 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEFIM: Efficient Serving of LLMs for Infilling Tasks with Improved KV Cache Reuse
May 29, 2025Large language models (LLMs) are often used for infilling tasks, which involve predicting or generating missing information in a given text. These tasks typically require multiple interactions with similar context. To reduce the computation of repeated historical tokens, cross-request key-value (KV) cache reuse, a technique that stores and reuses intermediate computations, has become a crucial method in multi-round interactive services. However, in infilling tasks, the KV cache reuse is often hindered by the structure of the prompt format, which typically consists of a prefix and suffix relative to the insertion point. Specifically, the KV cache of the prefix or suffix part is frequently invalidated as the other part (suffix or prefix) is incrementally generated. To address the issue, we propose EFIM, a transformed prompt format of FIM to unleash the performance potential of KV cache reuse. Although the transformed prompt can solve the inefficiency, it exposes subtoken generation problems in current LLMs, where they have difficulty generating partial words accurately. Therefore, we introduce a fragment tokenization training method which splits text into multiple fragments before tokenization during data processing. Experiments on two representative LLMs show that LLM serving with EFIM can lower the latency by 52% and improve the throughput by 98% while maintaining the original infilling capability. EFIM's source code is publicly available at https://github.com/gty111/EFIM.
Exploring Low-Resource Medical Image Classification with Weakly Supervised Prompt Learning
Feb 06, 2024Most advances in medical image recognition supporting clinical auxiliary diagnosis meet challenges due to the low-resource situation in the medical field, where annotations are highly expensive and professional. This low-resource problem can be alleviated by leveraging the transferable representations of large-scale pre-trained vision-language models via relevant medical text prompts. However, existing pre-trained vision-language models require domain experts to carefully design the medical prompts, which greatly increases the burden on clinicians. To address this problem, we propose a weakly supervised prompt learning method MedPrompt to automatically generate medical prompts, which includes an unsupervised pre-trained vision-language model and a weakly supervised prompt learning model. The unsupervised pre-trained vision-language model utilizes the natural correlation between medical images and corresponding medical texts for pre-training, without any manual annotations. The weakly supervised prompt learning model only utilizes the classes of images in the dataset to guide the learning of the specific class vector in the prompt, while the learning of other context vectors in the prompt requires no manual annotations for guidance. To the best of our knowledge, this is the first model to automatically generate medical prompts. With these prompts, the pre-trained vision-language model can be freed from the strong expert dependency of manual annotation and manual prompt design. Experimental results show that the model using our automatically generated prompts outperforms its full-shot learning hand-crafted prompts counterparts with only a minimal number of labeled samples for few-shot learning, and reaches superior or comparable accuracy on zero-shot image classification. The proposed prompt generator is lightweight and therefore can be embedded into any network architecture.
Intensive Vision-guided Network for Radiology Report Generation
Feb 06, 2024Automatic radiology report generation is booming due to its huge application potential for the healthcare industry. However, existing computer vision and natural language processing approaches to tackle this problem are limited in two aspects. First, when extracting image features, most of them neglect multi-view reasoning in vision and model single-view structure of medical images, such as space-view or channel-view. However, clinicians rely on multi-view imaging information for comprehensive judgment in daily clinical diagnosis. Second, when generating reports, they overlook context reasoning with multi-modal information and focus on pure textual optimization utilizing retrieval-based methods. We aim to address these two issues by proposing a model that better simulates clinicians' perspectives and generates more accurate reports. Given the above limitation in feature extraction, we propose a Globally-intensive Attention (GIA) module in the medical image encoder to simulate and integrate multi-view vision perception. GIA aims to learn three types of vision perception: depth view, space view, and pixel view. On the other hand, to address the above problem in report generation, we explore how to involve multi-modal signals to generate precisely matched reports, i.e., how to integrate previously predicted words with region-aware visual content in next word prediction. Specifically, we design a Visual Knowledge-guided Decoder (VKGD), which can adaptively consider how much the model needs to rely on visual information and previously predicted text to assist next word prediction. Hence, our final Intensive Vision-guided Network (IVGN) framework includes a GIA-guided Visual Encoder and the VKGD. Experiments on two commonly-used datasets IU X-Ray and MIMIC-CXR demonstrate the superior ability of our method compared with other state-of-the-art approaches.
