 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivating Associative Disease-Aware Vision Token Memory for LLM-Based X-ray Report Generation
Jan 07, 2025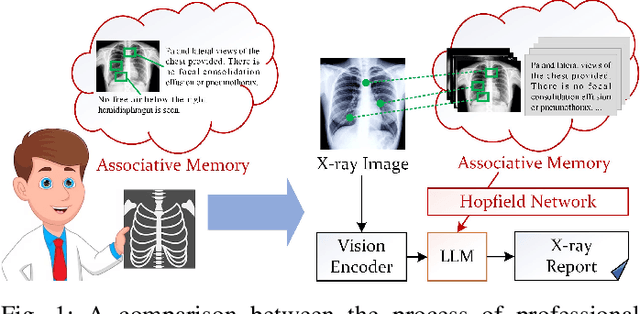



X-ray image based medical report generation achieves significant progress in recent years with the help of the large language model, however, these models have not fully exploited the effective information in visual image regions, resulting in reports that are linguistically sound but insufficient in describing key diseases. In this paper, we propose a novel associative memory-enhanced X-ray report generation model that effectively mimics the process of professional doctors writing medical reports. It considers both the mining of global and local visual information and associates historical report information to better complete the writing of the current report. Specifically, given an X-ray image, we first utilize a classification model along with its activation maps to accomplish the mining of visual regions highly associated with diseases and the learning of disease query tokens. Then, we employ a visual Hopfield network to establish memory associations for disease-related tokens, and a report Hopfield network to retrieve report memory information. This process facilitates the generation of high-quality reports based on a large language model and achieves state-of-the-art performance on multiple benchmark datasets, including the IU X-ray, MIMIC-CXR, and Chexpert Plus. The source code of this work is released on \url{https://github.com/Event-AHU/Medical_Image_Analysis}.
CXPMRG-Bench: Pre-training and Benchmarking for X-ray Medical Report Generation on CheXpert Plus Dataset
Oct 01, 2024
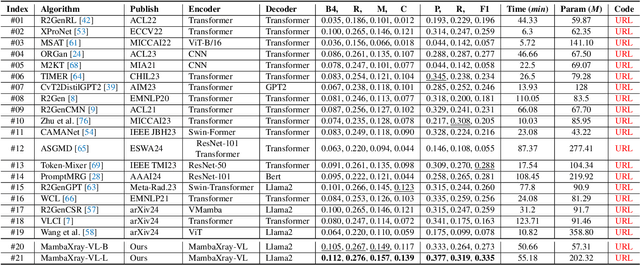
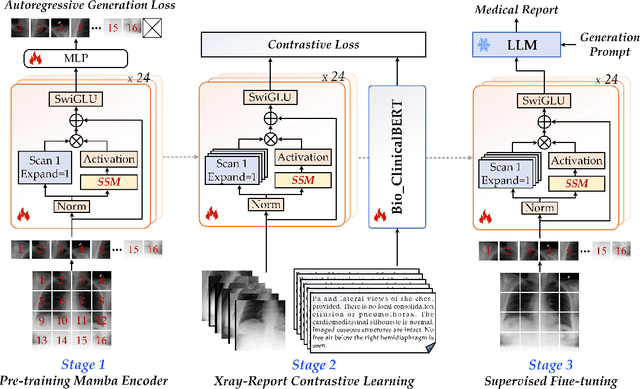
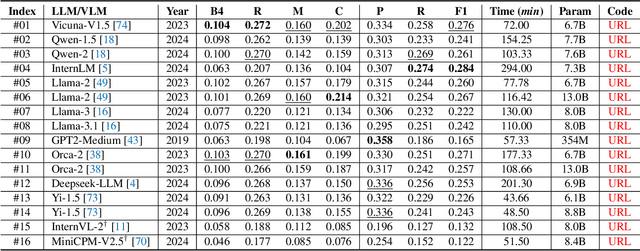
X-ray image-based medical report generation (MRG) is a pivotal area in artificial intelligence which can significantly reduce diagnostic burdens and patient wait times. Despite significant progress, we believe that the task has reached a bottleneck due to the limited benchmark datasets and the existing large models' insufficient capability enhancements in this specialized domain. Specifically, the recently released CheXpert Plus dataset lacks comparative evaluation algorithms and their results, providing only the dataset itself. This situation makes the training, evaluation, and comparison of subsequent algorithms challenging. Thus, we conduct a comprehensive benchmarking of existing mainstream X-ray report generation models and large language models (LLMs), on the CheXpert Plus dataset. We believe that the proposed benchmark can provide a solid comparative basis for subsequent algorithms and serve as a guide for researchers to quickly grasp the state-of-the-art models in this field. More importantly, we propose a large model for the X-ray image report generation using a multi-stage pre-training strategy, including self-supervised autoregressive generation and Xray-report contrastive learning, and supervised fine-tuning. Extensive experimental results indicate that the autoregressive pre-training based on Mamba effectively encodes X-ray images, and the image-text contrastive pre-training further aligns the feature spaces, achieving better experimental results. Source code can be found on \url{https://github.com/Event-AHU/Medical_Image_Analysis}.
