 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSign Language Translation using Frame and Event Stream: Benchmark Dataset and Algorithms
Mar 09, 2025Accurate sign language understanding serves as a crucial communication channel for individuals with disabilities. Current sign language translation algorithms predominantly rely on RGB frames, which may be limited by fixed frame rates, variable lighting conditions, and motion blur caused by rapid hand movements. Inspired by the recent successful application of event cameras in other fields, we propose to leverage event streams to assist RGB cameras in capturing gesture data, addressing the various challenges mentioned above. Specifically, we first collect a large-scale RGB-Event sign language translation dataset using the DVS346 camera, termed VECSL, which contains 15,676 RGB-Event samples, 15,191 glosses, and covers 2,568 Chinese characters. These samples were gathered across a diverse range of indoor and outdoor environments, capturing multiple viewing angles, varying light intensities, and different camera motions. Due to the absence of benchmark algorithms for comparison in this new task, we retrained and evaluated multiple state-of-the-art SLT algorithms, and believe that this benchmark can effectively support subsequent related research. Additionally, we propose a novel RGB-Event sign language translation framework (i.e., M$^2$-SLT) that incorporates fine-grained micro-sign and coarse-grained macro-sign retrieval, achieving state-of-the-art results on the proposed dataset. Both the source code and dataset will be released on https://github.com/Event-AHU/OpenESL.
CXPMRG-Bench: Pre-training and Benchmarking for X-ray Medical Report Generation on CheXpert Plus Dataset
Oct 01, 2024
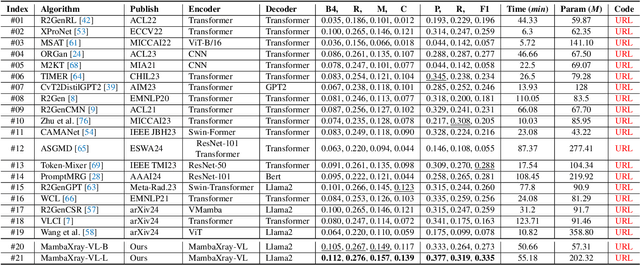
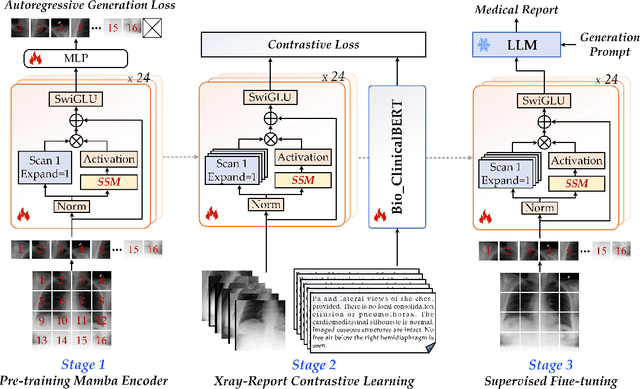
X-ray image-based medical report generation (MRG) is a pivotal area in artificial intelligence which can significantly reduce diagnostic burdens and patient wait times. Despite significant progress, we believe that the task has reached a bottleneck due to the limited benchmark datasets and the existing large models' insufficient capability enhancements in this specialized domain. Specifically, the recently released CheXpert Plus dataset lacks comparative evaluation algorithms and their results, providing only the dataset itself. This situation makes the training, evaluation, and comparison of subsequent algorithms challenging. Thus, we conduct a comprehensive benchmarking of existing mainstream X-ray report generation models and large language models (LLMs), on the CheXpert Plus dataset. We believe that the proposed benchmark can provide a solid comparative basis for subsequent algorithms and serve as a guide for researchers to quickly grasp the state-of-the-art models in this field. More importantly, we propose a large model for the X-ray image report generation using a multi-stage pre-training strategy, including self-supervised autoregressive generation and Xray-report contrastive learning, and supervised fine-tuning. Extensive experimental results indicate that the autoregressive pre-training based on Mamba effectively encodes X-ray images, and the image-text contrastive pre-training further aligns the feature spaces, achieving better experimental results. Source code can be found on \url{https://github.com/Event-AHU/Medical_Image_Analysis}.