AdaNAS: Adaptively Post-processing with Self-supervised Neural Architecture Search for Ensemble Rainfall Forecasts
Dec 26, 2023



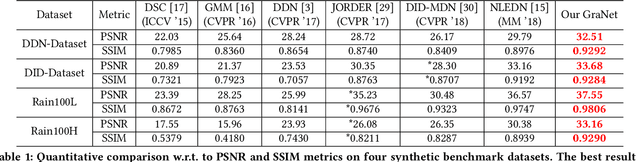
Previous post-processing studies on rainfall forecasts using numerical weather prediction (NWP) mainly focus on statistics-based aspects, while learning-based aspects are rarely investigated. Although some manually-designed models are proposed to raise accuracy, they are customized networks, which need to be repeatedly tried and verified, at a huge cost in time and labor. Therefore, a self-supervised neural architecture search (NAS) method without significant manual efforts called AdaNAS is proposed in this study to perform rainfall forecast post-processing and predict rainfall with high accuracy. In addition, we design a rainfall-aware search space to significantly improve forecasts for high-rainfall areas. Furthermore, we propose a rainfall-level regularization function to eliminate the effect of noise data during the training. Validation experiments have been performed under the cases of \emph{None}, \emph{Light}, \emph{Moderate}, \emph{Heavy} and \emph{Violent} on a large-scale precipitation benchmark named TIGGE. Finally, the average mean-absolute error (MAE) and average root-mean-square error (RMSE) of the proposed AdaNAS model are 0.98 and 2.04 mm/day, respectively. Additionally, the proposed AdaNAS model is compared with other neural architecture search methods and previous studies. Compared results reveal the satisfactory performance and superiority of the proposed AdaNAS model in terms of precipitation amount prediction and intensity classification. Concretely, the proposed AdaNAS model outperformed previous best-performing manual methods with MAE and RMSE improving by 80.5\% and 80.3\%, respectively.
Hybrid Reasoning Network for Video-based Commonsense Captioning
Aug 05, 2021The task of video-based commonsense captioning aims to generate event-wise captions and meanwhile provide multiple commonsense descriptions (e.g., attribute, effect and intention) about the underlying event in the video. Prior works explore the commonsense captions by using separate networks for different commonsense types, which is time-consuming and lacks mining the interaction of different commonsense. In this paper, we propose a Hybrid Reasoning Network (HybridNet) to endow the neural networks with the capability of semantic-level reasoning and word-level reasoning. Firstly, we develop multi-commonsense learning for semantic-level reasoning by jointly training different commonsense types in a unified network, which encourages the interaction between the clues of multiple commonsense descriptions, event-wise captions and videos. Then, there are two steps to achieve the word-level reasoning: (1) a memory module records the history predicted sequence from the previous generation processes; (2) a memory-routed multi-head attention (MMHA) module updates the word-level attention maps by incorporating the history information from the memory module into the transformer decoder for word-level reasoning. Moreover, the multimodal features are used to make full use of diverse knowledge for commonsense reasoning. Experiments and abundant analysis on the large-scale Video-to-Commonsense benchmark show that our HybridNet achieves state-of-the-art performance compared with other methods.
