 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoThinker: Building Agentic VideoLLMs with LLM-Guided Tool Reasoning
Jan 22, 2026Long-form video understanding remains a fundamental challenge for current Video Large Language Models. Most existing models rely on static reasoning over uniformly sampled frames, which weakens temporal localization and leads to substantial information loss in long videos. Agentic tools such as temporal retrieval, spatial zoom, and temporal zoom offer a natural way to overcome these limitations by enabling adaptive exploration of key moments. However, constructing agentic video understanding data requires models that already possess strong long-form video comprehension, creating a circular dependency. We address this challenge with VideoThinker, an agentic Video Large Language Model trained entirely on synthetic tool interaction trajectories. Our key idea is to convert videos into rich captions and employ a powerful agentic language model to generate multi-step tool use sequences in caption space. These trajectories are subsequently grounded back to video by replacing captions with the corresponding frames, yielding a large-scale interleaved video and tool reasoning dataset without requiring any long-form understanding from the underlying model. Training on this synthetic agentic dataset equips VideoThinker with dynamic reasoning capabilities, adaptive temporal exploration, and multi-step tool use. Remarkably, VideoThinker significantly outperforms both caption-only language model agents and strong video model baselines across long-video benchmarks, demonstrating the effectiveness of tool augmented synthetic data and adaptive retrieval and zoom reasoning for long-form video understanding.
HardcoreLogic: Challenging Large Reasoning Models with Long-tail Logic Puzzle Games
Oct 14, 2025Large Reasoning Models (LRMs) have demonstrated impressive performance on complex tasks, including logical puzzle games that require deriving solutions satisfying all constraints. However, whether they can flexibly apply appropriate rules to varying conditions, particularly when faced with non-canonical game variants, remains an open question. Existing corpora focus on popular puzzles like 9x9 Sudoku, risking overfitting to canonical formats and memorization of solution patterns, which can mask deficiencies in understanding novel rules or adapting strategies to new variants. To address this, we introduce HardcoreLogic, a challenging benchmark of over 5,000 puzzles across 10 games, designed to test the robustness of LRMs on the "long-tail" of logical games. HardcoreLogic systematically transforms canonical puzzles through three dimensions: Increased Complexity (IC), Uncommon Elements (UE), and Unsolvable Puzzles (UP), reducing reliance on shortcut memorization. Evaluations on a diverse set of LRMs reveal significant performance drops, even for models achieving top scores on existing benchmarks, indicating heavy reliance on memorized stereotypes. While increased complexity is the dominant source of difficulty, models also struggle with subtle rule variations that do not necessarily increase puzzle difficulty. Our systematic error analysis on solvable and unsolvable puzzles further highlights gaps in genuine reasoning. Overall, HardcoreLogic exposes the limitations of current LRMs and establishes a benchmark for advancing high-level logical reasoning.
Is PRM Necessary? Problem-Solving RL Implicitly Induces PRM Capability in LLMs
May 16, 2025The development of reasoning capabilities represents a critical frontier in large language models (LLMs) research, where reinforcement learning (RL) and process reward models (PRMs) have emerged as predominant methodological frameworks. Contrary to conventional wisdom, empirical evidence from DeepSeek-R1 demonstrates that pure RL training focused on mathematical problem-solving can progressively enhance reasoning abilities without PRM integration, challenging the perceived necessity of process supervision. In this study, we conduct a systematic investigation of the relationship between RL training and PRM capabilities. Our findings demonstrate that problem-solving proficiency and process supervision capabilities represent complementary dimensions of reasoning that co-evolve synergistically during pure RL training. In particular, current PRMs underperform simple baselines like majority voting when applied to state-of-the-art models such as DeepSeek-R1 and QwQ-32B. To address this limitation, we propose Self-PRM, an introspective framework in which models autonomously evaluate and rerank their generated solutions through self-reward mechanisms. Although Self-PRM consistently improves the accuracy of the benchmark (particularly with larger sample sizes), analysis exposes persistent challenges: The approach exhibits low precision (<10\%) on difficult problems, frequently misclassifying flawed solutions as valid. These analyses underscore the need for continued RL scaling to improve reward alignment and introspective accuracy. Overall, our findings suggest that PRM may not be essential for enhancing complex reasoning, as pure RL not only improves problem-solving skills but also inherently fosters robust PRM capabilities. We hope these findings provide actionable insights for building more reliable and self-aware complex reasoning models.