R2GenCSR: Retrieving Context Samples for Large Language Model based X-ray Medical Report Generation
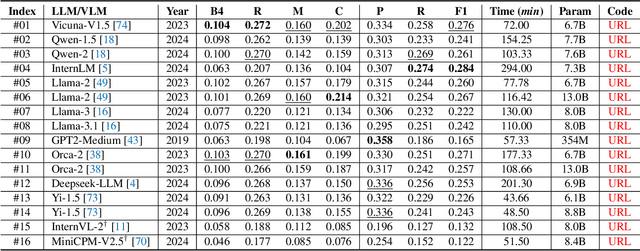
Aug 19, 2024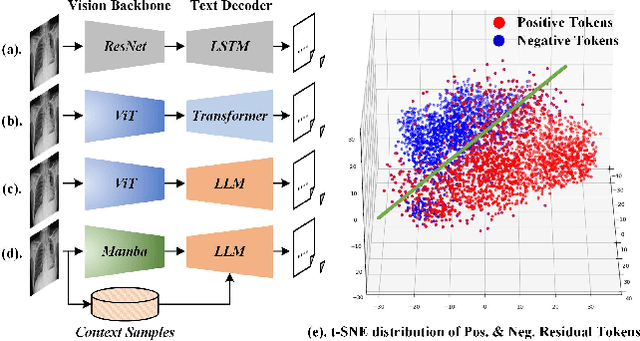
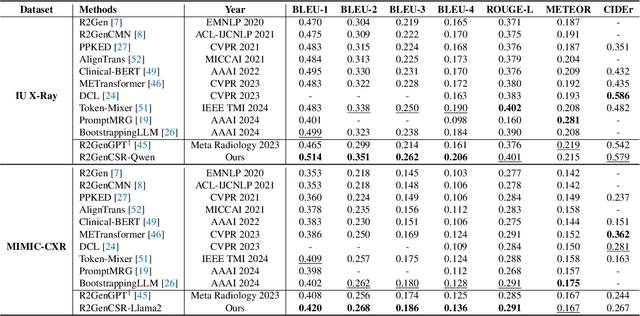
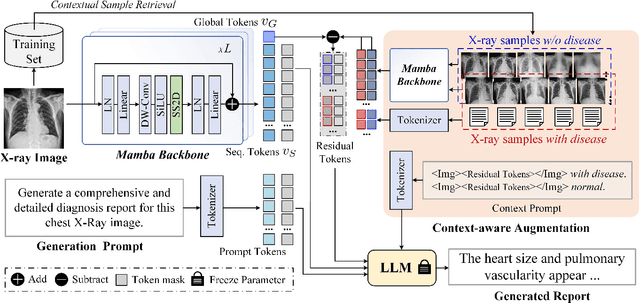
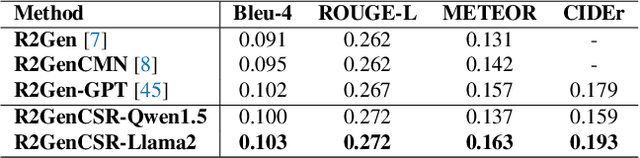
Inspired by the tremendous success of Large Language Models (LLMs), existing X-ray medical report generation methods attempt to leverage large models to achieve better performance. They usually adopt a Transformer to extract the visual features of a given X-ray image, and then, feed them into the LLM for text generation. How to extract more effective information for the LLMs to help them improve final results is an urgent problem that needs to be solved. Additionally, the use of visual Transformer models also brings high computational complexity. To address these issues, this paper proposes a novel context-guided efficient X-ray medical report generation framework. Specifically, we introduce the Mamba as the vision backbone with linear complexity, and the performance obtained is comparable to that of the strong Transformer model. More importantly, we perform context retrieval from the training set for samples within each mini-batch during the training phase, utilizing both positively and negatively related samples to enhance feature representation and discriminative learning. Subsequently, we feed the vision tokens, context information, and prompt statements to invoke the LLM for generating high-quality medical reports. Extensive experiments on three X-ray report generation datasets (i.e., IU-Xray, MIMIC-CXR, CheXpert Plus) fully validated the effectiveness of our proposed model. The source code of this work will be released on \url{https://github.com/Event-AHU/Medical_Image_Analysis}.
Pre-training on High Definition X-ray Images: An Experimental Study
Apr 27, 2024



Existing X-ray based pre-trained vision models are usually conducted on a relatively small-scale dataset (less than 500k samples) with limited resolution (e.g., 224 $\times$ 224). However, the key to the success of self-supervised pre-training large models lies in massive training data, and maintaining high resolution in the field of X-ray images is the guarantee of effective solutions to difficult miscellaneous diseases. In this paper, we address these issues by proposing the first high-definition (1280 $\times$ 1280) X-ray based pre-trained foundation vision model on our newly collected large-scale dataset which contains more than 1 million X-ray images. Our model follows the masked auto-encoder framework which takes the tokens after mask processing (with a high rate) is used as input, and the masked image patches are reconstructed by the Transformer encoder-decoder network. More importantly, we introduce a novel context-aware masking strategy that utilizes the chest contour as a boundary for adaptive masking operations. We validate the effectiveness of our model on two downstream tasks, including X-ray report generation and disease recognition. Extensive experiments demonstrate that our pre-trained medical foundation vision model achieves comparable or even new state-of-the-art performance on downstream benchmark datasets. The source code and pre-trained models of this paper will be released on https://github.com/Event-AHU/Medical_Image_Analysis.
State Space Model for New-Generation Network Alternative to Transformers: A Survey
Apr 15, 2024In the post-deep learning era, the Transformer architecture has demonstrated its powerful performance across pre-trained big models and various downstream tasks. However, the enormous computational demands of this architecture have deterred many researchers. To further reduce the complexity of attention models, numerous efforts have been made to design more efficient methods. Among them, the State Space Model (SSM), as a possible replacement for the self-attention based Transformer model, has drawn more and more attention in recent years. In this paper, we give the first comprehensive review of these works and also provide experimental comparisons and analysis to better demonstrate the features and advantages of SSM. Specifically, we first give a detailed description of principles to help the readers quickly capture the key ideas of SSM. After that, we dive into the reviews of existing SSMs and their various applications, including natural language processing, computer vision, graph, multi-modal and multi-media, point cloud/event stream, time series data, and other domains. In addition, we give statistical comparisons and analysis of these models and hope it helps the readers to understand the effectiveness of different structures on various tasks. Then, we propose possible research points in this direction to better promote the development of the theoretical model and application of SSM. More related works will be continuously updated on the following GitHub: https://github.com/Event-AHU/Mamba_State_Space_Model_Paper_List.