ElixirNet: Relation-aware Network Architecture Adaptation for Medical Lesion Detection
Mar 03, 2020
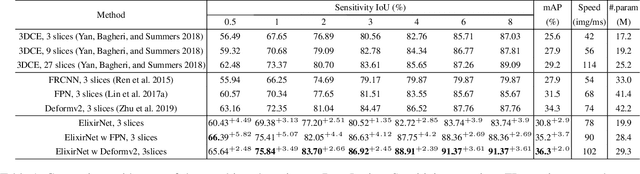

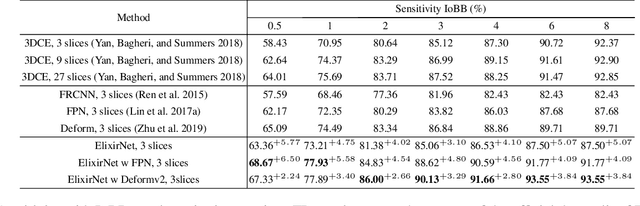
Most advances in medical lesion detection network are limited to subtle modification on the conventional detection network designed for natural images. However, there exists a vast domain gap between medical images and natural images where the medical image detection often suffers from several domain-specific challenges, such as high lesion/background similarity, dominant tiny lesions, and severe class imbalance. Is a hand-crafted detection network tailored for natural image undoubtedly good enough over a discrepant medical lesion domain? Is there more powerful operations, filters, and sub-networks that better fit the medical lesion detection problem to be discovered? In this paper, we introduce a novel ElixirNet that includes three components: 1) TruncatedRPN balances positive and negative data for false positive reduction; 2) Auto-lesion Block is automatically customized for medical images to incorporate relation-aware operations among region proposals, and leads to more suitable and efficient classification and localization. 3) Relation transfer module incorporates the semantic relationship and transfers the relevant contextual information with an interpretable the graph thus alleviates the problem of lack of annotations for all types of lesions. Experiments on DeepLesion and Kits19 prove the effectiveness of ElixirNet, achieving improvement of both sensitivity and precision over FPN with fewer parameters.
Heterogeneous Graph Learning for Visual Commonsense Reasoning
Oct 25, 2019

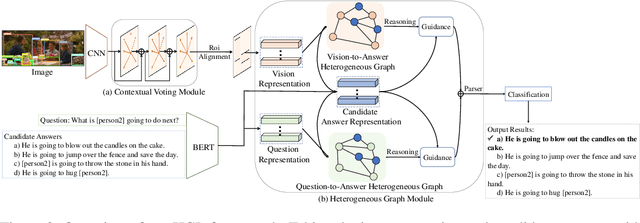

Visual commonsense reasoning task aims at leading the research field into solving cognition-level reasoning with the ability of predicting correct answers and meanwhile providing convincing reasoning paths, resulting in three sub-tasks i.e., Q->A, QA->R and Q->AR. It poses great challenges over the proper semantic alignment between vision and linguistic domains and knowledge reasoning to generate persuasive reasoning paths. Existing works either resort to a powerful end-to-end network that cannot produce interpretable reasoning paths or solely explore intra-relationship of visual objects (homogeneous graph) while ignoring the cross-domain semantic alignment among visual concepts and linguistic words. In this paper, we propose a new Heterogeneous Graph Learning (HGL) framework for seamlessly integrating the