 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Critique Guided Iterative Reasoning for Multi-hop Question Answering
May 25, 2025Although large language models (LLMs) have demonstrated remarkable reasoning capabilities, they still face challenges in knowledge-intensive multi-hop reasoning. Recent work explores iterative retrieval to address complex problems. However, the lack of intermediate guidance often results in inaccurate retrieval and flawed intermediate reasoning, leading to incorrect reasoning. To address these, we propose Self-Critique Guided Iterative Reasoning (SiGIR), which uses self-critique feedback to guide the iterative reasoning process. Specifically, through end-to-end training, we enable the model to iteratively address complex problems via question decomposition. Additionally, the model is able to self-evaluate its intermediate reasoning steps. During iterative reasoning, the model engages in branching exploration and employs self-evaluation to guide the selection of promising reasoning trajectories. Extensive experiments on three multi-hop reasoning datasets demonstrate the effectiveness of our proposed method, surpassing the previous SOTA by $8.6\%$. Furthermore, our thorough analysis offers insights for future research. Our code, data, and models are available at Github: https://github.com/zchuz/SiGIR-MHQA.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
BeamAggR: Beam Aggregation Reasoning over Multi-source Knowledge for Multi-hop Question Answering
Jun 28, 2024



Large language models (LLMs) have demonstrated strong reasoning capabilities. Nevertheless, they still suffer from factual errors when tackling knowledge-intensive tasks. Retrieval-augmented reasoning represents a promising approach. However, significant challenges still persist, including inaccurate and insufficient retrieval for complex questions, as well as difficulty in integrating multi-source knowledge. To address this, we propose Beam Aggregation Reasoning, BeamAggR, a reasoning framework for knowledge-intensive multi-hop QA. BeamAggR explores and prioritizes promising answers at each hop of question. Concretely, we parse the complex questions into trees, which include atom and composite questions, followed by bottom-up reasoning. For atomic questions, the LLM conducts reasoning on multi-source knowledge to get answer candidates. For composite questions, the LLM combines beam candidates, explores multiple reasoning paths through probabilistic aggregation, and prioritizes the most promising trajectory. Extensive experiments on four open-domain multi-hop reasoning datasets show that our method significantly outperforms SOTA methods by 8.5%. Furthermore, our analysis reveals that BeamAggR elicits better knowledge collaboration and answer aggregation.
An Information Bottleneck Perspective for Effective Noise Filtering on Retrieval-Augmented Generation
Jun 03, 2024



Retrieval-augmented generation integrates the capabilities of large language models with relevant information retrieved from an extensive corpus, yet encounters challenges when confronted with real-world noisy data. One recent solution is to train a filter module to find relevant content but only achieve suboptimal noise compression. In this paper, we propose to introduce the information bottleneck theory into retrieval-augmented generation. Our approach involves the filtration of noise by simultaneously maximizing the mutual information between compression and ground output, while minimizing the mutual information between compression and retrieved passage. In addition, we derive the formula of information bottleneck to facilitate its application in novel comprehensive evaluations, the selection of supervised fine-tuning data, and the construction of reinforcement learning rewards. Experimental results demonstrate that our approach achieves significant improvements across various question answering datasets, not only in terms of the correctness of answer generation but also in the conciseness with $2.5\%$ compression rate.
