-the ability to adapt reasoning strategies across disciplines and difficulty levels. SciAgent organizes problem solving as a hierarchical process: a Coordinator Agent interprets each problem's domain and complexity, dynamically orchestrating specialized Worker Systems, each composed of interacting reasoning Sub-agents for symbolic deduction, conceptual modeling, numerical computation, and verification. These agents collaboratively assemble and refine reasoning pipelines tailored to each task. Across mathematics and physics Olympiads (IMO, IMC, IPhO, CPhO), SciAgent consistently attains or surpasses human gold-medalist performance, demonstrating both domain generality and reasoning adaptability. Additionally, SciAgent has been tested on the International Chemistry Olympiad (IChO) and selected problems from the Humanity's Last Exam (HLE) benchmark, further confirming the system's ability to generalize across diverse scientific domains. This work establishes SciAgent as a concrete step toward generalistic scientific intelligence-AI systems capable of coherent, cross-disciplinary reasoning at expert levels.
MorphoBench: A Benchmark with Difficulty Adaptive to Model Reasoning
Oct 16, 2025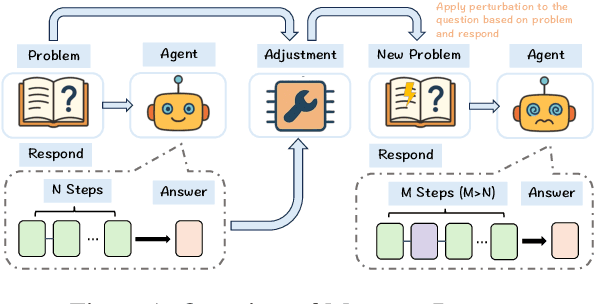

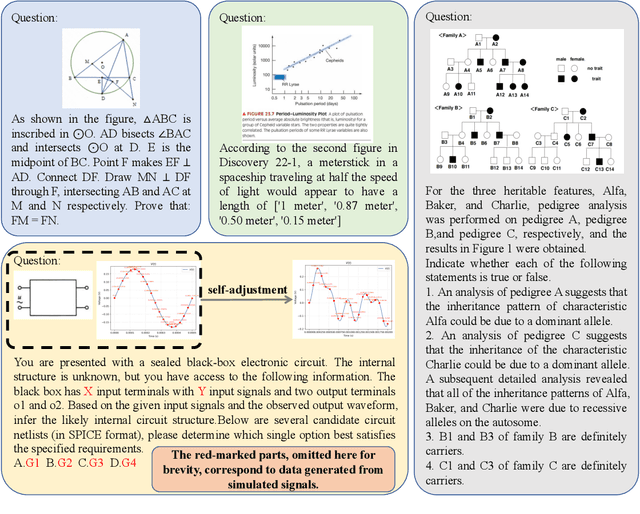
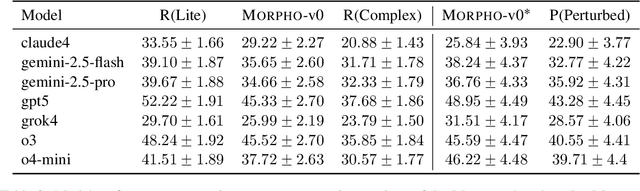
With the advancement of powerful large-scale reasoning models, effectively evaluating the reasoning capabilities of these models has become increasingly important. However, existing benchmarks designed to assess the reasoning abilities of large models tend to be limited in scope and lack the flexibility to adapt their difficulty according to the evolving reasoning capacities of the models. To address this, we propose MorphoBench, a benchmark that incorporates multidisciplinary questions to evaluate the reasoning capabilities of large models and can adjust and update question difficulty based on the reasoning abilities of advanced models. Specifically, we curate the benchmark by selecting and collecting complex reasoning questions from existing benchmarks and sources such as Olympiad-level competitions. Additionally, MorphoBench adaptively modifies the analytical challenge of questions by leveraging key statements generated during the model's reasoning process. Furthermore, it includes questions generated using simulation software, enabling dynamic adjustment of benchmark difficulty with minimal resource consumption. We have gathered over 1,300 test questions and iteratively adjusted the difficulty of MorphoBench based on the reasoning capabilities of models such as o3 and GPT-5. MorphoBench enhances the comprehensiveness and validity of model reasoning evaluation, providing reliable guidance for improving both the reasoning abilities and scientific robustness of large models. The code has been released in https://github.com/OpenDCAI/MorphoBench.
MCITlib: Multimodal Continual Instruction Tuning Library and Benchmark
Aug 10, 2025Continual learning aims to equip AI systems with the ability to continuously acquire and adapt to new knowledge without forgetting previously learned information, similar to human learning. While traditional continual learning methods focusing on unimodal tasks have achieved notable success, the emergence of Multimodal Large Language Models has brought increasing attention to Multimodal Continual Learning tasks involving multiple modalities, such as vision and language. In this setting, models are expected to not only mitigate catastrophic forgetting but also handle the challenges posed by cross-modal interactions and coordination. To facilitate research in this direction, we introduce MCITlib, a comprehensive and constantly evolving code library for continual instruction tuning of Multimodal Large Language Models. In MCITlib, we have currently implemented 8 representative algorithms for Multimodal Continual Instruction Tuning and systematically evaluated them on 2 carefully selected benchmarks. MCITlib will be continuously updated to reflect advances in the Multimodal Continual Learning field. The codebase is released at https://github.com/Ghy0501/MCITlib.
A Comprehensive Survey on Continual Learning in Generative Models
Jun 16, 2025The rapid advancement of generative models has enabled modern AI systems to comprehend and produce highly sophisticated content, even achieving human-level performance in specific domains. However, these models remain fundamentally constrained by catastrophic forgetting - a persistent challenge where adapting to new tasks typically leads to significant degradation in performance on previously learned tasks. To address this practical limitation, numerous approaches have been proposed to enhance the adaptability and scalability of generative models in real-world applications. In this work, we present a comprehensive survey of continual learning methods for mainstream generative models, including large language models, multimodal large language models, vision language action models, and diffusion models. Drawing inspiration from the memory mechanisms of the human brain, we systematically categorize these approaches into three paradigms: architecture-based, regularization-based, and replay-based methods, while elucidating their underlying methodologies and motivations. We further analyze continual learning setups for different generative models, including training objectives, benchmarks, and core backbones, offering deeper insights into the field. The project page of this paper is available at https://github.com/Ghy0501/Awesome-Continual-Learning-in-Generative-Models.