 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVReST: Enhancing Reasoning in Large Vision-Language Models through Tree Search and Self-Reward Mechanism
Jun 10, 2025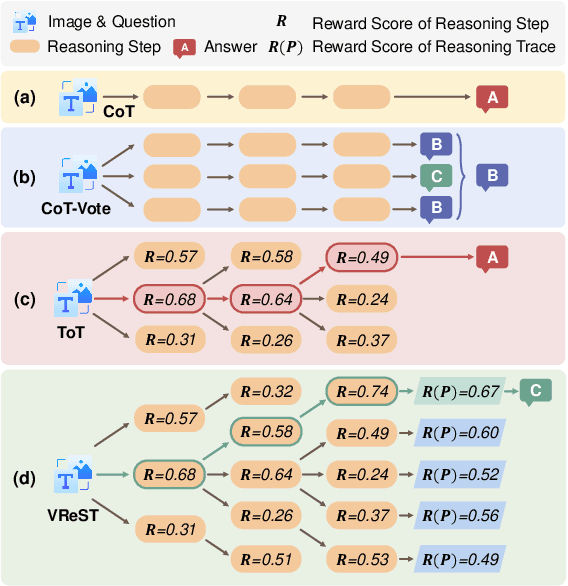
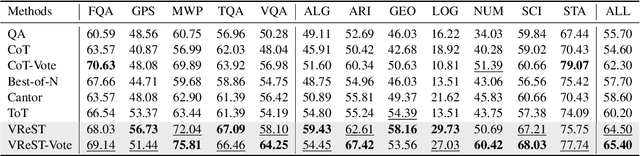
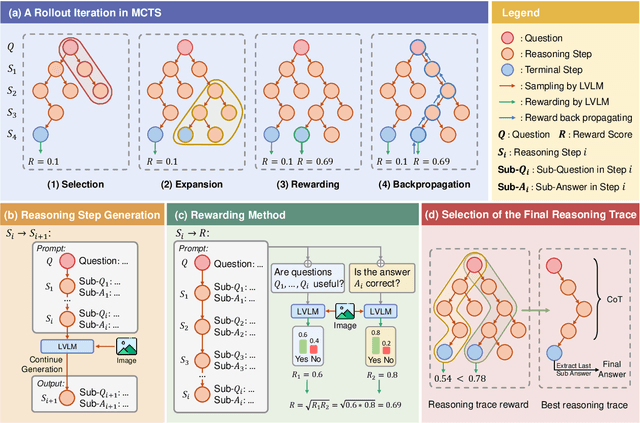
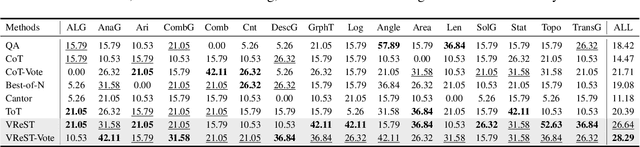
Large Vision-Language Models (LVLMs) have shown exceptional performance in multimodal tasks, but their effectiveness in complex visual reasoning is still constrained, especially when employing Chain-of-Thought prompting techniques. In this paper, we propose VReST, a novel training-free approach that enhances Reasoning in LVLMs through Monte Carlo Tree Search and Self-Reward mechanisms. VReST meticulously traverses the reasoning landscape by establishing a search tree, where each node encapsulates a reasoning step, and each path delineates a comprehensive reasoning sequence. Our innovative multimodal Self-Reward mechanism assesses the quality of reasoning steps by integrating the utility of sub-questions, answer correctness, and the relevance of vision-language clues, all without the need for additional models. VReST surpasses current prompting methods and secures state-of-the-art performance across three multimodal mathematical reasoning benchmarks. Furthermore, it substantiates the efficacy of test-time scaling laws in multimodal tasks, offering a promising direction for future research.
