 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling LLM Reasoning into an Interpretable Policy Tree for Human-AI Collaboration
Jun 07, 2026Constructing efficient and reliable policies to assist humans is indispensable for human-AI collaboration. Existing methods mainly follow two lines of work. Most prior work relies on multi-agent reinforcement learning (MARL) to learn black-box policies, which limits interpretability and raises safety concerns. Recent methods query large language models (LLMs) at each decision step, causing slow responses and high inference costs. We propose Collaboration Policy Tree (Co-pi-tree), a closed-loop method that learns an executable policy tree consisting of a partner-behavior prediction tree and an agent-action selection tree. Co-pi-tree constructs a policy by distilling LLM reasoning into policy tree code. It then evaluates the policy through partner interaction, obtains feedback, and uses natural language to summarize the interaction feedback to improve problematic branches. Experiments in Overcooked-AI show that Co-pi-tree improves average reward by 35.4% over the baseline average, while reducing the number of LLM queries by 77.7% and test-time latency by 97.1%. Project page: https://beiwenzhang.github.io/Co-pi-tree/
CaMeRL: Collision-Aware and Memory-Enhanced Reinforcement Learning for UAV Navigation in Multi-Scale Obstacle Environments
May 14, 2026In obstacle avoidance navigation of unmanned aerial vehicles (UAVs), variations in obstacle scale have received strangely less attention than obstacle number or density. Existing methods typically extract purely geometric features from single-frame depth observations. Such representations tend to neglect small obstacles and lose spatial context under occlusions caused by large obstacles, leading to noticeable degradation in environments with multi-scale obstacles. To address this issue, we propose CaMeRL, a Collision-aware and Memory-enhanced Reinforcement Learning framework for UAV navigation. The collision-aware latent representation encodes risk-sensitive depth cues to preserve fine-grained obstacle structures, thereby improving sensitivity to small obstacles. The temporal memory module integrates observations across frames, mitigating partial observability caused by large-obstacle occlusions. We evaluate CaMeRL with multi-scale obstacles, including ultra-small and extra-large obstacle settings. Results show that CaMeRL outperforms state-of-the-art baselines across all scales, with success rate gains of 0.48 and 0.28 in the ultra-small and extra-large settings, respectively. More importantly, CaMeRL achieves reliable navigation in cluttered outdoor environments.
Med-DisSeg: Dispersion-Driven Representation Learning for Fine-Grained Medical Image Segmentation
May 14, 2026Accurate medical image segmentation is fundamental to precision medicine, yet robust delineation remains challenging under heterogeneous appearances, ambiguous boundaries, and large anatomical variability. Similar intensity and texture patterns between targets and surrounding tissues often lead to blurred activations and unreliable separation. We attribute these failures to representation collapse during encoding and insufficient fine grained multi scale decoding. To address these issues, we propose Med DisSeg, a dispersion driven medical image segmentation framework that jointly improves representation learning and anatomical delineation. Med DisSeg combines a lightweight Dispersive Loss with adaptive attention for fine grained structure segmentation. The Dispersive Loss enlarges inter sample margins by treating in batch hidden representations as negative pairs, producing well dispersed and boundary aware embeddings with negligible overhead. Based on these enhanced representations, the encoder strengthens structure sensitive responses, while the decoder performs adaptive multi scale calibration to preserve complementary local texture and global shape information. Extensive experiments on five datasets spanning three imaging modalities demonstrate consistent state of the art performance. Moreover, Med DisSeg achieves competitive results on multi organ CT segmentation, supporting its robustness and cross task applicability.