VCBench: A Controllable Benchmark for Symbolic and Abstract Challenges in Video Cognition
Nov 14, 2024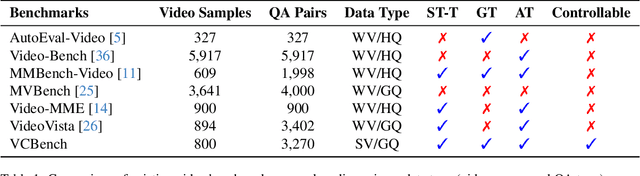
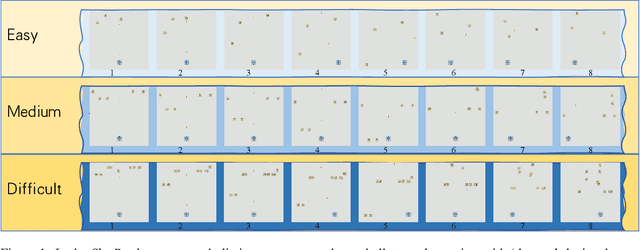
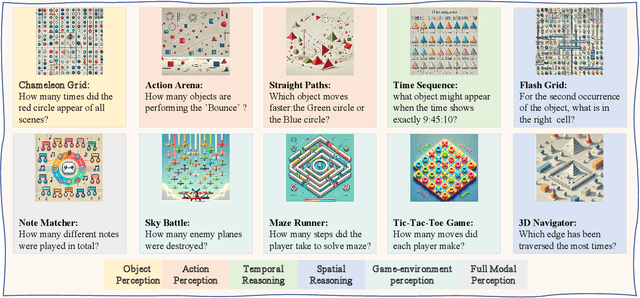
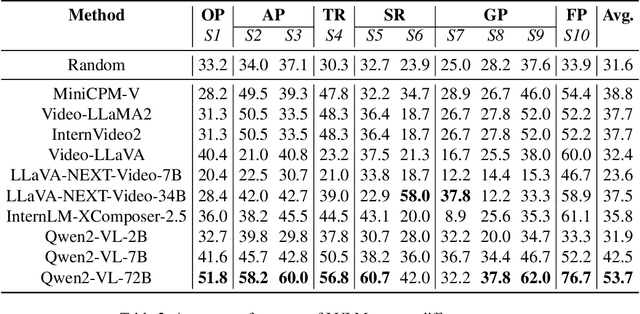
Recent advancements in Large Video-Language Models (LVLMs) have driven the development of benchmarks designed to assess cognitive abilities in video-based tasks. However, most existing benchmarks heavily rely on web-collected videos paired with human annotations or model-generated questions, which limit control over the video content and fall short in evaluating advanced cognitive abilities involving symbolic elements and abstract concepts. To address these limitations, we introduce VCBench, a controllable benchmark to assess LVLMs' cognitive abilities, involving symbolic and abstract concepts at varying difficulty levels. By generating video data with the Python-based engine, VCBench allows for precise control over the video content, creating dynamic, task-oriented videos that feature complex scenes and abstract concepts. Each task pairs with tailored question templates that target specific cognitive challenges, providing a rigorous evaluation test. Our evaluation reveals that even state-of-the-art (SOTA) models, such as Qwen2-VL-72B, struggle with simple video cognition tasks involving abstract concepts, with performance sharply dropping by 19% as video complexity rises. These findings reveal the current limitations of LVLMs in advanced cognitive tasks and highlight the critical role of VCBench in driving research toward more robust LVLMs for complex video cognition challenges.