MuseFace: Text-driven Face Editing via Diffusion-based Mask Generation Approach
Mar 31, 2025
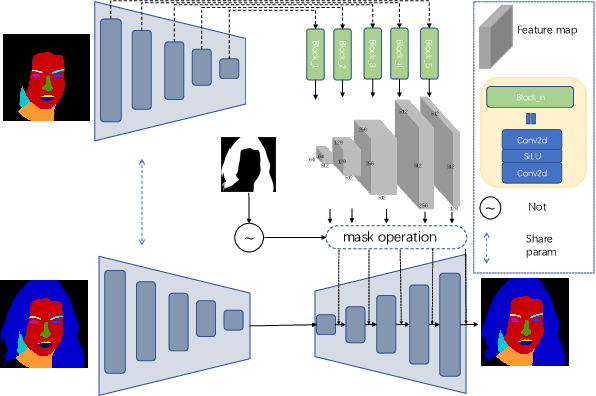
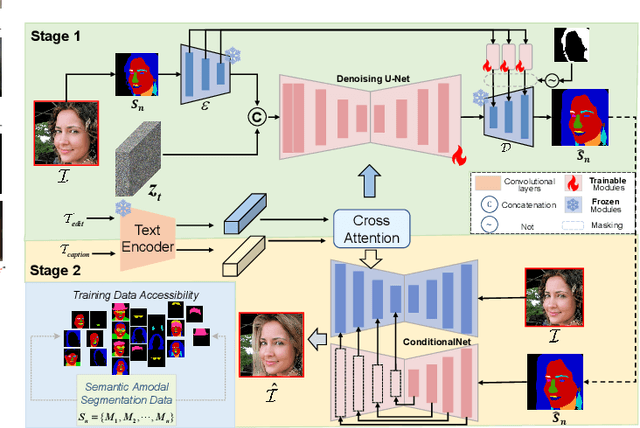
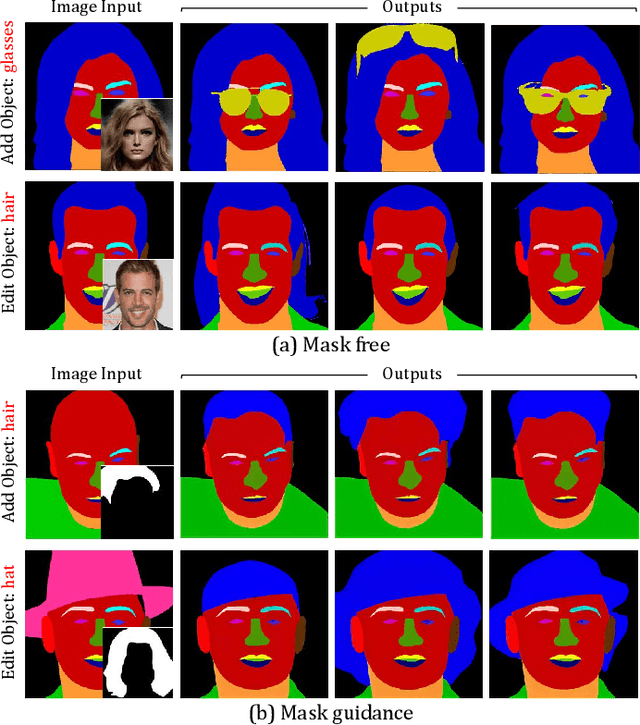
Face editing modifies the appearance of face, which plays a key role in customization and enhancement of personal images. Although much work have achieved remarkable success in text-driven face editing, they still face significant challenges as none of them simultaneously fulfill the characteristics of diversity, controllability and flexibility. To address this challenge, we propose MuseFace, a text-driven face editing framework, which relies solely on text prompt to enable face editing. Specifically, MuseFace integrates a Text-to-Mask diffusion model and a semantic-aware face editing model, capable of directly generating fine-grained semantic masks from text and performing face editing. The Text-to-Mask diffusion model provides \textit{diversity} and \textit{flexibility} to the framework, while the semantic-aware face editing model ensures \textit{controllability} of the framework. Our framework can create fine-grained semantic masks, making precise face editing possible, and significantly enhancing the controllability and flexibility of face editing models. Extensive experiments demonstrate that MuseFace achieves superior high-fidelity performance.
Solving the Catastrophic Forgetting Problem in Generalized Category Discovery
Jan 09, 2025Generalized Category Discovery (GCD) aims to identify a mix of known and novel categories within unlabeled data sets, providing a more realistic setting for image recognition. Essentially, GCD needs to remember existing patterns thoroughly to recognize novel categories. Recent state-of-the-art method SimGCD transfers the knowledge from known-class data to the learning of novel classes through debiased learning. However, some patterns are catastrophically forgot during adaptation and thus lead to poor performance in novel categories classification. To address this issue, we propose a novel learning approach, LegoGCD, which is seamlessly integrated into previous methods to enhance the discrimination of novel classes while maintaining performance on previously encountered known classes. Specifically, we design two types of techniques termed as Local Entropy Regularization (LER) and Dual-views Kullback Leibler divergence constraint (DKL). The LER optimizes the distribution of potential known class samples in unlabeled data, thus ensuring the preservation of knowledge related to known categories while learning novel classes. Meanwhile, DKL introduces Kullback Leibler divergence to encourage the model to produce a similar prediction distribution of two view samples from the same image. In this way, it successfully avoids mismatched prediction and generates more reliable potential known class samples simultaneously. Extensive experiments validate that the proposed LegoGCD effectively addresses the known category forgetting issue across all datasets, eg, delivering a 7.74% and 2.51% accuracy boost on known and novel classes in CUB, respectively. Our code is available at: https://github.com/Cliffia123/LegoGCD.
