 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEMPLATEFUZZ: Fine-Grained Chat Template Fuzzing for Jailbreaking and Red Teaming LLMs
Apr 14, 2026Large Language Models (LLMs) are increasingly deployed across diverse domains, yet their vulnerability to jailbreak attacks, where adversarial inputs bypass safety mechanisms to elicit harmful outputs, poses significant security risks. While prior work has primarily focused on prompt injection attacks, these approaches often require resource-intensive prompt engineering and overlook other critical components, such as chat templates. This paper introduces TEMPLATEFUZZ, a fine-grained fuzzing framework that systematically exposes vulnerabilities in chat templates, a critical yet underexplored attack surface in LLMs. Specifically, TEMPLATEFUZZ (1) designs a series of element-level mutation rules to generate diverse chat template variants, (2) proposes a heuristic search strategy to guide the chat template generation toward the direction of amplifying the attack success rate (ASR) while preserving model accuracy, and (3) integrates an active learning-based strategy to derive a lightweight rule-based oracle for accurate and efficient jailbreak evaluation. Evaluated on twelve open-source LLMs across multiple attack scenarios, TEMPLATEFUZZ achieves an average ASR of 98.2% with only 1.1% accuracy degradation, outperforming state-of-the-art methods by 9.1%-47.9% in ASR and 8.4% in accuracy degradation. Moreover, even on five industry-leading commercial LLMs where chat templates cannot be specified, TEMPLATEFUZZ attains a 90% average ASR via chat template-based prompt injection attacks.
Large Foundation Model for Ads Recommendation
Aug 20, 2025


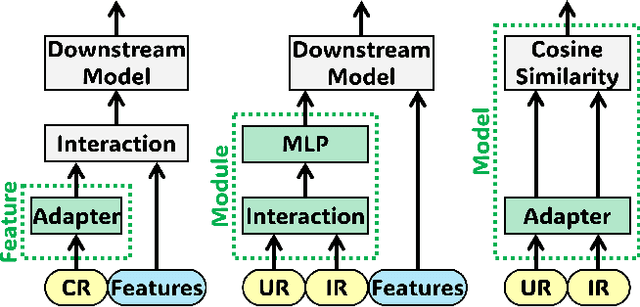
Online advertising relies on accurate recommendation models, with recent advances using pre-trained large-scale foundation models (LFMs) to capture users' general interests across multiple scenarios and tasks. However, existing methods have critical limitations: they extract and transfer only user representations (URs), ignoring valuable item representations (IRs) and user-item cross representations (CRs); and they simply use a UR as a feature in downstream applications, which fails to bridge upstream-downstream gaps and overlooks more transfer granularities. In this paper, we propose LFM4Ads, an All-Representation Multi-Granularity transfer framework for ads recommendation. It first comprehensively transfers URs, IRs, and CRs, i.e., all available representations in the pre-trained foundation model. To effectively utilize the CRs, it identifies the optimal extraction layer and aggregates them into transferable coarse-grained forms. Furthermore, we enhance the transferability via multi-granularity mechanisms: non-linear adapters for feature-level transfer, an Isomorphic Interaction Module for module-level transfer, and Standalone Retrieval for model-level transfer. LFM4Ads has been successfully deployed in Tencent's industrial-scale advertising platform, processing tens of billions of daily samples while maintaining terabyte-scale model parameters with billions of sparse embedding keys across approximately two thousand features. Since its production deployment in Q4 2024, LFM4Ads has achieved 10+ successful production launches across various advertising scenarios, including primary ones like Weixin Moments and Channels. These launches achieve an overall GMV lift of 2.45% across the entire platform, translating to estimated annual revenue increases in the hundreds of millions of dollars.
