 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaineiFRDM: Explore Diffusion to Restore Defects in Fast-Movement Films
Dec 31, 2025Existing open-source film restoration methods show limited performance compared to commercial methods due to training with low-quality synthetic data and employing noisy optical flows. In addition, high-resolution films have not been explored by the open-source methods.We propose HaineiFRDM(Film Restoration Diffusion Model), a film restoration framework, to explore diffusion model's powerful content-understanding ability to help human expert better restore indistinguishable film defects.Specifically, we employ a patch-wise training and testing strategy to make restoring high-resolution films on one 24GB-VRAMR GPU possible and design a position-aware Global Prompt and Frame Fusion Modules.Also, we introduce a global-local frequency module to reconstruct consistent textures among different patches. Besides, we firstly restore a low-resolution result and use it as global residual to mitigate blocky artifacts caused by patching process.Furthermore, we construct a film restoration dataset that contains restored real-degraded films and realistic synthetic data.Comprehensive experimental results conclusively demonstrate the superiority of our model in defect restoration ability over existing open-source methods. Code and the dataset will be released.
Plug-and-Play Parameter-Efficient Tuning of Embeddings for Federated Recommendation
Dec 14, 2025With the rise of cloud-edge collaboration, recommendation services are increasingly trained in distributed environments. Federated Recommendation (FR) enables such multi-end collaborative training while preserving privacy by sharing model parameters instead of raw data. However, the large number of parameters, primarily due to the massive item embeddings, significantly hampers communication efficiency. While existing studies mainly focus on improving the efficiency of FR models, they largely overlook the issue of embedding parameter overhead. To address this gap, we propose a FR training framework with Parameter-Efficient Fine-Tuning (PEFT) based embedding designed to reduce the volume of embedding parameters that need to be transmitted. Our approach offers a lightweight, plugin-style solution that can be seamlessly integrated into existing FR methods. In addition to incorporating common PEFT techniques such as LoRA and Hash-based encoding, we explore the use of Residual Quantized Variational Autoencoders (RQ-VAE) as a novel PEFT strategy within our framework. Extensive experiments across various FR model backbones and datasets demonstrate that our framework significantly reduces communication overhead while improving accuracy. The source code is available at https://github.com/young1010/FedPEFT.
Multimodal Continual Instruction Tuning with Dynamic Gradient Guidance
Nov 19, 2025



Multimodal continual instruction tuning enables multimodal large language models to sequentially adapt to new tasks while building upon previously acquired knowledge. However, this continual learning paradigm faces the significant challenge of catastrophic forgetting, where learning new tasks leads to performance degradation on previous ones. In this paper, we introduce a novel insight into catastrophic forgetting by conceptualizing it as a problem of missing gradients from old tasks during new task learning. Our approach approximates these missing gradients by leveraging the geometric properties of the parameter space, specifically using the directional vector between current parameters and previously optimal parameters as gradient guidance. This approximated gradient can be further integrated with real gradients from a limited replay buffer and regulated by a Bernoulli sampling strategy that dynamically balances model stability and plasticity. Extensive experiments on multimodal continual instruction tuning datasets demonstrate that our method achieves state-of-the-art performance without model expansion, effectively mitigating catastrophic forgetting while maintaining a compact architecture.
Self-Critique Guided Iterative Reasoning for Multi-hop Question Answering
May 25, 2025Although large language models (LLMs) have demonstrated remarkable reasoning capabilities, they still face challenges in knowledge-intensive multi-hop reasoning. Recent work explores iterative retrieval to address complex problems. However, the lack of intermediate guidance often results in inaccurate retrieval and flawed intermediate reasoning, leading to incorrect reasoning. To address these, we propose Self-Critique Guided Iterative Reasoning (SiGIR), which uses self-critique feedback to guide the iterative reasoning process. Specifically, through end-to-end training, we enable the model to iteratively address complex problems via question decomposition. Additionally, the model is able to self-evaluate its intermediate reasoning steps. During iterative reasoning, the model engages in branching exploration and employs self-evaluation to guide the selection of promising reasoning trajectories. Extensive experiments on three multi-hop reasoning datasets demonstrate the effectiveness of our proposed method, surpassing the previous SOTA by $8.6\%$. Furthermore, our thorough analysis offers insights for future research. Our code, data, and models are available at Github: https://github.com/zchuz/SiGIR-MHQA.