PointTalk: Audio-Driven Dynamic Lip Point Cloud for 3D Gaussian-based Talking Head Synthesis
Dec 11, 2024



Talking head synthesis with arbitrary speech audio is a crucial challenge in the field of digital humans. Recently, methods based on radiance fields have received increasing attention due to their ability to synthesize high-fidelity and identity-consistent talking heads from just a few minutes of training video. However, due to the limited scale of the training data, these methods often exhibit poor performance in audio-lip synchronization and visual quality. In this paper, we propose a novel 3D Gaussian-based method called PointTalk, which constructs a static 3D Gaussian field of the head and deforms it in sync with the audio. It also incorporates an audio-driven dynamic lip point cloud as a critical component of the conditional information, thereby facilitating the effective synthesis of talking heads. Specifically, the initial step involves generating the corresponding lip point cloud from the audio signal and capturing its topological structure. The design of the dynamic difference encoder aims to capture the subtle nuances inherent in dynamic lip movements more effectively. Furthermore, we integrate the audio-point enhancement module, which not only ensures the synchronization of the audio signal with the corresponding lip point cloud within the feature space, but also facilitates a deeper understanding of the interrelations among cross-modal conditional features. Extensive experiments demonstrate that our method achieves superior high-fidelity and audio-lip synchronization in talking head synthesis compared to previous methods.
Learning Fine-Grained Grounded Citations for Attributed Large Language Models
Aug 08, 2024Despite the impressive performance on information-seeking tasks, large language models (LLMs) still struggle with hallucinations. Attributed LLMs, which augment generated text with in-line citations, have shown potential in mitigating hallucinations and improving verifiability. However, current approaches suffer from suboptimal citation quality due to their reliance on in-context learning. Furthermore, the practice of citing only coarse document identifiers makes it challenging for users to perform fine-grained verification. In this work, we introduce FRONT, a training framework designed to teach LLMs to generate Fine-Grained Grounded Citations. By grounding model outputs in fine-grained supporting quotes, these quotes guide the generation of grounded and consistent responses, not only improving citation quality but also facilitating fine-grained verification. Experiments on the ALCE benchmark demonstrate the efficacy of FRONT in generating superior grounded responses and highly supportive citations. With LLaMA-2-7B, the framework significantly outperforms all the baselines, achieving an average of 14.21% improvement in citation quality across all datasets, even surpassing ChatGPT.
BeamAggR: Beam Aggregation Reasoning over Multi-source Knowledge for Multi-hop Question Answering
Jun 28, 2024



Large language models (LLMs) have demonstrated strong reasoning capabilities. Nevertheless, they still suffer from factual errors when tackling knowledge-intensive tasks. Retrieval-augmented reasoning represents a promising approach. However, significant challenges still persist, including inaccurate and insufficient retrieval for complex questions, as well as difficulty in integrating multi-source knowledge. To address this, we propose Beam Aggregation Reasoning, BeamAggR, a reasoning framework for knowledge-intensive multi-hop QA. BeamAggR explores and prioritizes promising answers at each hop of question. Concretely, we parse the complex questions into trees, which include atom and composite questions, followed by bottom-up reasoning. For atomic questions, the LLM conducts reasoning on multi-source knowledge to get answer candidates. For composite questions, the LLM combines beam candidates, explores multiple reasoning paths through probabilistic aggregation, and prioritizes the most promising trajectory. Extensive experiments on four open-domain multi-hop reasoning datasets show that our method significantly outperforms SOTA methods by 8.5%. Furthermore, our analysis reveals that BeamAggR elicits better knowledge collaboration and answer aggregation.
