 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Orthogonal Refinement for Robust RGB-Event Visual Object Tracking
Mar 29, 2026Robust visual object tracking (VOT) remains challenging in high-speed motion scenarios, where conventional RGB sensors suffer from severe motion blur and performance degradation. Event cameras, with microsecond temporal resolution and high dynamic range, provide complementary structural cues that can potentially compensate for these limitations. However, existing RGB-Event fusion methods typically treat event data as dense intensity representations and adopt black-box fusion strategies, failing to explicitly leverage the directional geometric priors inherently encoded in event streams to rectify degraded RGB features. To address this limitation, we propose SOR-Track, a streamlined framework for robust RGB-Event tracking based on Spatial Orthogonal Refinement (SOR). The core SOR module employs a set of orthogonal directional filters that are dynamically guided by local motion orientations to extract sharp and motion-consistent structural responses from event streams. These responses serve as geometric anchors to modulate and refine aliased RGB textures through an asymmetric structural modulation mechanism, thereby explicitly bridging structural discrepancies between two modalities. Extensive experiments on the large-scale FE108 benchmark demonstrate that SOR-Track consistently outperforms existing fusion-based trackers, particularly under motion blur and low-light conditions. Despite its simplicity, the proposed method offers a principled and physics-grounded approach to multi-modal feature alignment and texture rectification. The source code of this paper will be released on https://github.com/Event-AHU/OpenEvTracking
RGB-Event HyperGraph Prompt for Kilometer Marker Recognition based on Pre-trained Foundation Models
Feb 25, 2026Metro trains often operate in highly complex environments, characterized by illumination variations, high-speed motion, and adverse weather conditions. These factors pose significant challenges for visual perception systems, especially those relying solely on conventional RGB cameras. To tackle these difficulties, we explore the integration of event cameras into the perception system, leveraging their advantages in low-light conditions, high-speed scenarios, and low power consumption. Specifically, we focus on Kilometer Marker Recognition (KMR), a critical task for autonomous metro localization under GNSS-denied conditions. In this context, we propose a robust baseline method based on a pre-trained RGB OCR foundation model, enhanced through multi-modal adaptation. Furthermore, we construct the first large-scale RGB-Event dataset, EvMetro5K, containing 5,599 pairs of synchronized RGB-Event samples, split into 4,479 training and 1,120 testing samples. Extensive experiments on EvMetro5K and other widely used benchmarks demonstrate the effectiveness of our approach for KMR. Both the dataset and source code will be released on https://github.com/Event-AHU/EvMetro5K_benchmark
Decoupling Amplitude and Phase Attention in Frequency Domain for RGB-Event based Visual Object Tracking
Jan 03, 2026Existing RGB-Event visual object tracking approaches primarily rely on conventional feature-level fusion, failing to fully exploit the unique advantages of event cameras. In particular, the high dynamic range and motion-sensitive nature of event cameras are often overlooked, while low-information regions are processed uniformly, leading to unnecessary computational overhead for the backbone network. To address these issues, we propose a novel tracking framework that performs early fusion in the frequency domain, enabling effective aggregation of high-frequency information from the event modality. Specifically, RGB and event modalities are transformed from the spatial domain to the frequency domain via the Fast Fourier Transform, with their amplitude and phase components decoupled. High-frequency event information is selectively fused into RGB modality through amplitude and phase attention, enhancing feature representation while substantially reducing backbone computation. In addition, a motion-guided spatial sparsification module leverages the motion-sensitive nature of event cameras to capture the relationship between target motion cues and spatial probability distribution, filtering out low-information regions and enhancing target-relevant features. Finally, a sparse set of target-relevant features is fed into the backbone network for learning, and the tracking head predicts the final target position. Extensive experiments on three widely used RGB-Event tracking benchmark datasets, including FE108, FELT, and COESOT, demonstrate the high performance and efficiency of our method. The source code of this paper will be released on https://github.com/Event-AHU/OpenEvTracking
ReasoningTrack: Chain-of-Thought Reasoning for Long-term Vision-Language Tracking
Aug 07, 2025Vision-language tracking has received increasing attention in recent years, as textual information can effectively address the inflexibility and inaccuracy associated with specifying the target object to be tracked. Existing works either directly fuse the fixed language with vision features or simply modify using attention, however, their performance is still limited. Recently, some researchers have explored using text generation to adapt to the variations in the target during tracking, however, these works fail to provide insights into the model's reasoning process and do not fully leverage the advantages of large models, which further limits their overall performance. To address the aforementioned issues, this paper proposes a novel reasoning-based vision-language tracking framework, named ReasoningTrack, based on a pre-trained vision-language model Qwen2.5-VL. Both SFT (Supervised Fine-Tuning) and reinforcement learning GRPO are used for the optimization of reasoning and language generation. We embed the updated language descriptions and feed them into a unified tracking backbone network together with vision features. Then, we adopt a tracking head to predict the specific location of the target object. In addition, we propose a large-scale long-term vision-language tracking benchmark dataset, termed TNLLT, which contains 200 video sequences. 20 baseline visual trackers are re-trained and evaluated on this dataset, which builds a solid foundation for the vision-language visual tracking task. Extensive experiments on multiple vision-language tracking benchmark datasets fully validated the effectiveness of our proposed reasoning-based natural language generation strategy. The source code of this paper will be released on https://github.com/Event-AHU/Open_VLTrack
Towards Low-Latency Event Stream-based Visual Object Tracking: A Slow-Fast Approach
May 19, 2025Existing tracking algorithms typically rely on low-frame-rate RGB cameras coupled with computationally intensive deep neural network architectures to achieve effective tracking. However, such frame-based methods inherently face challenges in achieving low-latency performance and often fail in resource-constrained environments. Visual object tracking using bio-inspired event cameras has emerged as a promising research direction in recent years, offering distinct advantages for low-latency applications. In this paper, we propose a novel Slow-Fast Tracking paradigm that flexibly adapts to different operational requirements, termed SFTrack. The proposed framework supports two complementary modes, i.e., a high-precision slow tracker for scenarios with sufficient computational resources, and an efficient fast tracker tailored for latency-aware, resource-constrained environments. Specifically, our framework first performs graph-based representation learning from high-temporal-resolution event streams, and then integrates the learned graph-structured information into two FlashAttention-based vision backbones, yielding the slow and fast trackers, respectively. The fast tracker achieves low latency through a lightweight network design and by producing multiple bounding box outputs in a single forward pass. Finally, we seamlessly combine both trackers via supervised fine-tuning and further enhance the fast tracker's performance through a knowledge distillation strategy. Extensive experiments on public benchmarks, including FE240, COESOT, and EventVOT, demonstrate the effectiveness and efficiency of our proposed method across different real-world scenarios. The source code has been released on https://github.com/Event-AHU/SlowFast_Event_Track.
RGB-Event based Pedestrian Attribute Recognition: A Benchmark Dataset and An Asymmetric RWKV Fusion Framework
Apr 14, 2025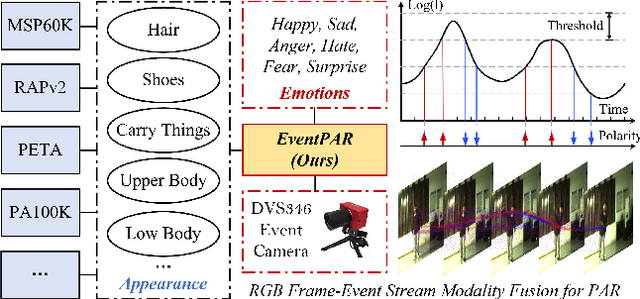
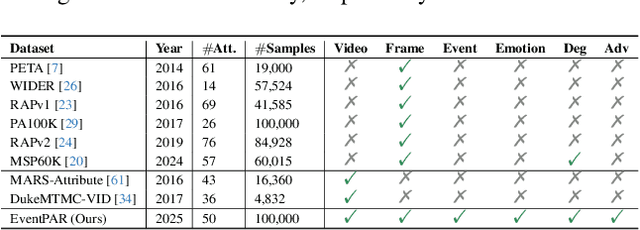