Semantics Guided Disentangled GAN for Chest X-ray Image Rib Segmentation
Jul 22, 2024The label annotations for chest X-ray image rib segmentation are time consuming and laborious, and the labeling quality heavily relies on medical knowledge of annotators. To reduce the dependency on annotated data, existing works often utilize generative adversarial network (GAN) to generate training data. However, GAN-based methods overlook the nuanced information specific to individual organs, which degrades the generation quality of chest X-ray image. Hence, we propose a novel Semantics guided Disentangled GAN (SD-GAN), which can generate the high-quality training data by fully utilizing the semantic information of different organs, for chest X-ray image rib segmentation. In particular, we use three ResNet50 branches to disentangle features of different organs, then use a decoder to combine features and generate corresponding images. To ensure that the generated images correspond to the input organ labels in semantics tags, we employ a semantics guidance module to perform semantic guidance on the generated images. To evaluate the efficacy of SD-GAN in generating high-quality samples, we introduce modified TransUNet(MTUNet), a specialized segmentation network designed for multi-scale contextual information extracting and multi-branch decoding, effectively tackling the challenge of organ overlap. We also propose a new chest X-ray image dataset (CXRS). It includes 1250 samples from various medical institutions. Lungs, clavicles, and 24 ribs are simultaneously annotated on each chest X-ray image. The visualization and quantitative results demonstrate the efficacy of SD-GAN in generating high-quality chest X-ray image-mask pairs. Using generated data, our trained MTUNet overcomes the limitations of the data scale and outperforms other segmentation networks.
SequencePAR: Understanding Pedestrian Attributes via A Sequence Generation Paradigm
Dec 04, 2023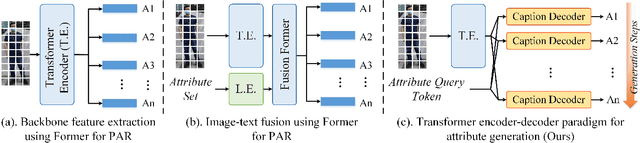
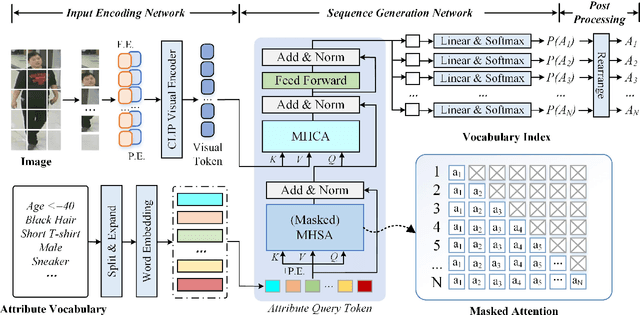
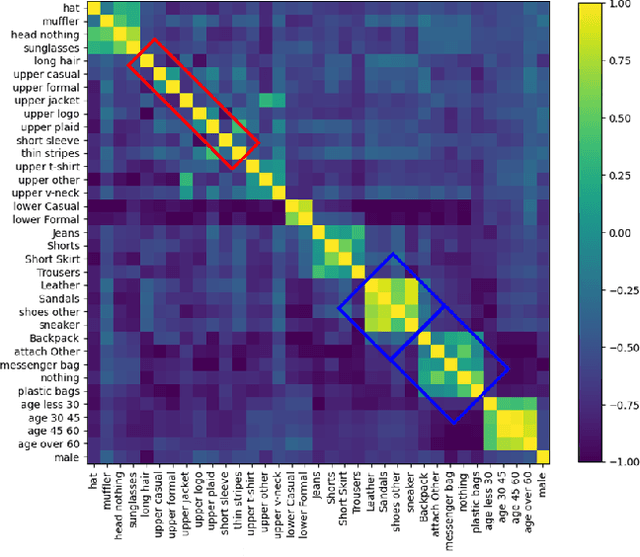
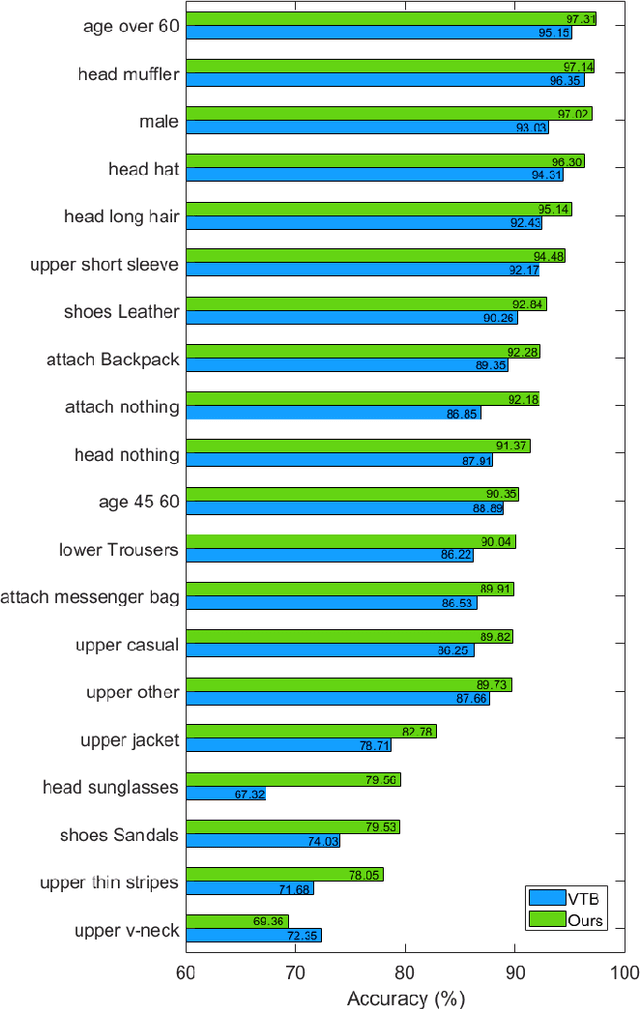