DUKAE: DUal-level Knowledge Accumulation and Ensemble for Pre-Trained Model-Based Continual Learning
Apr 09, 2025Pre-trained model-based continual learning (PTMCL) has garnered growing attention, as it enables more rapid acquisition of new knowledge by leveraging the extensive foundational understanding inherent in pre-trained model (PTM). Most existing PTMCL methods use Parameter-Efficient Fine-Tuning (PEFT) to learn new knowledge while consolidating existing memory. However, they often face some challenges. A major challenge lies in the misalignment of classification heads, as the classification head of each task is trained within a distinct feature space, leading to inconsistent decision boundaries across tasks and, consequently, increased forgetting. Another critical limitation stems from the restricted feature-level knowledge accumulation, with feature learning typically restricted to the initial task only, which constrains the model's representation capabilities. To address these issues, we propose a method named DUal-level Knowledge Accumulation and Ensemble (DUKAE) that leverages both feature-level and decision-level knowledge accumulation by aligning classification heads into a unified feature space through Gaussian distribution sampling and introducing an adaptive expertise ensemble to fuse knowledge across feature subspaces.Extensive experiments on CIFAR-100, ImageNet-R, CUB-200, and Cars-196 datasets demonstrate the superior performance of our approach.
BeMERC: Behavior-Aware MLLM-based Framework for Multimodal Emotion Recognition in Conversation
Mar 31, 2025Multimodal emotion recognition in conversation (MERC), the task of identifying the emotion label for each utterance in a conversation, is vital for developing empathetic machines. Current MLLM-based MERC studies focus mainly on capturing the speaker's textual or vocal characteristics, but ignore the significance of video-derived behavior information. Different from text and audio inputs, learning videos with rich facial expression, body language and posture, provides emotion trigger signals to the models for more accurate emotion predictions. In this paper, we propose a novel behavior-aware MLLM-based framework (BeMERC) to incorporate speaker's behaviors, including subtle facial micro-expression, body language and posture, into a vanilla MLLM-based MERC model, thereby facilitating the modeling of emotional dynamics during a conversation. Furthermore, BeMERC adopts a two-stage instruction tuning strategy to extend the model to the conversations scenario for end-to-end training of a MERC predictor. Experiments demonstrate that BeMERC achieves superior performance than the state-of-the-art methods on two benchmark datasets, and also provides a detailed discussion on the significance of video-derived behavior information in MERC.
Towards Unified Structured Light Optimization
Jan 24, 2025
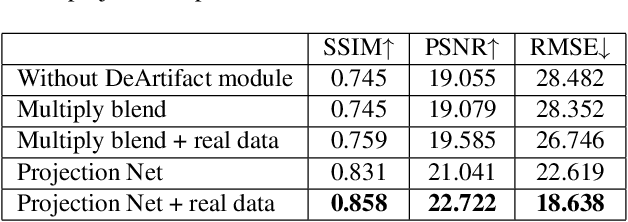
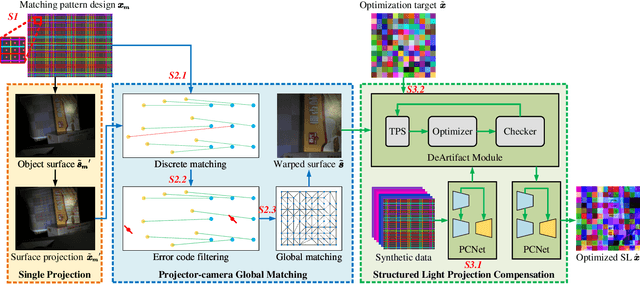

Structured light (SL) 3D reconstruction captures the precise surface shape of objects, providing high-accuracy 3D data essential for industrial inspection and robotic vision systems. However, current research on optimizing projection patterns in SL 3D reconstruction faces two main limitations: each scene requires separate training of calibration parameters, and optimization is restricted to specific types of SL, which restricts their application range. To tackle these limitations, we present a unified framework for SL optimization, adaptable to diverse lighting conditions, object types, and different types of SL. Our framework quickly determines the optimal projection pattern using only a single projected image. Key contributions include a novel global matching method for projectors, enabling precise projector-camera alignment with just one projected image, and a new projection compensation model with a photometric adjustment module to reduce artifacts from out-of-gamut clipping. Experimental results show our method achieves superior decoding accuracy across various objects, SL patterns, and lighting conditions, significantly outperforming previous methods.