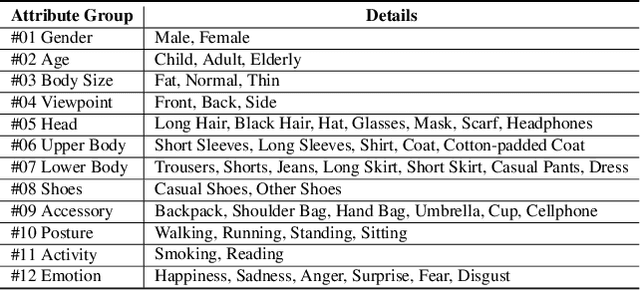
Existing pedestrian attribute recognition methods are generally developed based on RGB frame cameras. However, these approaches are constrained by the limitations of RGB cameras, such as sensitivity to lighting conditions and motion blur, which hinder their performance. Furthermore, current attribute recognition primarily focuses on analyzing pedestrians' external appearance and clothing, lacking an exploration of emotional dimensions. In this paper, we revisit these issues and propose a novel multi-modal RGB-Event attribute recognition task by drawing inspiration from the advantages of event cameras in low-light, high-speed, and low-power consumption. Specifically, we introduce the first large-scale multi-modal pedestrian attribute recognition dataset, termed EventPAR, comprising 100K paired RGB-Event samples that cover 50 attributes related to both appearance and six human emotions, diverse scenes, and various seasons. By retraining and evaluating mainstream PAR models on this dataset, we establish a comprehensive benchmark and provide a solid foundation for future research in terms of data and algorithmic baselines. In addition, we propose a novel RWKV-based multi-modal pedestrian attribute recognition framework, featuring an RWKV visual encoder and an asymmetric RWKV fusion module. Extensive experiments are conducted on our proposed dataset as well as two simulated datasets (MARS-Attribute and DukeMTMC-VID-Attribute), achieving state-of-the-art results. The source code and dataset will be released on https://github.com/Event-AHU/OpenPAR
Human Activity Recognition using RGB-Event based Sensors: A Multi-modal Heat Conduction Model and A Benchmark Dataset
Apr 08, 2025