Stable Diffusion Segmentation for Biomedical Images with Single-step Reverse Process
Jun 27, 2024



Diffusion models have demonstrated their effectiveness across various generative tasks. However, when applied to medical image segmentation, these models encounter several challenges, including significant resource and time requirements. They also necessitate a multi-step reverse process and multiple samples to produce reliable predictions. To address these challenges, we introduce the first latent diffusion segmentation model, named SDSeg, built upon stable diffusion (SD). SDSeg incorporates a straightforward latent estimation strategy to facilitate a single-step reverse process and utilizes latent fusion concatenation to remove the necessity for multiple samples. Extensive experiments indicate that SDSeg surpasses existing state-of-the-art methods on five benchmark datasets featuring diverse imaging modalities. Remarkably, SDSeg is capable of generating stable predictions with a solitary reverse step and sample, epitomizing the model's stability as implied by its name. The code is available at https://github.com/lin-tianyu/Stable-Diffusion-Seg
An Information Bottleneck Perspective for Effective Noise Filtering on Retrieval-Augmented Generation
Jun 03, 2024



Retrieval-augmented generation integrates the capabilities of large language models with relevant information retrieved from an extensive corpus, yet encounters challenges when confronted with real-world noisy data. One recent solution is to train a filter module to find relevant content but only achieve suboptimal noise compression. In this paper, we propose to introduce the information bottleneck theory into retrieval-augmented generation. Our approach involves the filtration of noise by simultaneously maximizing the mutual information between compression and ground output, while minimizing the mutual information between compression and retrieved passage. In addition, we derive the formula of information bottleneck to facilitate its application in novel comprehensive evaluations, the selection of supervised fine-tuning data, and the construction of reinforcement learning rewards. Experimental results demonstrate that our approach achieves significant improvements across various question answering datasets, not only in terms of the correctness of answer generation but also in the conciseness with $2.5\%$ compression rate.
Exploring Low-Resource Medical Image Classification with Weakly Supervised Prompt Learning
Feb 06, 2024Most advances in medical image recognition supporting clinical auxiliary diagnosis meet challenges due to the low-resource situation in the medical field, where annotations are highly expensive and professional. This low-resource problem can be alleviated by leveraging the transferable representations of large-scale pre-trained vision-language models via relevant medical text prompts. However, existing pre-trained vision-language models require domain experts to carefully design the medical prompts, which greatly increases the burden on clinicians. To address this problem, we propose a weakly supervised prompt learning method MedPrompt to automatically generate medical prompts, which includes an unsupervised pre-trained vision-language model and a weakly supervised prompt learning model. The unsupervised pre-trained vision-language model utilizes the natural correlation between medical images and corresponding medical texts for pre-training, without any manual annotations. The weakly supervised prompt learning model only utilizes the classes of images in the dataset to guide the learning of the specific class vector in the prompt, while the learning of other context vectors in the prompt requires no manual annotations for guidance. To the best of our knowledge, this is the first model to automatically generate medical prompts. With these prompts, the pre-trained vision-language model can be freed from the strong expert dependency of manual annotation and manual prompt design. Experimental results show that the model using our automatically generated prompts outperforms its full-shot learning hand-crafted prompts counterparts with only a minimal number of labeled samples for few-shot learning, and reaches superior or comparable accuracy on zero-shot image classification. The proposed prompt generator is lightweight and therefore can be embedded into any network architecture.
Intensive Vision-guided Network for Radiology Report Generation
Feb 06, 2024Automatic radiology report generation is booming due to its huge application potential for the healthcare industry. However, existing computer vision and natural language processing approaches to tackle this problem are limited in two aspects. First, when extracting image features, most of them neglect multi-view reasoning in vision and model single-view structure of medical images, such as space-view or channel-view. However, clinicians rely on multi-view imaging information for comprehensive judgment in daily clinical diagnosis. Second, when generating reports, they overlook context reasoning with multi-modal information and focus on pure textual optimization utilizing retrieval-based methods. We aim to address these two issues by proposing a model that better simulates clinicians' perspectives and generates more accurate reports. Given the above limitation in feature extraction, we propose a Globally-intensive Attention (GIA) module in the medical image encoder to simulate and integrate multi-view vision perception. GIA aims to learn three types of vision perception: depth view, space view, and pixel view. On the other hand, to address the above problem in report generation, we explore how to involve multi-modal signals to generate precisely matched reports, i.e., how to integrate previously predicted words with region-aware visual content in next word prediction. Specifically, we design a Visual Knowledge-guided Decoder (VKGD), which can adaptively consider how much the model needs to rely on visual information and previously predicted text to assist next word prediction. Hence, our final Intensive Vision-guided Network (IVGN) framework includes a GIA-guided Visual Encoder and the VKGD. Experiments on two commonly-used datasets IU X-Ray and MIMIC-CXR demonstrate the superior ability of our method compared with other state-of-the-art approaches.