Scene Style Text Editing
Apr 20, 2023In this work, we propose a task called "Scene Style Text Editing (SSTE)", changing the text content as well as the text style of the source image while keeping the original text scene. Existing methods neglect to fine-grained adjust the style of the foreground text, such as its rotation angle, color, and font type. To tackle this task, we propose a quadruple framework named "QuadNet" to embed and adjust foreground text styles in the latent feature space. Specifically, QuadNet consists of four parts, namely background inpainting, style encoder, content encoder, and fusion generator. The background inpainting erases the source text content and recovers the appropriate background with a highly authentic texture. The style encoder extracts the style embedding of the foreground text. The content encoder provides target text representations in the latent feature space to implement the content edits. The fusion generator combines the information yielded from the mentioned parts and generates the rendered text images. Practically, our method is capable of performing promisingly on real-world datasets with merely string-level annotation. To the best of our knowledge, our work is the first to finely manipulate the foreground text content and style by deeply semantic editing in the latent feature space. Extensive experiments demonstrate that QuadNet has the ability to generate photo-realistic foreground text and avoid source text shadows in real-world scenes when editing text content.
A Survey on Deep Neural Network Partition over Cloud, Edge and End Devices
Apr 20, 2023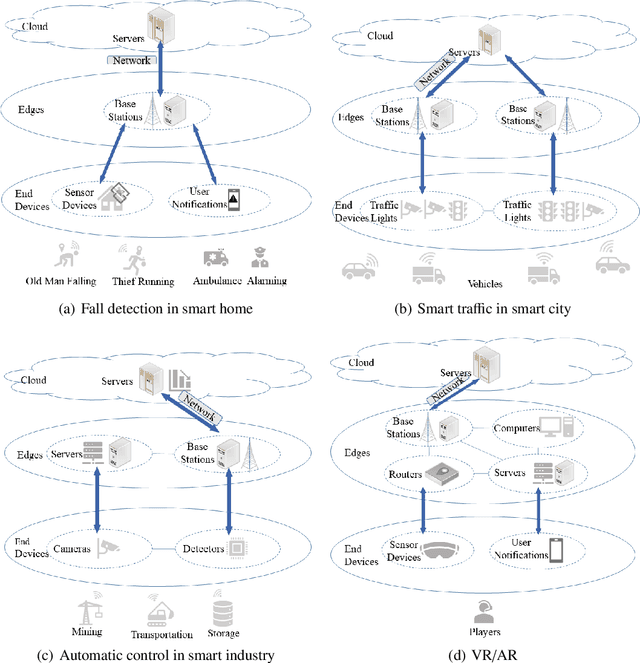
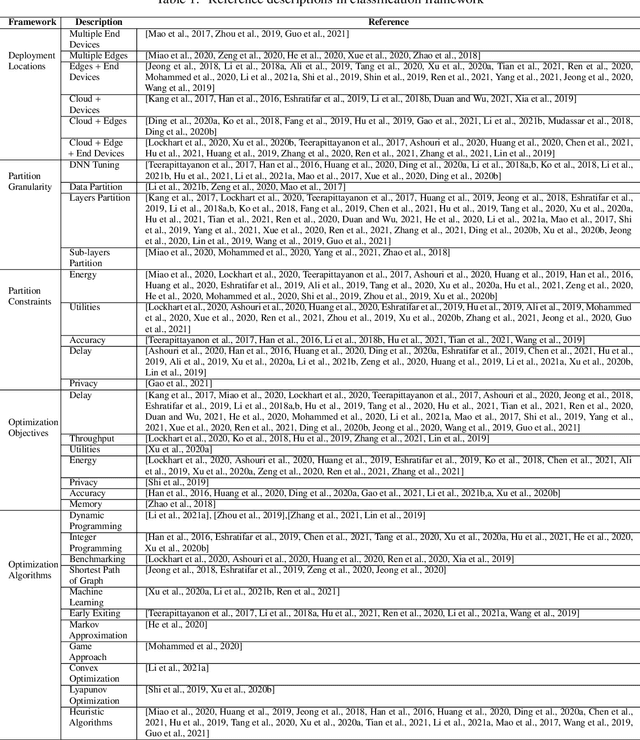
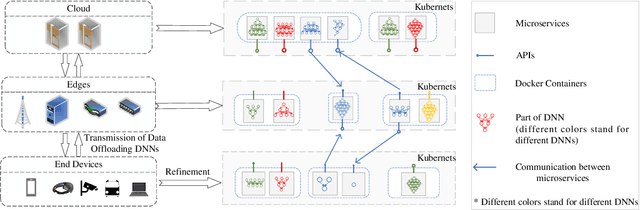
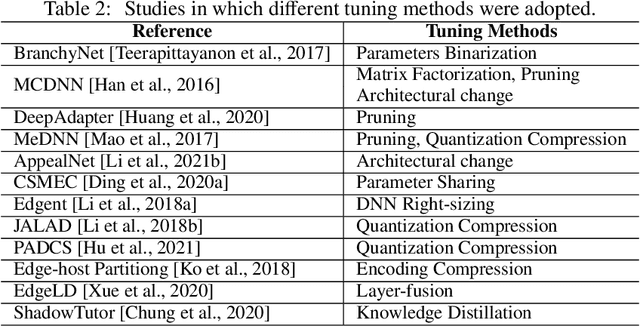
Deep neural network (DNN) partition is a research problem that involves splitting a DNN into multiple parts and offloading them to specific locations. Because of the recent advancement in multi-access edge computing and edge intelligence, DNN partition has been considered as a powerful tool for improving DNN inference performance when the computing resources of edge and end devices are limited and the remote transmission of data from these devices to clouds is costly. This paper provides a