Divide-and-Conquer Meets Consensus: Unleashing the Power of Functions in Code Generation
May 30, 2024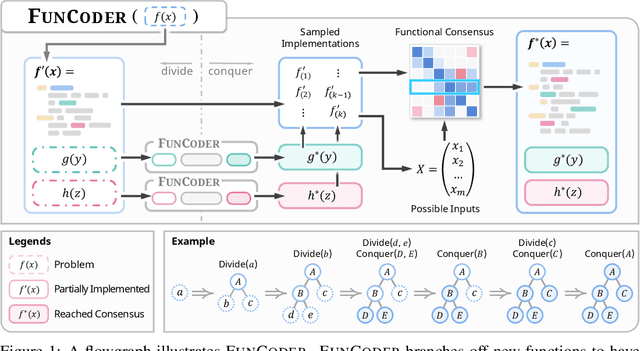
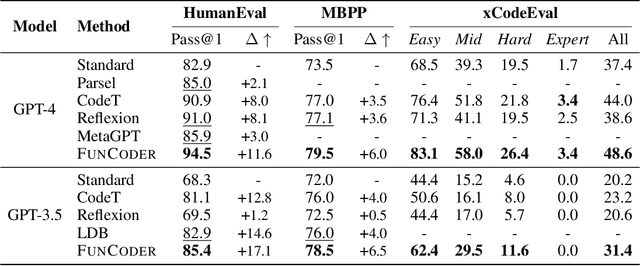


Despite recent progress made by large language models in code generation, they still struggle with programs that meet complex requirements. Recent work utilizes plan-and-solve decomposition to decrease the complexity and leverage self-tests to refine the generated program. Yet, planning deep-inside requirements in advance can be challenging, and the tests need to be accurate to accomplish self-improvement. To this end, we propose FunCoder, a code generation framework incorporating the divide-and-conquer strategy with functional consensus. Specifically, FunCoder recursively branches off sub-functions as smaller goals during code generation, represented by a tree hierarchy. These sub-functions are then composited to attain more complex objectives. Additionally, we designate functions via a consensus formed by identifying similarities in program behavior, mitigating error propagation. FunCoder outperforms state-of-the-art methods by +9.8% on average in HumanEval, MBPP, xCodeEval and MATH with GPT-3.5 and GPT-4. Moreover, our method demonstrates superiority on smaller models: With FunCoder, StableCode-3b surpasses GPT-3.5 by +18.6% and achieves 97.7% of GPT-4's performance on HumanEval. Further analysis reveals that our proposed dynamic function decomposition is capable of handling complex requirements, and the functional consensus prevails over self-testing in correctness evaluation.
TimeBench: A Comprehensive Evaluation of Temporal Reasoning Abilities in Large Language Models
Nov 29, 2023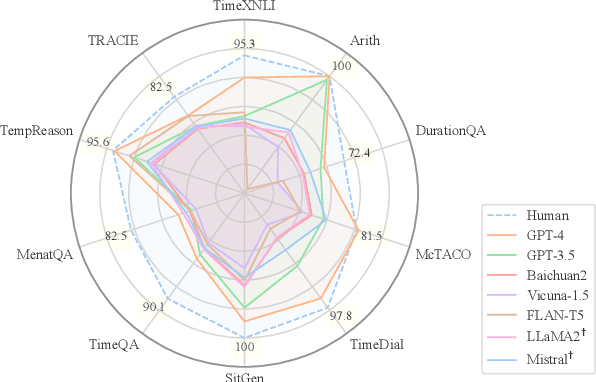

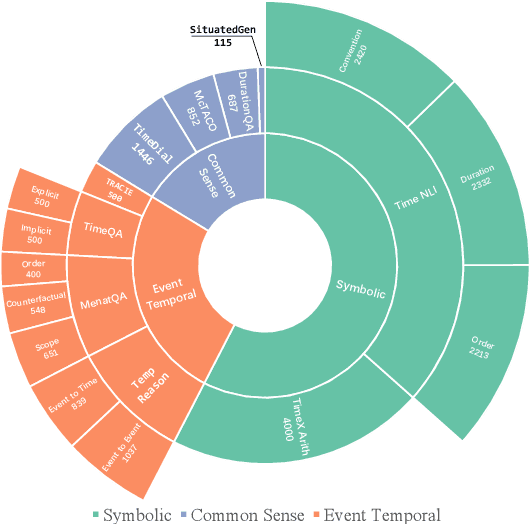