SpectraFlow: Unifying Structural Pretraining and Frequency Adaptation for Medical Image Segmentation
May 14, 2026Medical image segmentation remains challenging in low-data regimes, where scarce annotations often yield poor generalization and ambiguous boundaries with missing fine structures. Recent self-supervised pretraining has improved transferability, but it often exhibits a texture bias. In contrast, accurate segmentation is inherently geometry-aware and depends on both topological consistency and precise boundary preservation. To address this problem, we propose a two-stage framework that couples structure-aware encoder pretraining with boundary-oriented decoding. In Stage-1, we aim to learn structure-aware representations for downstream segmentation in low-data regimes. To this end, we propose Mixed-Domain MeanFlow Pretraining, which aligns images and binary masks in a shared latent space through latent transport regression, where masks act as conditional structural guidance rather than prediction targets, making the pretraining task-agnostic. To further improve training stability under scarce supervision, we incorporate a lightweight Dispersive Loss to prevent representation collapse. In Stage-2, we fine-tune the pretrained encoder with a lightweight decoder that combines Direct Attentional Fusion for adaptive cross-scale gating and Frequency-Directional Dynamic Convolution for high-frequency boundary refinement under appearance variation. Experiments on ISIC-2016, Kvasir-SEG, and GlaS demonstrate consistent gains over state-of-the-art methods, with improved robustness in low-data settings and sharper boundary delineation.
One Step Is Enough: Dispersive MeanFlow Policy Optimization
Jan 28, 2026Real-time robotic control demands fast action generation. However, existing generative policies based on diffusion and flow matching require multi-step sampling, fundamentally limiting deployment in time-critical scenarios. We propose Dispersive MeanFlow Policy Optimization (DMPO), a unified framework that enables true one-step generation through three key components: MeanFlow for mathematically-derived single-step inference without knowledge distillation, dispersive regularization to prevent representation collapse, and reinforcement learning (RL) fine-tuning to surpass expert demonstrations. Experiments across RoboMimic manipulation and OpenAI Gym locomotion benchmarks demonstrate competitive or superior performance compared to multi-step baselines. With our lightweight model architecture and the three key algorithmic components working in synergy, DMPO exceeds real-time control requirements (>120Hz) with 5-20x inference speedup, reaching hundreds of Hertz on high-performance GPUs. Physical deployment on a Franka-Emika-Panda robot validates real-world applicability.
DM1: MeanFlow with Dispersive Regularization for 1-Step Robotic Manipulation
Oct 09, 2025The ability to learn multi-modal action distributions is indispensable for robotic manipulation policies to perform precise and robust control. Flow-based generative models have recently emerged as a promising solution to learning distributions of actions, offering one-step action generation and thus achieving much higher sampling efficiency compared to diffusion-based methods. However, existing flow-based policies suffer from representation collapse, the inability to distinguish similar visual representations, leading to failures in precise manipulation tasks. We propose DM1 (MeanFlow with Dispersive Regularization for One-Step Robotic Manipulation), a novel flow matching framework that integrates dispersive regularization into MeanFlow to prevent collapse while maintaining one-step efficiency. DM1 employs multiple dispersive regularization variants across different intermediate embedding layers, encouraging diverse representations across training batches without introducing additional network modules or specialized training procedures. Experiments on RoboMimic benchmarks show that DM1 achieves 20-40 times faster inference (0.07s vs. 2-3.5s) and improves success rates by 10-20 percentage points, with the Lift task reaching 99% success over 85% of the baseline. Real-robot deployment on a Franka Panda further validates that DM1 transfers effectively from simulation to the physical world. To the best of our knowledge, this is the first work to leverage representation regularization to enable flow-based policies to achieve strong performance in robotic manipulation, establishing a simple yet powerful approach for efficient and robust manipulation.
