 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Deep Representations for Semantic Image Parsing: a Comprehensive Overview
Paper and Code
Oct 10, 2018


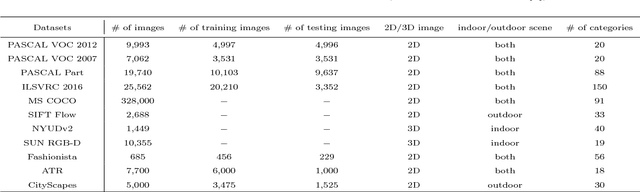
Semantic image parsing, which refers to the process of decomposing images into semantic regions and constructing the structure representation of the input, has recently aroused widespread interest in the field of computer vision. The recent application of deep representation learning has driven this field into a new stage of development. In this paper, we summarize three aspects of the progress of research on semantic image parsing, i.e., category-level semantic segmentation, instance-level semantic segmentation, and beyond segmentation. Specifically, we first review the general frameworks for each task and introduce the relevant variants. The advantages and limitations of each method are also discussed. Moreover, we present a comprehensive comparison of different benchmark datasets and evaluation metrics. Finally, we explore the future trends and challenges of semantic image parsing.