R2GenCSR: Retrieving Context Samples for Large Language Model based X-ray Medical Report Generation
Aug 19, 2024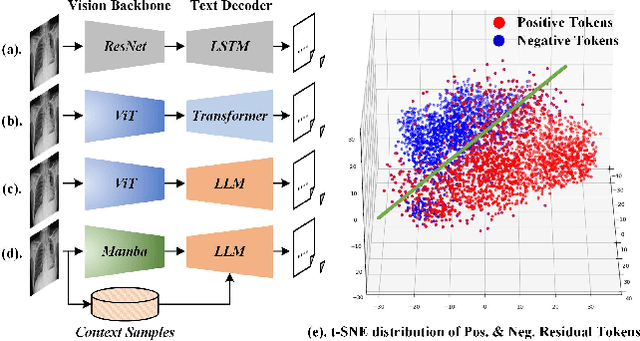
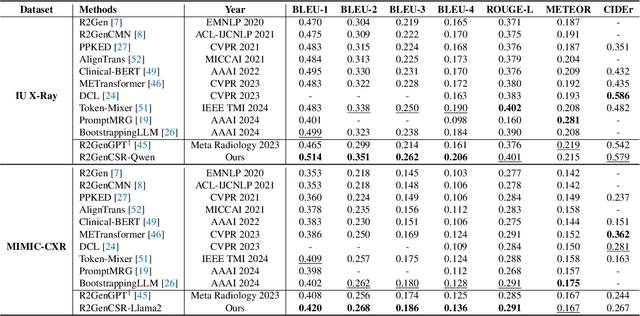
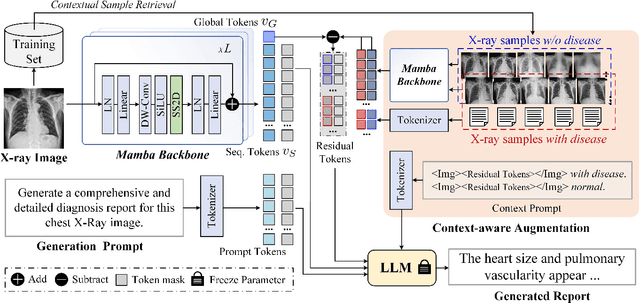
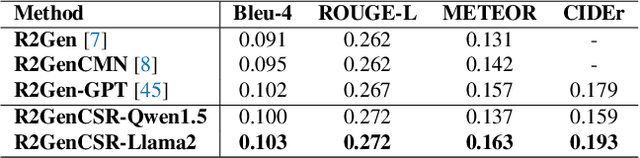
Inspired by the tremendous success of Large Language Models (LLMs), existing X-ray medical report generation methods attempt to leverage large models to achieve better performance. They usually adopt a Transformer to extract the visual features of a given X-ray image, and then, feed them into the LLM for text generation. How to extract more effective information for the LLMs to help them improve final results is an urgent problem that needs to be solved. Additionally, the use of visual Transformer models also brings high computational complexity. To address these issues, this paper proposes a novel context-guided efficient X-ray medical report generation framework. Specifically, we introduce the Mamba as the vision backbone with linear complexity, and the performance obtained is comparable to that of the strong Transformer model. More importantly, we perform context retrieval from the training set for samples within each mini-batch during the training phase, utilizing both positively and negatively related samples to enhance feature representation and discriminative learning. Subsequently, we feed the vision tokens, context information, and prompt statements to invoke the LLM for generating high-quality medical reports. Extensive experiments on three X-ray report generation datasets (i.e., IU-Xray, MIMIC-CXR, CheXpert Plus) fully validated the effectiveness of our proposed model. The source code of this work will be released on \url{https://github.com/Event-AHU/Medical_Image_Analysis}.
Semantics Guided Disentangled GAN for Chest X-ray Image Rib Segmentation
Jul 22, 2024The label annotations for chest X-ray image rib segmentation are time consuming and laborious, and the labeling quality heavily relies on medical knowledge of annotators. To reduce the dependency on annotated data, existing works often utilize generative adversarial network (GAN) to generate training data. However, GAN-based methods overlook the nuanced information specific to individual organs, which degrades the generation quality of chest X-ray image. Hence, we propose a novel Semantics guided Disentangled GAN (SD-GAN), which can generate the high-quality training data by fully utilizing the semantic information of different organs, for chest X-ray image rib segmentation. In particular, we use three ResNet50 branches to disentangle features of different organs, then use a decoder to combine features and generate corresponding images. To ensure that the generated images correspond to the input organ labels in semantics tags, we employ a semantics guidance module to perform semantic guidance on the generated images. To evaluate the efficacy of SD-GAN in generating high-quality samples, we introduce modified TransUNet(MTUNet), a specialized segmentation network designed for multi-scale contextual information extracting and multi-branch decoding, effectively tackling the challenge of organ overlap. We also propose a new chest X-ray image dataset (CXRS). It includes 1250 samples from various medical institutions. Lungs, clavicles, and 24 ribs are simultaneously annotated on each chest X-ray image. The visualization and quantitative results demonstrate the efficacy of SD-GAN in generating high-quality chest X-ray image-mask pairs. Using generated data, our trained MTUNet overcomes the limitations of the data scale and outperforms other segmentation networks.
