 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindOmni: Unleashing Reasoning Generation in Vision Language Models with RGPO
May 19, 2025



Recent text-to-image systems face limitations in handling multimodal inputs and complex reasoning tasks. We introduce MindOmni, a unified multimodal large language model that addresses these challenges by incorporating reasoning generation through reinforcement learning. MindOmni leverages a three-phase training strategy: i) design of a unified vision language model with a decoder-only diffusion module, ii) supervised fine-tuning with Chain-of-Thought (CoT) instruction data, and iii) our proposed Reasoning Generation Policy Optimization (RGPO) algorithm, utilizing multimodal feedback to effectively guide policy updates. Experimental results demonstrate that MindOmni outperforms existing models, achieving impressive performance on both understanding and generation benchmarks, meanwhile showcasing advanced fine-grained reasoning generation capabilities, especially with mathematical reasoning instruction. All codes will be made public at \href{https://github.com/EasonXiao-888/MindOmni}{https://github.com/EasonXiao-888/MindOmni}.
ATP-LLaVA: Adaptive Token Pruning for Large Vision Language Models
Nov 30, 2024



Large Vision Language Models (LVLMs) have achieved significant success across multi-modal tasks. However, the computational cost of processing long visual tokens can be prohibitively expensive on resource-limited devices. Previous methods have identified redundancy in visual tokens within the Large Language Model (LLM) decoder layers and have mitigated this by pruning tokens using a pre-defined or fixed ratio, thereby reducing computational overhead. Nonetheless, we observe that the impact of pruning ratio varies across different LLM layers and instances (image-prompt pairs). Therefore, it is essential to develop a layer-wise and instance-wise vision token pruning strategy to balance computational cost and model performance effectively. We propose ATP-LLaVA, a novel approach that adaptively determines instance-specific token pruning ratios for each LLM layer. Specifically, we introduce an Adaptive Token Pruning (ATP) module, which computes the importance score and pruning threshold based on input instance adaptively. The ATP module can be seamlessly integrated between any two LLM layers with negligible computational overhead. Additionally, we develop a Spatial Augmented Pruning (SAP) strategy that prunes visual tokens with both token redundancy and spatial modeling perspectives. Our approach reduces the average token count by 75% while maintaining performance, with only a minimal 1.9% degradation across seven widely used benchmarks. The project page can be accessed via https://yxxxb.github.io/ATP-LLaVA-page/.
VoCo-LLaMA: Towards Vision Compression with Large Language Models
Jun 18, 2024



Vision-Language Models (VLMs) have achieved remarkable success in various multi-modal tasks, but they are often bottlenecked by the limited context window and high computational cost of processing high-resolution image inputs and videos. Vision compression can alleviate this problem by reducing the vision token count. Previous approaches compress vision tokens with external modules and force LLMs to understand the compressed ones, leading to visual information loss. However, the LLMs' understanding paradigm of vision tokens is not fully utilised in the compression learning process. We propose VoCo-LLaMA, the first approach to compress vision tokens using LLMs. By introducing Vision Compression tokens during the vision instruction tuning phase and leveraging attention distillation, our method distill how LLMs comprehend vision tokens into their processing of VoCo tokens. VoCo-LLaMA facilitates effective vision compression and improves the computational efficiency during the inference stage. Specifically, our method achieves minimal performance loss with a compression ratio of 576$\times$, resulting in up to 94.8$\%$ fewer FLOPs and 69.6$\%$ acceleration in inference time. Furthermore, through continuous training using time-series compressed token sequences of video frames, VoCo-LLaMA demonstrates the ability to understand temporal correlations, outperforming previous methods on popular video question-answering benchmarks. Our approach presents a promising way to unlock the full potential of VLMs' contextual window, enabling more scalable multi-modal applications. The project page, along with the associated code, can be accessed via $\href{https://yxxxb.github.io/VoCo-LLaMA-page/}{\text{this https URL}}$.
HRLAIF: Improvements in Helpfulness and Harmlessness in Open-domain Reinforcement Learning From AI Feedback
Mar 14, 2024