Thinking Before You Speak: A Proactive Test-time Scaling Approach
Aug 27, 2025
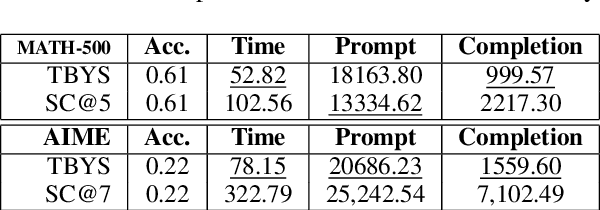
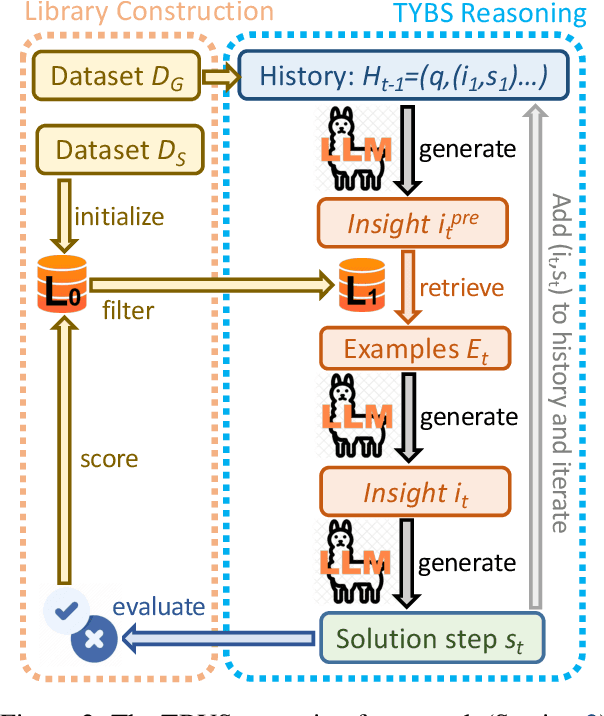
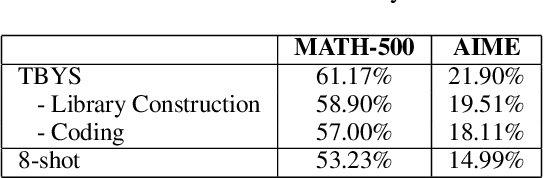
Large Language Models (LLMs) often exhibit deficiencies with complex reasoning tasks, such as maths, which we attribute to the discrepancy between human reasoning patterns and those presented in the LLMs' training data. When dealing with complex problems, humans tend to think carefully before expressing solutions. However, they often do not articulate their inner thoughts, including their intentions and chosen methodologies. Consequently, critical insights essential for bridging reasoning steps may be absent in training data collected from human sources. To bridge this gap, we proposes inserting \emph{insight}s between consecutive reasoning steps, which review the status and initiate the next reasoning steps. Unlike prior prompting strategies that rely on a single or a workflow of static prompts to facilitate reasoning, \emph{insight}s are \emph{proactively} generated to guide reasoning processes. We implement our idea as a reasoning framework, named \emph{Thinking Before You Speak} (TBYS), and design a pipeline for automatically collecting and filtering in-context examples for the generation of \emph{insight}s, which alleviates human labeling efforts and fine-tuning overheads. Experiments on challenging mathematical datasets verify the effectiveness of TBYS. Project website: https://gitee.com/jswrt/TBYS
VisRec: A Semi-Supervised Approach to Radio Interferometric Data Reconstruction
Mar 01, 2024



Radio telescopes produce visibility data about celestial objects, but these data are sparse and noisy. As a result, images created on raw visibility data are of low quality. Recent studies have used deep learning models to reconstruct visibility data to get cleaner images. However, these methods rely on a substantial amount of labeled training data, which requires significant labeling effort from radio astronomers. Addressing this challenge, we propose VisRec, a model-agnostic semi-supervised learning approach to the reconstruction of visibility data. Specifically, VisRec consists of both a supervised learning module and an unsupervised learning module. In the supervised learning module, we introduce a set of data augmentation functions to produce diverse training examples. In comparison, the unsupervised learning module in VisRec augments unlabeled data and uses reconstructions from non-augmented visibility data as pseudo-labels for training. This hybrid approach allows VisRec to effectively leverage both labeled and unlabeled data. This way, VisRec performs well even when labeled data is scarce. Our evaluation results show that VisRec outperforms all baseline methods in reconstruction quality, robustness against common observation perturbation, and generalizability to different telescope configurations.