comprehensive survey on the recent advances and challenges in DNN partition approaches over the cloud, edge, and end devices based on a detailed literature collection. We review how DNN partition works in various application scenarios, and provide a unified mathematical model of the DNN partition problem. We developed a five-dimensional classification framework for DNN partition approaches, consisting of deployment locations, partition granularity, partition constraints, optimization objectives, and optimization algorithms. Each existing DNN partition approache can be perfectly defined in this framework by instantiating each dimension into specific values. In addition, we suggest a set of metrics for comparing and evaluating the DNN partition approaches. Based on this, we identify and discuss research challenges that have not yet been investigated or fully addressed. We hope that this work helps DNN partition researchers by highlighting significant future research directions in this domain.
Who Should I Engage with At What Time? A Missing Event Aware Temporal Graph Neural Network
Jan 20, 2023Temporal graph neural network has recently received significant attention due to its wide application scenarios, such as bioinformatics, knowledge graphs, and social networks. There are some temporal graph neural networks that achieve remarkable results. However, these works focus on future event prediction and are performed under the assumption that all historical events are observable. In real-world applications, events are not always observable, and estimating event time is as important as predicting future events. In this paper, we propose MTGN, a missing event-aware temporal graph neural network, which uniformly models evolving graph structure and timing of events to support predicting what will happen in the future and when it will happen.MTGN models the dynamic of both observed and missing events as two coupled temporal point processes, thereby incorporating the effects of missing events into the network. Experimental results on several real-world temporal graphs demonstrate that MTGN significantly outperforms existing methods with up to 89% and 112% more accurate time and link prediction. Code can be found on https://github.com/HIT-ICES/TNNLS-MTGN.