Reinforcement Learning from AI Feedback (RLAIF) has the advantages of shorter annotation cycles and lower costs over Reinforcement Learning from Human Feedback (RLHF), making it highly efficient during the rapid strategy iteration periods of large language model (LLM) training. Using ChatGPT as a labeler to provide feedback on open-domain prompts in RLAIF training, we observe an increase in human evaluators' preference win ratio for model responses, but a decrease in evaluators' satisfaction rate. Analysis suggests that the decrease in satisfaction rate is mainly due to some responses becoming less helpful, particularly in terms of correctness and truthfulness, highlighting practical limitations of basic RLAIF. In this paper, we propose Hybrid Reinforcement Learning from AI Feedback (HRLAIF). This method enhances the accuracy of AI annotations for responses, making the model's helpfulness more robust in training process. Additionally, it employs AI for Red Teaming, further improving the model's harmlessness. Human evaluation results show that HRLAIF inherits the ability of RLAIF to enhance human preference for outcomes at a low cost while also improving the satisfaction rate of responses. Compared to the policy model before Reinforcement Learning (RL), it achieves an increase of 2.08\% in satisfaction rate, effectively addressing the issue of a decrease of 4.58\% in satisfaction rate after basic RLAIF.
LLaMA Pro: Progressive LLaMA with Block Expansion
Jan 04, 2024



Humans generally acquire new skills without compromising the old; however, the opposite holds for Large Language Models (LLMs), e.g., from LLaMA to CodeLLaMA. To this end, we propose a new post-pretraining method for LLMs with an expansion of Transformer blocks. We tune the expanded blocks using only new corpus, efficiently and effectively improving the model's knowledge without catastrophic forgetting. In this paper, we experiment on the corpus of code and math, yielding LLaMA Pro-8.3B, a versatile foundation model initialized from LLaMA2-7B, excelling in general tasks, programming, and mathematics. LLaMA Pro and its instruction-following counterpart (LLaMA Pro-Instruct) achieve advanced performance among various benchmarks, demonstrating superiority over existing open models in the LLaMA family and the immense potential of reasoning and addressing diverse tasks as an intelligent agent. Our findings provide valuable insights into integrating natural and programming languages, laying a solid foundation for developing advanced language agents that operate effectively in various environments.
Binary Embedding-based Retrieval at Tencent
Feb 17, 2023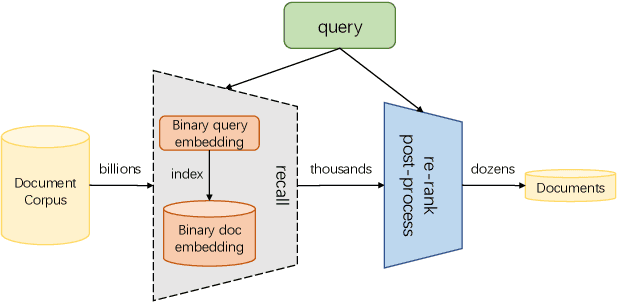