LRSVRG-IMC: An SVRG-Based Algorithm for LowRank Inductive Matrix Completion
Jan 21, 2022
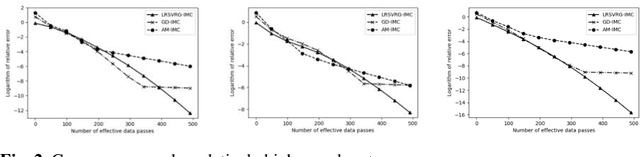
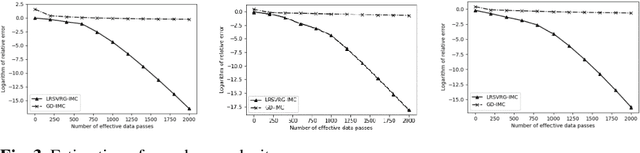
Low-rank inductive matrix completion (IMC) is currently widely used in IoT data completion, recommendation systems, and so on, as the side information in IMC has demonstrated great potential in reducing sample point remains a major obstacle for the convergence of the nonconvex solutions to IMC. What's more, carefully choosing the initial solution alone does not usually help remove the saddle points. To address this problem, we propose a stocastic variance reduction gradient-based algorithm called LRSVRG-IMC. LRSVRG-IMC can escape from the saddle points under various low-rank and sparse conditions with a properly chosen initial input. We also prove that LRSVVRG-IMC achieves both a linear convergence rate and a near-optimal sample complexity. The superiority and applicability of LRSVRG-IMC are verified via experiments on synthetic datasets.
AMMASurv: Asymmetrical Multi-Modal Attention for Accurate Survival Analysis with Whole Slide Images and Gene Expression Data
Aug 28, 2021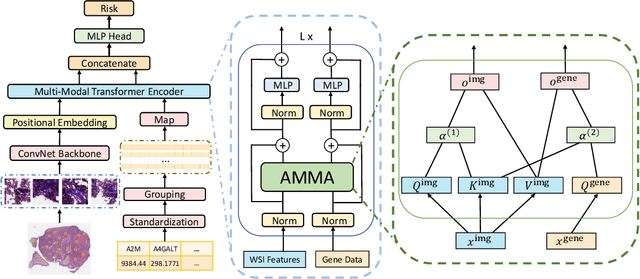
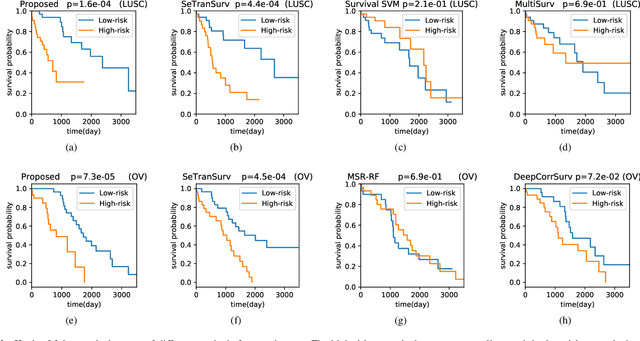
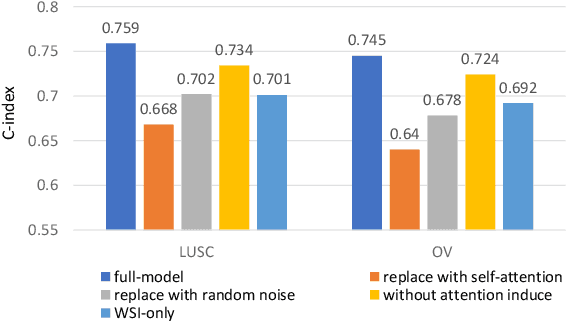
The use of multi-modal data such as the combination of whole slide images (WSIs) and gene expression data for survival analysis can lead to more accurate survival predictions. Previous multi-modal survival models are not able to efficiently excavate the intrinsic information within each modality. Moreover, despite experimental results show that WSIs provide more effective information than gene expression data, previous methods regard the information from different modalities as similarly important so they cannot flexibly utilize the potential connection between the modalities. To address the above problems, we propose a new asymmetrical multi-modal method, termed as AMMASurv. Specifically, we design an asymmetrical multi-modal attention mechanism (AMMA) in Transformer encoder for multi-modal data to enable a more flexible multi-modal information fusion for survival prediction. Different from previous works, AMMASurv can effectively utilize the intrinsic information within every modality and flexibly adapts to the modalities of different importance. Extensive experiments are conducted to validate the effectiveness of the proposed model. Encouraging results demonstrate the superiority of our method over other state-of-the-art methods.