Optimizing Instruction Synthesis: Effective Exploration of Evolutionary Space with Tree Search
Oct 14, 2024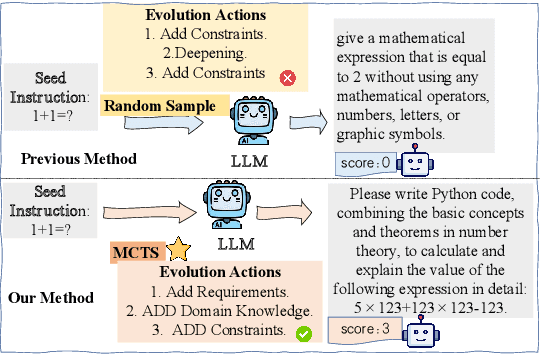
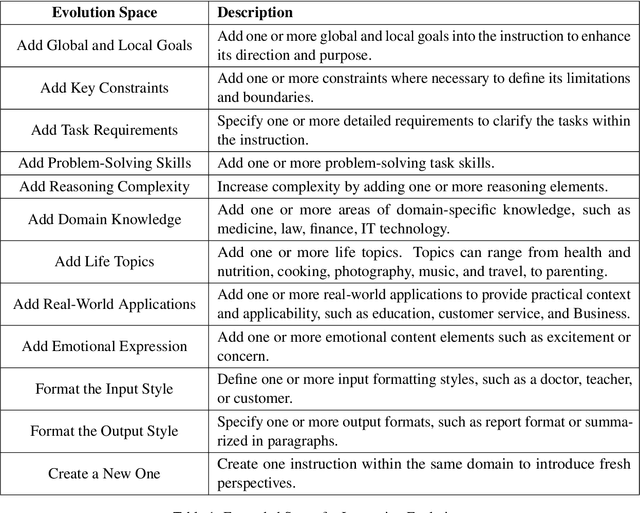

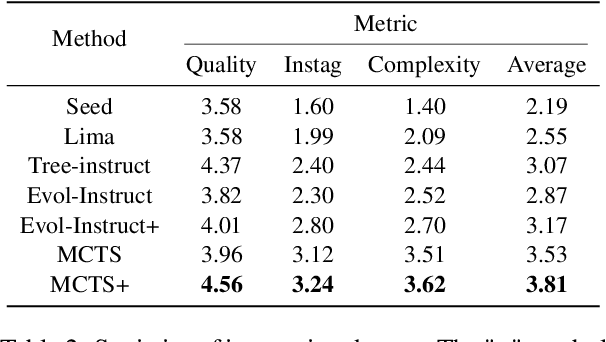
Instruction tuning is a crucial technique for aligning language models with humans' actual goals in the real world. Extensive research has highlighted the quality of instruction data is essential for the success of this alignment. However, creating high-quality data manually is labor-intensive and time-consuming, which leads researchers to explore using LLMs to synthesize data. Recent studies have focused on using a stronger LLM to iteratively enhance existing instruction data, showing promising results. Nevertheless, previous work often lacks control over the evolution direction, resulting in high uncertainty in the data synthesis process and low-quality instructions. In this paper, we introduce a general and scalable framework, IDEA-MCTS (Instruction Data Enhancement using Monte Carlo Tree Search), a scalable framework for efficiently synthesizing instructions. With tree search and evaluation models, it can efficiently guide each instruction to evolve into a high-quality form, aiding in instruction fine-tuning. Experimental results show that IDEA-MCTS significantly enhances the seed instruction data, raising the average evaluation scores of quality, diversity, and complexity from 2.19 to 3.81. Furthermore, in open-domain benchmarks, experimental results show that IDEA-MCTS improves the accuracy of real-world instruction-following skills in LLMs by an average of 5\% in low-resource settings.
Role-RL: Online Long-Context Processing with Role Reinforcement Learning for Distinct LLMs in Their Optimal Roles
Sep 26, 2024



Large language models (LLMs) with long-context processing are still challenging because of their implementation complexity, training efficiency and data sparsity. To address this issue, a new paradigm named Online Long-context Processing (OLP) is proposed when we process a document of unlimited length, which typically occurs in the information reception and organization of diverse streaming media such as automated news reporting, live e-commerce, and viral short videos. Moreover, a dilemma was often encountered when we tried to select the most suitable LLM from a large number of LLMs amidst explosive growth aiming for outstanding performance, affordable prices, and short response delays. In view of this, we also develop Role Reinforcement Learning (Role-RL) to automatically deploy different LLMs in their respective roles within the OLP pipeline according to their actual performance. Extensive experiments are conducted on our OLP-MINI dataset and it is found that OLP with Role-RL framework achieves OLP benchmark with an average recall rate of 93.2% and the LLM cost saved by 79.4%. The code and dataset are publicly available at: https://anonymous.4open.science/r/Role-RL.
BeamAggR: Beam Aggregation Reasoning over Multi-source Knowledge for Multi-hop Question Answering
Jun 28, 2024



Large language models (LLMs) have demonstrated strong reasoning capabilities. Nevertheless, they still suffer from factual errors when tackling knowledge-intensive tasks. Retrieval-augmented reasoning represents a promising approach. However, significant challenges still persist, including inaccurate and insufficient retrieval for complex questions, as well as difficulty in integrating multi-source knowledge. To address this, we propose Beam Aggregation Reasoning, BeamAggR, a reasoning framework for knowledge-intensive multi-hop QA. BeamAggR explores and prioritizes promising answers at each hop of question. Concretely, we parse the complex questions into trees, which include atom and composite questions, followed by bottom-up reasoning. For atomic questions, the LLM conducts reasoning on multi-source knowledge to get answer candidates. For composite questions, the LLM combines beam candidates, explores multiple reasoning paths through probabilistic aggregation, and prioritizes the most promising trajectory. Extensive experiments on four open-domain multi-hop reasoning datasets show that our method significantly outperforms SOTA methods by 8.5%. Furthermore, our analysis reveals that BeamAggR elicits better knowledge collaboration and answer aggregation.