Understanding time is a pivotal aspect of human cognition, crucial in the broader framework of grasping the intricacies of the world. Previous studies typically focus on specific aspects of time, lacking a comprehensive temporal reasoning benchmark. To address this issue, we propose TimeBench, a comprehensive hierarchical temporal reasoning benchmark that covers a broad spectrum of temporal reasoning phenomena, which provides a thorough evaluation for investigating the temporal reasoning capabilities of large language models. We conduct extensive experiments on popular LLMs, such as GPT-4, LLaMA2, and Mistral, incorporating chain-of-thought prompting. Our experimental results indicate a significant performance gap between the state-of-the-art LLMs and humans, highlighting that there is still a considerable distance to cover in temporal reasoning. We aspire for TimeBench to serve as a comprehensive benchmark, fostering research in temporal reasoning for LLMs. Our resource is available at https://github.com/zchuz/TimeBench
A Survey of Chain of Thought Reasoning: Advances, Frontiers and Future
Sep 27, 2023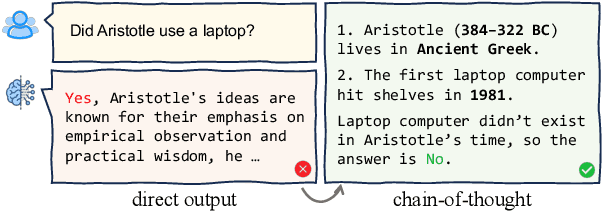
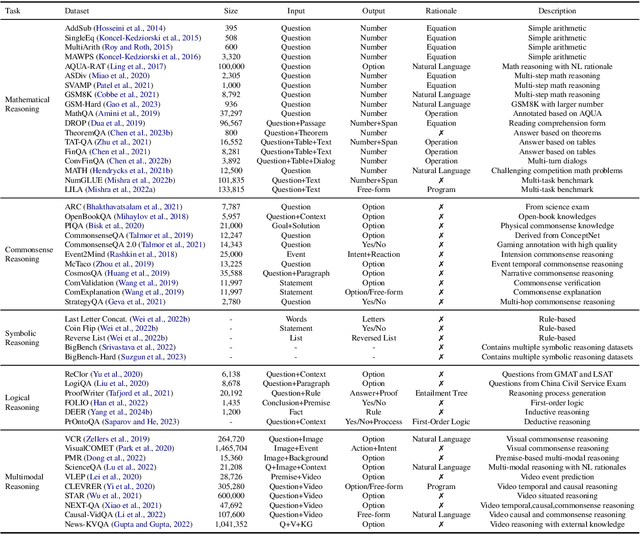
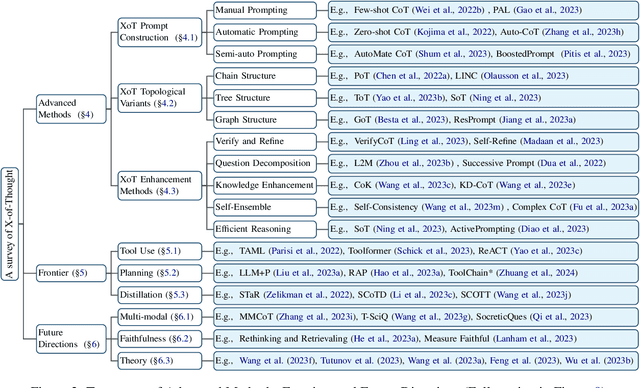
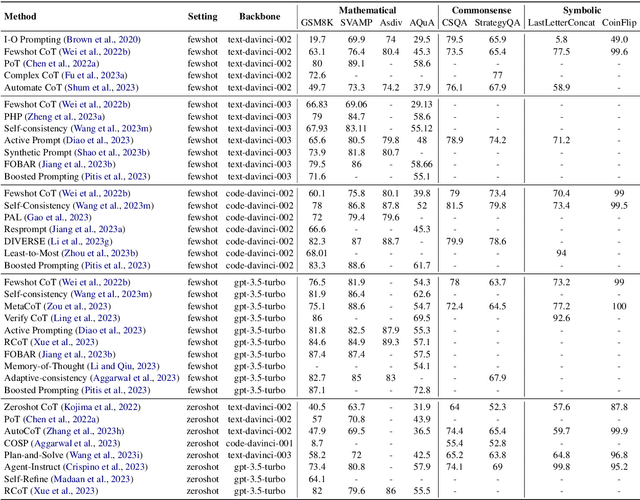
Chain-of-thought reasoning, a cognitive process fundamental to human intelligence, has garnered significant attention in the realm of artificial intelligence and natural language processing. However, there still remains a lack of a comprehensive survey for this arena. To this end, we take the first step and present a thorough survey of this research field carefully and widely. We use X-of-Thought to refer to Chain-of-Thought in a broad sense. In detail, we systematically organize the current research according to the taxonomies of methods, including XoT construction, XoT structure variants, and enhanced XoT. Additionally, we describe XoT with frontier applications, covering planning, tool use, and distillation. Furthermore, we address challenges and discuss some future directions, including faithfulness, multi-modal, and theory. We hope this survey serves as a valuable resource for researchers seeking to innovate within the domain of chain-of-thought reasoning.