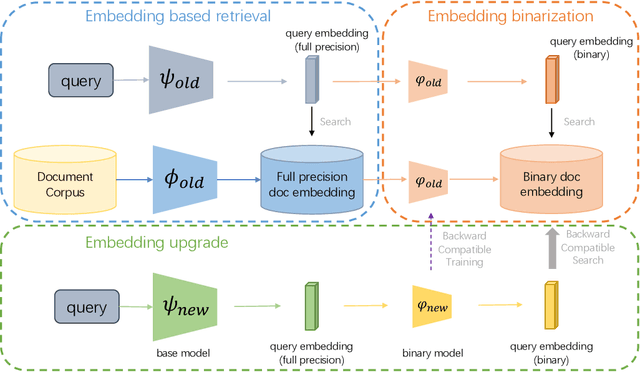

Large-scale embedding-based retrieval (EBR) is the cornerstone of search-related industrial applications. Given a user query, the system of EBR aims to identify relevant information from a large corpus of documents that may be tens or hundreds of billions in size. The storage and computation turn out to be expensive and inefficient with massive documents and high concurrent queries, making it difficult to further scale up. To tackle the challenge, we propose a binary embedding-based retrieval (BEBR) engine equipped with a recurrent binarization algorithm that enables customized bits per dimension. Specifically, we compress the full-precision query and document embeddings, formulated as float vectors in general, into a composition of multiple binary vectors using a lightweight transformation model with residual multilayer perception (MLP) blocks. We can therefore tailor the number of bits for different applications to trade off accuracy loss and cost savings. Importantly, we enable task-agnostic efficient training of the binarization model using a new embedding-to-embedding strategy. We also exploit the compatible training of binary embeddings so that the BEBR engine can support indexing among multiple embedding versions within a unified system. To further realize efficient search, we propose Symmetric Distance Calculation (SDC) to achieve lower response time than Hamming codes. We successfully employed the introduced BEBR to Tencent products, including Sogou, Tencent Video, QQ World, etc. The binarization algorithm can be seamlessly generalized to various tasks with multiple modalities. Extensive experiments on offline benchmarks and online A/B tests demonstrate the efficiency and effectiveness of our method, significantly saving 30%~50% index costs with almost no loss of accuracy at the system level.
Cross-Modal Attentional Context Learning for RGB-D Object Detection
Oct 30, 2018
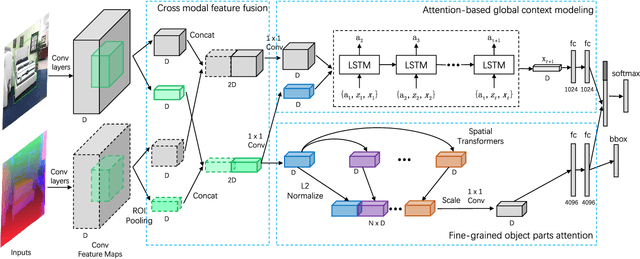
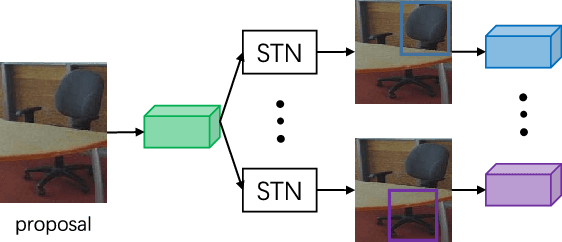
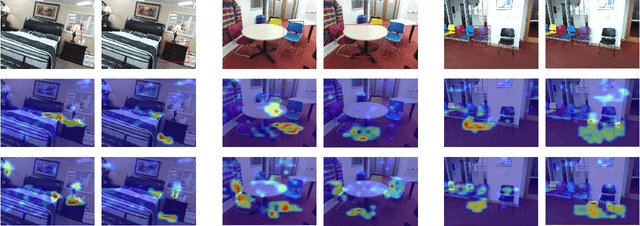
Recognizing objects from simultaneously sensed photometric (RGB) and depth channels is a fundamental yet practical problem in many machine vision applications such as robot grasping and autonomous driving. In this paper, we address this problem by developing a Cross-Modal Attentional Context (CMAC) learning framework, which enables the full exploitation of the context information from both RGB and depth data. Compared to existing RGB-D object detection frameworks, our approach has several appealing properties. First, it consists of an attention-based global context model for exploiting adaptive contextual information and incorporating this information into a region-based CNN (e.g., Fast RCNN) framework to achieve improved object detection performance. Second, our CMAC framework further contains a fine-grained object part attention module to harness multiple discriminative object parts inside each possible object region for superior local feature representation. While greatly improving the accuracy of RGB-D object detection, the effective cross-modal information fusion as well as attentional context modeling in our proposed model provide an interpretable visualization scheme. Experimental results demonstrate that the proposed method significantly improves upon the state of the art on all public benchmarks.
Knowledge-Guided Recurrent Neural Network Learning for Task-Oriented Action Prediction
Jul 15, 2017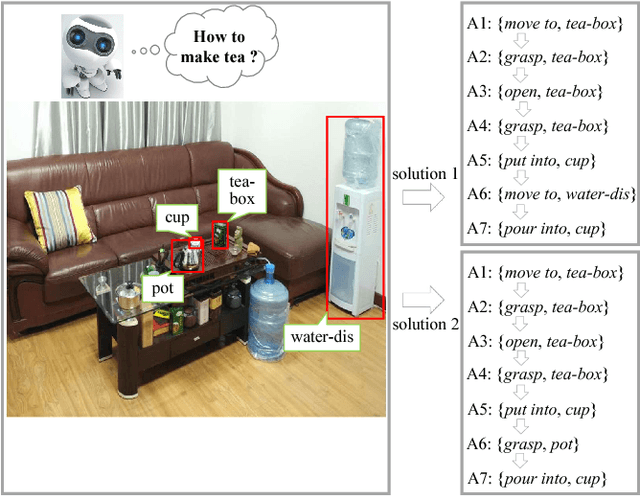