An Information Bottleneck Perspective for Effective Noise Filtering on Retrieval-Augmented Generation
Jun 03, 2024



Retrieval-augmented generation integrates the capabilities of large language models with relevant information retrieved from an extensive corpus, yet encounters challenges when confronted with real-world noisy data. One recent solution is to train a filter module to find relevant content but only achieve suboptimal noise compression. In this paper, we propose to introduce the information bottleneck theory into retrieval-augmented generation. Our approach involves the filtration of noise by simultaneously maximizing the mutual information between compression and ground output, while minimizing the mutual information between compression and retrieved passage. In addition, we derive the formula of information bottleneck to facilitate its application in novel comprehensive evaluations, the selection of supervised fine-tuning data, and the construction of reinforcement learning rewards. Experimental results demonstrate that our approach achieves significant improvements across various question answering datasets, not only in terms of the correctness of answer generation but also in the conciseness with $2.5\%$ compression rate.
Divide-and-Conquer Meets Consensus: Unleashing the Power of Functions in Code Generation
May 30, 2024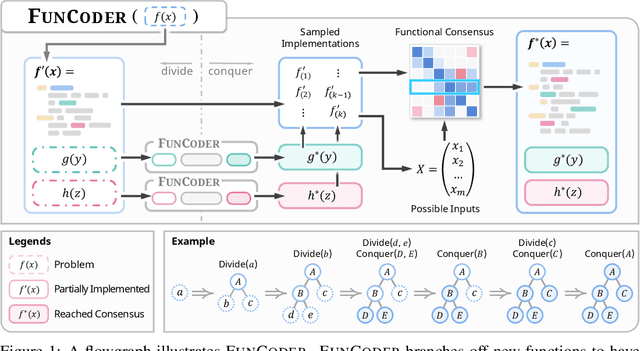
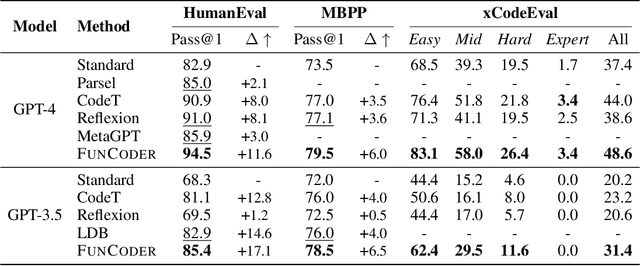


Despite recent progress made by large language models in code generation, they still struggle with programs that meet complex requirements. Recent work utilizes plan-and-solve decomposition to decrease the complexity and leverage self-tests to refine the generated program. Yet, planning deep-inside requirements in advance can be challenging, and the tests need to be accurate to accomplish self-improvement. To this end, we propose FunCoder, a code generation framework incorporating the divide-and-conquer strategy with functional consensus. Specifically, FunCoder recursively branches off sub-functions as smaller goals during code generation, represented by a tree hierarchy. These sub-functions are then composited to attain more complex objectives. Additionally, we designate functions via a consensus formed by identifying similarities in program behavior, mitigating error propagation. FunCoder outperforms state-of-the-art methods by +9.8% on average in HumanEval, MBPP, xCodeEval and MATH with GPT-3.5 and GPT-4. Moreover, our method demonstrates superiority on smaller models: With FunCoder, StableCode-3b surpasses GPT-3.5 by +18.6% and achieves 97.7% of GPT-4's performance on HumanEval. Further analysis reveals that our proposed dynamic function decomposition is capable of handling complex requirements, and the functional consensus prevails over self-testing in correctness evaluation.
Apollo's Oracle: Retrieval-Augmented Reasoning in Multi-Agent Debates
Dec 08, 2023



Multi-agent debate systems are designed to derive accurate and consistent conclusions through adversarial interactions among agents. However, these systems often encounter challenges due to cognitive constraints, manifesting as (1) agents' obstinate adherence to incorrect viewpoints and (2) their propensity to abandon correct viewpoints. These issues are primarily responsible for the ineffectiveness of such debates. Addressing the challenge of cognitive constraints, we introduce a novel framework, the Multi-Agent Debate with Retrieval Augmented (MADRA). MADRA incorporates retrieval of prior knowledge into the debate process, effectively breaking cognitive constraints and enhancing the agents' reasoning capabilities. Furthermore, we have developed a self-selection module within this framework, enabling agents to autonomously select pertinent evidence, thereby minimizing the impact of irrelevant or noisy data. We have comprehensively tested and analyzed MADRA across six diverse datasets. The experimental results demonstrate that our approach significantly enhances performance across various tasks, proving the effectiveness of our proposed method.