Current pedestrian attribute recognition (PAR) algorithms are developed based on multi-label or multi-task learning frameworks, which aim to discriminate the attributes using specific classification heads. However, these discriminative models are easily influenced by imbalanced data or noisy samples. Inspired by the success of generative models, we rethink the pedestrian attribute recognition scheme and believe the generative models may perform better on modeling dependencies and complexity between human attributes. In this paper, we propose a novel sequence generation paradigm for pedestrian attribute recognition, termed SequencePAR. It extracts the pedestrian features using a pre-trained CLIP model and embeds the attribute set into query tokens under the guidance of text prompts. Then, a Transformer decoder is proposed to generate the human attributes by incorporating the visual features and attribute query tokens. The masked multi-head attention layer is introduced into the decoder module to prevent the model from remembering the next attribute while making attribute predictions during training. Extensive experiments on multiple widely used pedestrian attribute recognition datasets fully validated the effectiveness of our proposed SequencePAR. The source code and pre-trained models will be released at https://github.com/Event-AHU/OpenPAR.
Visual Object Tracking by Segmentation with Graph Convolutional Network
Sep 08, 2020

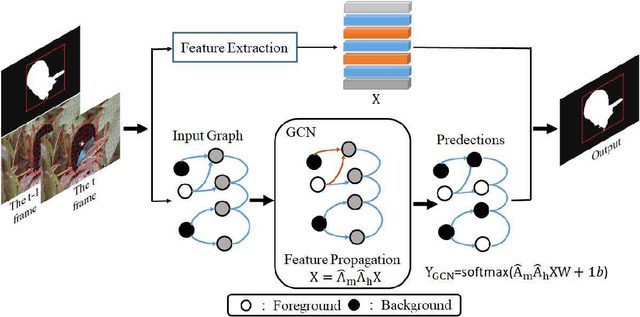
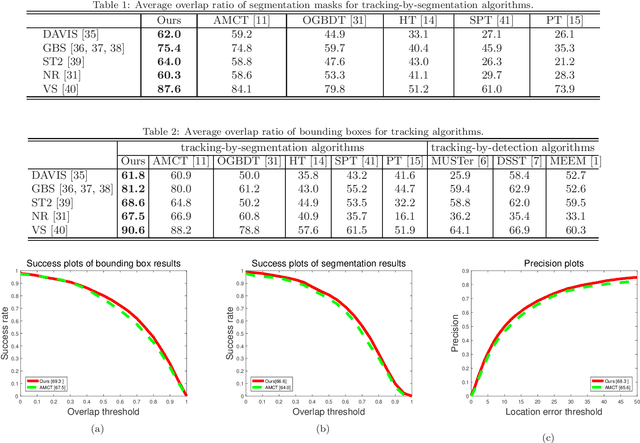
Segmentation-based tracking has been actively studied in computer vision and multimedia. Superpixel based object segmentation and tracking methods are usually developed for this task. However, they independently perform feature representation and learning of superpixels which may lead to sub-optimal results. In this paper, we propose to utilize graph convolutional network (GCN) model for superpixel based object tracking. The proposed model provides a general end-to-end framework which integrates i) label linear prediction, and ii) structure-aware feature information of each superpixel together to obtain object segmentation and further improves the performance of tracking. The main benefits of the proposed GCN method have two main aspects. First, it provides an effective end-to-end way to exploit both spatial and temporal consistency constraint for target object segmentation. Second, it utilizes a mixed graph convolution module to learn a context-aware and discriminative feature for superpixel representation and labeling. An effective algorithm has been developed to optimize the proposed model. Extensive experiments on five datasets demonstrate that our method obtains better performance against existing alternative methods.