intra-graph and inter-graph reasoning in order to bridge vision and language domain. Our HGL consists of a primal vision-to-answer heterogeneous graph (VAHG) module and a dual question-to-answer heterogeneous graph (QAHG) module to interactively refine reasoning paths for semantic agreement. Moreover, our HGL integrates a contextual voting module to exploit a long-range visual context for better global reasoning. Experiments on the large-scale Visual Commonsense Reasoning benchmark demonstrate the superior performance of our proposed modules on three tasks (improving 5% accuracy on Q->A, 3.5% on QA->R, 5.8% on Q->AR)
Layout-Graph Reasoning for Fashion Landmark Detection
Oct 04, 2019
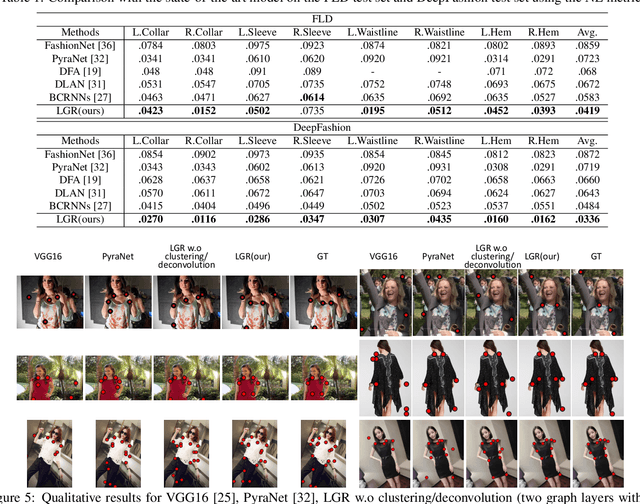

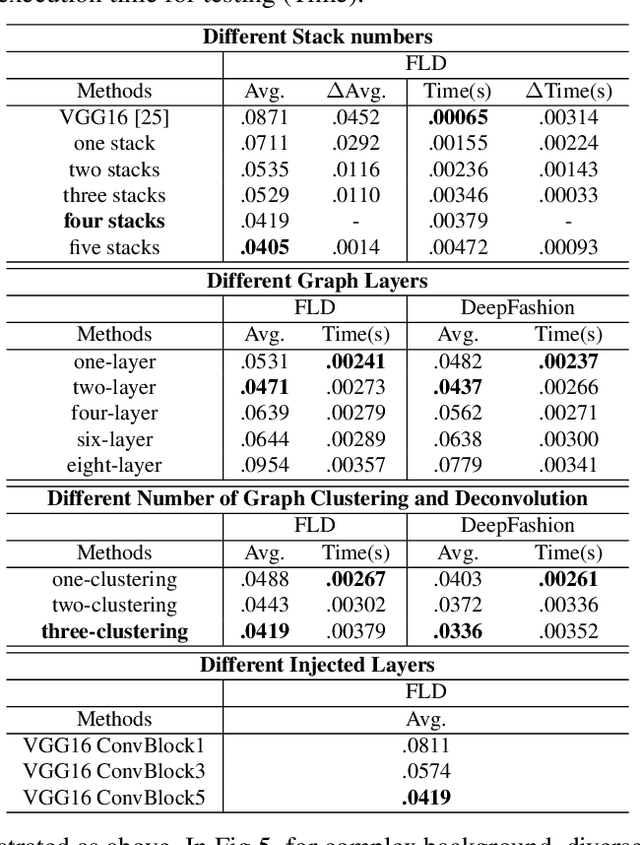
Detecting dense landmarks for diverse clothes, as a fundamental technique for clothes analysis, has attracted increasing research attention due to its huge application potential. However, due to the lack of modeling underlying semantic layout constraints among landmarks, prior works often detect ambiguous and structure-inconsistent landmarks of multiple overlapped clothes in one person. In this paper, we propose to seamlessly enforce structural layout relationships among landmarks on the intermediate representations via multiple stacked layout-graph reasoning layers. We define the layout-graph as a hierarchical structure including a root node, body-part nodes (e.g. upper body, lower body), coarse clothes-part nodes (e.g. collar, sleeve) and leaf landmark nodes (e.g. left-collar, right-collar). Each Layout-Graph Reasoning(LGR) layer aims to map feature representations into structural graph nodes via a Map-to-Node module, performs reasoning over structural graph nodes to achieve global layout coherency via a layout-graph reasoning module, and then maps graph nodes back to enhance feature representations via a Node-to-Map module. The layout-graph reasoning module integrates a graph clustering operation to generate representations of intermediate nodes (bottom-up inference) and then a graph deconvolution operation (top-down inference) over the whole graph. Extensive experiments on two public fashion landmark datasets demonstrate the superiority of our model. Furthermore, to advance the fine-grained fashion landmark research for supporting more comprehensive clothes generation and attribute recognition, we contribute the first Fine-grained Fashion Landmark Dataset (FFLD) containing 200k images annotated with at most 32 key-points for 13 clothes types.
