 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeBench: A Comprehensive Evaluation of Temporal Reasoning Abilities in Large Language Models
Paper and Code
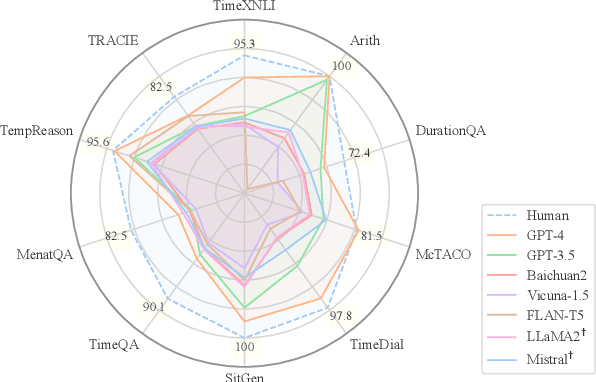

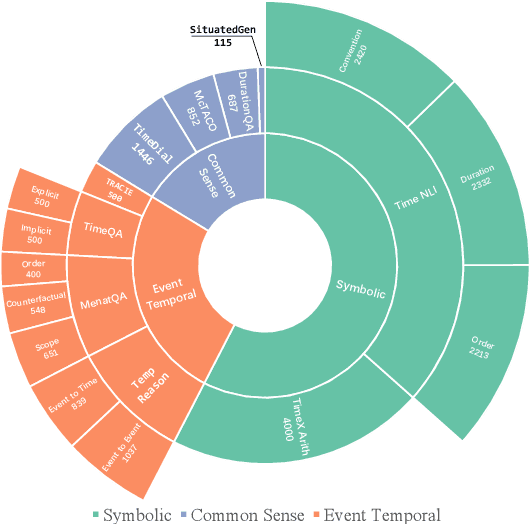

Understanding time is a pivotal aspect of human cognition, crucial in the broader framework of grasping the intricacies of the world. Previous studies typically focus on specific aspects of time, lacking a comprehensive temporal reasoning benchmark. To address this issue, we propose TimeBench, a comprehensive hierarchical temporal reasoning benchmark that covers a broad spectrum of temporal reasoning phenomena, which provides a thorough evaluation for investigating the temporal reasoning capabilities of large language models. We conduct extensive experiments on popular LLMs, such as GPT-4, LLaMA2, and Mistral, incorporating chain-of-thought prompting. Our experimental results indicate a significant performance gap between the state-of-the-art LLMs and humans, highlighting that there is still a considerable distance to cover in temporal reasoning. We aspire for TimeBench to serve as a comprehensive benchmark, fostering research in temporal reasoning for LLMs. Our resource is available at https://github.com/zchuz/TimeBench