Learning Deep Representations for Semantic Image Parsing: a Comprehensive Overview
Oct 10, 2018


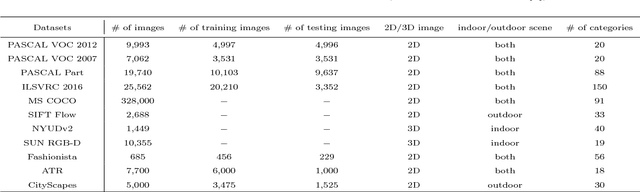
Semantic image parsing, which refers to the process of decomposing images into semantic regions and constructing the structure representation of the input, has recently aroused widespread interest in the field of computer vision. The recent application of deep representation learning has driven this field into a new stage of development. In this paper, we summarize three aspects of the progress of research on semantic image parsing, i.e., category-level semantic segmentation, instance-level semantic segmentation, and beyond segmentation. Specifically, we first review the general frameworks for each task and introduce the relevant variants. The advantages and limitations of each method are also discussed. Moreover, we present a comprehensive comparison of different benchmark datasets and evaluation metrics. Finally, we explore the future trends and challenges of semantic image parsing.
Knowledge-Guided Recurrent Neural Network Learning for Task-Oriented Action Prediction
Jul 15, 2017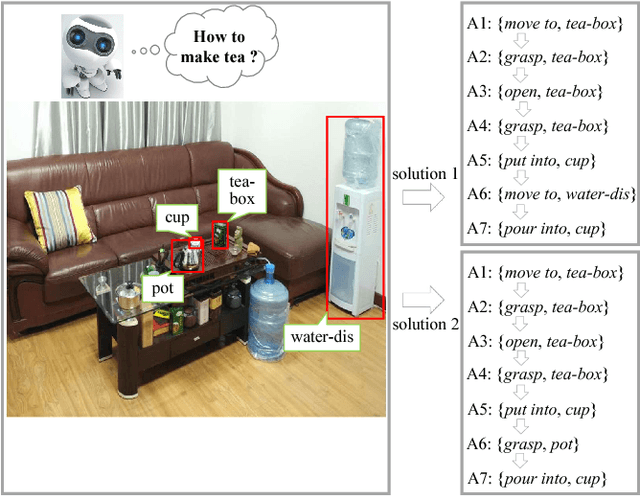

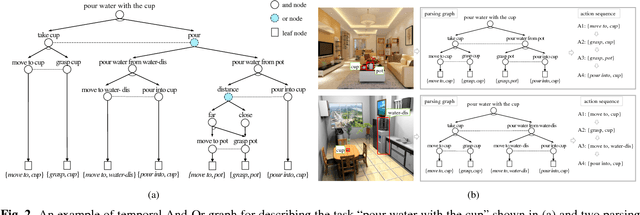

This paper aims at task-oriented action prediction, i.e., predicting a sequence of actions towards accomplishing a specific task under a certain scene, which is a new problem in computer vision research. The main challenges lie in how to model task-specific knowledge and integrate it in the learning procedure. In this work, we propose to train a recurrent long-short term memory (LSTM) network for handling this problem, i.e., taking a scene image (including pre-located objects) and the specified task as input and recurrently predicting action sequences. However, training such a network usually requires large amounts of annotated samples for covering the semantic space (e.g., diverse action decomposition and ordering). To alleviate this issue, we introduce a temporal And-Or graph (AOG) for task description, which hierarchically represents a task into atomic actions. With this AOG representation, we can produce many valid samples (i.e., action sequences according with common sense) by training another auxiliary LSTM network with a small set of annotated samples. And these generated samples (i.e., task-oriented action sequences) effectively facilitate training the model for task-oriented action prediction. In the experiments, we create a new dataset containing diverse daily tasks and extensively evaluate the effectiveness of our approach.