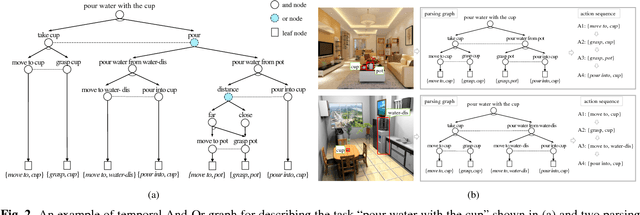

This paper aims at task-oriented action prediction, i.e., predicting a sequence of actions towards accomplishing a specific task under a certain scene, which is a new problem in computer vision research. The main challenges lie in how to model task-specific knowledge and integrate it in the learning procedure. In this work, we propose to train a recurrent long-short term memory (LSTM) network for handling this problem, i.e., taking a scene image (including pre-located objects) and the specified task as input and recurrently predicting action sequences. However, training such a network usually requires large amounts of annotated samples for covering the semantic space (e.g., diverse action decomposition and ordering). To alleviate this issue, we introduce a temporal And-Or graph (AOG) for task description, which hierarchically represents a task into atomic actions. With this AOG representation, we can produce many valid samples (i.e., action sequences according with common sense) by training another auxiliary LSTM network with a small set of annotated samples. And these generated samples (i.e., task-oriented action sequences) effectively facilitate training the model for task-oriented action prediction. In the experiments, we create a new dataset containing diverse daily tasks and extensively evaluate the effectiveness of our approach.
LSTM-CF: Unifying Context Modeling and Fusion with LSTMs for RGB-D Scene Labeling
Jul 26, 2016
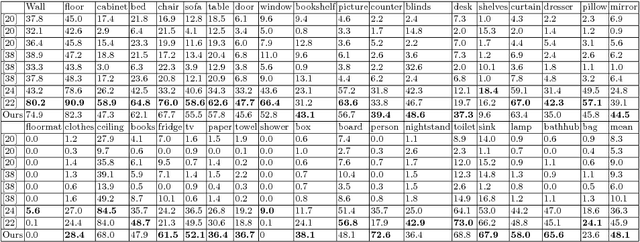

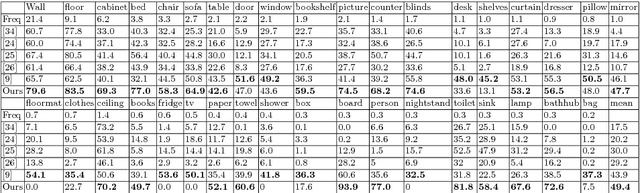
Semantic labeling of RGB-D scenes is crucial to many intelligent applications including perceptual robotics. It generates pixelwise and fine-grained label maps from simultaneously sensed photometric (RGB) and depth channels. This paper addresses this problem by i) developing a novel Long Short-Term Memorized Context Fusion (LSTM-CF) Model that captures and fuses contextual information from multiple channels of photometric and depth data, and ii) incorporating this model into deep convolutional neural networks (CNNs) for end-to-end training. Specifically, contexts in photometric and depth channels are, respectively, captured by stacking several convolutional layers and a long short-term memory layer; the memory layer encodes both short-range and long-range spatial dependencies in an image along the vertical direction. Another long short-term memorized fusion layer is set up to integrate the contexts along the vertical direction from different channels, and perform bi-directional propagation of the fused vertical contexts along the horizontal direction to obtain true 2D global contexts. At last, the fused contextual representation is concatenated with the convolutional features extracted from the photometric channels in order to improve the accuracy of fine-scale semantic labeling. Our proposed model has set a new state of the art, i.e., 48.1% and 49.4% average class accuracy over 37 categories (2.2% and 5.4% improvement) on the large-scale SUNRGBD dataset and the NYUDv2dataset, respectively.