SmartTrim: Adaptive Tokens and Parameters Pruning for Efficient Vision-Language Models
May 24, 2023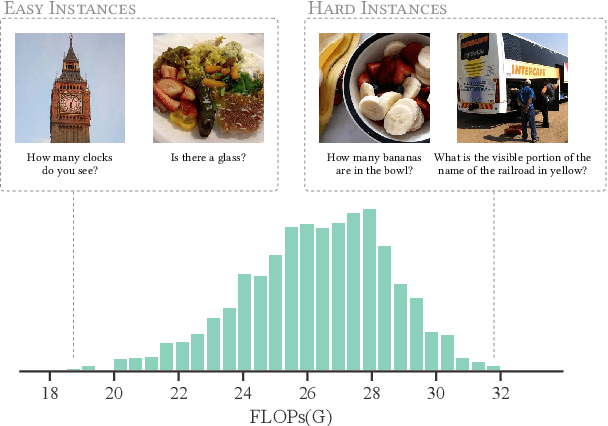
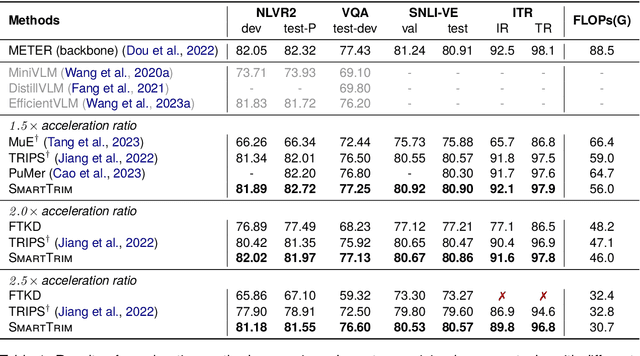
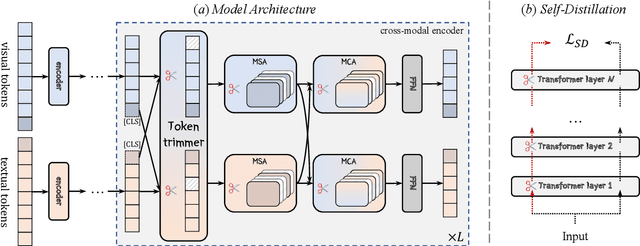
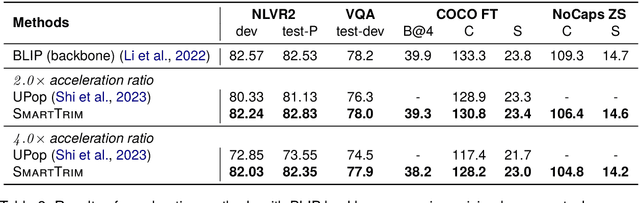
Despite achieving remarkable performance on various vision-language tasks, Transformer-based pretrained vision-language models (VLMs) still suffer from efficiency issues arising from long inputs and numerous parameters, limiting their real-world applications. However, the huge computation is redundant for most samples and the degree of redundancy and the respective components vary significantly depending on tasks and input instances. In this work, we propose an adaptive acceleration method SmartTrim for VLMs, which adjusts the inference overhead based on the complexity of instances. Specifically, SmartTrim incorporates lightweight trimming modules into the backbone to perform task-specific pruning on redundant inputs and parameters, without the need for additional pre-training or data augmentation. Since visual and textual representations complement each other in VLMs, we propose to leverage cross-modal interaction information to provide more critical semantic guidance for identifying redundant parts. Meanwhile, we introduce a self-distillation strategy that encourages the trimmed model to be consistent with the full-capacity model, which yields further performance gains. Experimental results demonstrate that SmartTrim significantly reduces the computation overhead (2-3 times) of various VLMs with comparable performance (only a 1-2% degradation) on various vision-language tasks. Compared to previous acceleration methods, SmartTrim attains a better efficiency-performance trade-off, demonstrating great potential for application in resource-constrained scenarios.