Gradual Network for Single Image De-raining
Sep 20, 2019


Most advances in single image de-raining meet a key challenge, which is removing rain streaks with different scales and shapes while preserving image details. Existing single image de-raining approaches treat rain-streak removal as a process of pixel-wise regression directly. However, they are lacking in mining the balance between over-de-raining (e.g. removing texture details in rain-free regions) and under-de-raining (e.g. leaving rain streaks). In this paper, we firstly propose a coarse-to-fine network called Gradual Network (GraNet) consisting of coarse stage and fine stage for delving into single image de-raining with different granularities. Specifically, to reveal coarse-grained rain-streak characteristics (e.g. long and thick rain streaks/raindrops), we propose a coarse stage by utilizing local-global spatial dependencies via a local-global subnetwork composed of region-aware blocks. Taking the residual result (the coarse de-rained result) between the rainy image sample (i.e. the input data) and the output of coarse stage (i.e. the learnt rain mask) as input, the fine stage continues to de-rain by removing the fine-grained rain streaks (e.g. light rain streaks and water mist) to get a rain-free and well-reconstructed output image via a unified contextual merging sub-network with dense blocks and a merging block. Solid and comprehensive experiments on synthetic and real data demonstrate that our GraNet can significantly outperform the state-of-the-art methods by removing rain streaks with various densities, scales and shapes while keeping the image details of rain-free regions well-preserved.
Cross-Modal Attentional Context Learning for RGB-D Object Detection
Oct 30, 2018
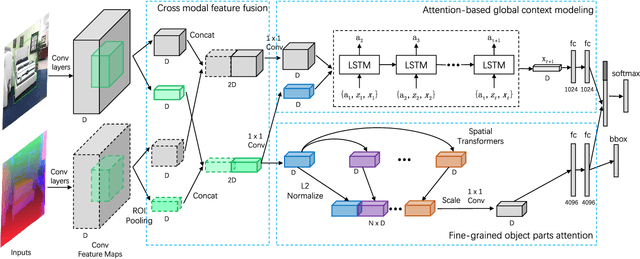
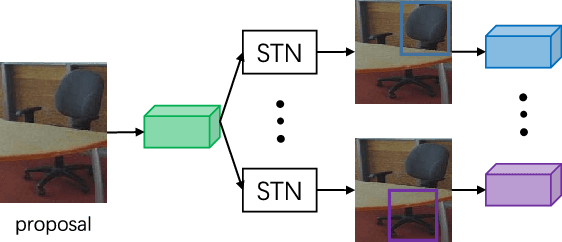
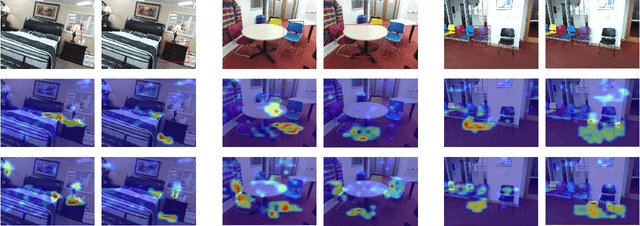
Recognizing objects from simultaneously sensed photometric (RGB) and depth channels is a fundamental yet practical problem in many machine vision applications such as robot grasping and autonomous driving. In this paper, we address this problem by developing a Cross-Modal Attentional Context (CMAC) learning framework, which enables the full exploitation of the context information from both RGB and depth data. Compared to existing RGB-D object detection frameworks, our approach has several appealing properties. First, it consists of an attention-based global context model for exploiting adaptive contextual information and incorporating this information into a region-based CNN (e.g., Fast RCNN) framework to achieve improved object detection performance. Second, our CMAC framework further contains a fine-grained object part attention module to harness multiple discriminative object parts inside each possible object region for superior local feature representation. While greatly improving the accuracy of RGB-D object detection, the effective cross-modal information fusion as well as attentional context modeling in our proposed model provide an interpretable visualization scheme. Experimental results demonstrate that the proposed method significantly improves upon the state of the art on all public benchmarks.