Pre-training on High Definition X-ray Images: An Experimental Study
Apr 27, 2024



Existing X-ray based pre-trained vision models are usually conducted on a relatively small-scale dataset (less than 500k samples) with limited resolution (e.g., 224 $\times$ 224). However, the key to the success of self-supervised pre-training large models lies in massive training data, and maintaining high resolution in the field of X-ray images is the guarantee of effective solutions to difficult miscellaneous diseases. In this paper, we address these issues by proposing the first high-definition (1280 $\times$ 1280) X-ray based pre-trained foundation vision model on our newly collected large-scale dataset which contains more than 1 million X-ray images. Our model follows the masked auto-encoder framework which takes the tokens after mask processing (with a high rate) is used as input, and the masked image patches are reconstructed by the Transformer encoder-decoder network. More importantly, we introduce a novel context-aware masking strategy that utilizes the chest contour as a boundary for adaptive masking operations. We validate the effectiveness of our model on two downstream tasks, including X-ray report generation and disease recognition. Extensive experiments demonstrate that our pre-trained medical foundation vision model achieves comparable or even new state-of-the-art performance on downstream benchmark datasets. The source code and pre-trained models of this paper will be released on https://github.com/Event-AHU/Medical_Image_Analysis.
Evaluation of dynamic characteristics of power grid based on GNN and application on knowledge graph
Nov 28, 2023
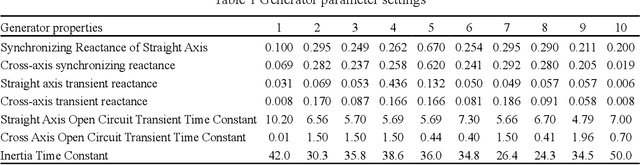
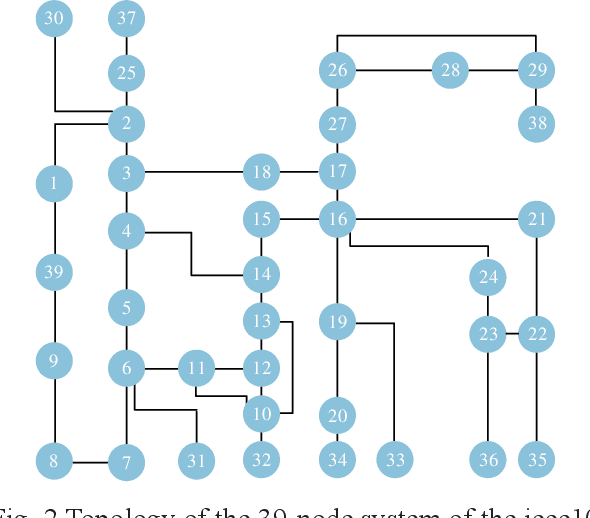

A novel method for detecting faults in power grids using a graph neural network (GNN) has been developed, aimed at enhancing intelligent fault diagnosis in network operation and maintenance. This GNN-based approach identifies faulty nodes within the power grid through a specialized electrical feature extraction model coupled with a knowledge graph. Incorporating temporal data, the method leverages the status of nodes from preceding and subsequent time periods to aid in current fault detection. To validate the effectiveness of this GNN in extracting node features, a correlation analysis of the output features from each node within the neural network layer was conducted. The results from experiments show that this method can accurately locate fault nodes in simulated scenarios with a remarkable 99.53% accuracy. Additionally, the graph neural network's feature modeling allows for a qualitative examination of how faults spread across nodes, providing valuable insights for analyzing fault nodes.
AMatFormer: Efficient Feature Matching via Anchor Matching Transformer
May 30, 2023Learning based feature matching methods have been commonly studied in recent years. The core issue for learning feature matching is to how to learn (1) discriminative representations for feature points (or regions) within each intra-image and (2) consensus representations for feature points across inter-images. Recently, self- and cross-attention models have been exploited to address this issue. However, in many scenes, features are coming with large-scale, redundant and outliers contaminated. Previous self-/cross-attention models generally conduct message passing on all primal features which thus lead to redundant learning and high computational cost. To mitigate limitations, inspired by recent seed matching methods, in this paper, we propose a novel efficient Anchor Matching Transformer (AMatFormer) for the feature matching problem. AMatFormer has two main aspects: First, it mainly conducts self-/cross-attention on some anchor features and leverages these anchor features as message bottleneck to learn the representations for all primal features. Thus, it can be implemented efficiently and compactly. Second, AMatFormer adopts a shared FFN module to further embed the features of two images into the common domain and thus learn the consensus feature representations for the matching problem. Experiments on several benchmarks demonstrate the effectiveness and efficiency of the proposed AMatFormer matching approach.