Human Activity Recognition (HAR) primarily relied on traditional RGB cameras to achieve high-performance activity recognition. However, the challenging factors in real-world scenarios, such as insufficient lighting and rapid movements, inevitably degrade the performance of RGB cameras. To address these challenges, biologically inspired event cameras offer a promising solution to overcome the limitations of traditional RGB cameras. In this work, we rethink human activity recognition by combining the RGB and event cameras. The first contribution is the proposed large-scale multi-modal RGB-Event human activity recognition benchmark dataset, termed HARDVS 2.0, which bridges the dataset gaps. It contains 300 categories of everyday real-world actions with a total of 107,646 paired videos covering various challenging scenarios. Inspired by the physics-informed heat conduction model, we propose a novel multi-modal heat conduction operation framework for effective activity recognition, termed MMHCO-HAR. More in detail, given the RGB frames and event streams, we first extract the feature embeddings using a stem network. Then, multi-modal Heat Conduction blocks are designed to fuse the dual features, the key module of which is the multi-modal Heat Conduction Operation layer. We integrate RGB and event embeddings through a multi-modal DCT-IDCT layer while adaptively incorporating the thermal conductivity coefficient via FVEs into this module. After that, we propose an adaptive fusion module based on a policy routing strategy for high-performance classification. Comprehensive experiments demonstrate that our method consistently performs well, validating its effectiveness and robustness. The source code and benchmark dataset will be released on https://github.com/Event-AHU/HARDVS/tree/HARDVSv2
Event Stream-based Visual Object Tracking: HDETrack V2 and A High-Definition Benchmark
Feb 08, 2025



We then introduce a novel hierarchical knowledge distillation strategy that incorporates the similarity matrix, feature representation, and response map-based distillation to guide the learning of the student Transformer network. We also enhance the model's ability to capture temporal dependencies by applying the temporal Fourier transform to establish temporal relationships between video frames. We adapt the network model to specific target objects during testing via a newly proposed test-time tuning strategy to achieve high performance and flexibility in target tracking. Recognizing the limitations of existing event-based tracking datasets, which are predominantly low-resolution, we propose EventVOT, the first large-scale high-resolution event-based tracking dataset. It comprises 1141 videos spanning diverse categories such as pedestrians, vehicles, UAVs, ping pong, etc. Extensive experiments on both low-resolution (FE240hz, VisEvent, FELT), and our newly proposed high-resolution EventVOT dataset fully validated the effectiveness of our proposed method. Both the benchmark dataset and source code have been released on https://github.com/Event-AHU/EventVOT_Benchmark
Exploiting Memory-aware Q-distribution Prediction for Nuclear Fusion via Modern Hopfield Network
Oct 11, 2024

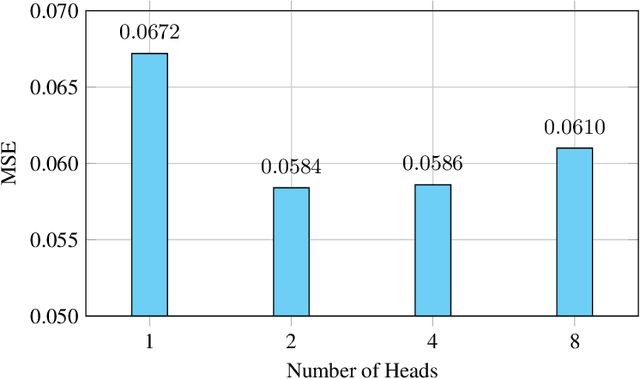

This study addresses the critical challenge of predicting the Q-distribution in long-term stable nuclear fusion task, a key component for advancing clean energy solutions. We introduce an innovative deep learning framework that employs Modern Hopfield Networks to incorporate associative memory from historical shots. Utilizing a newly compiled dataset, we demonstrate the effectiveness of our approach in enhancing Q-distribution prediction. The proposed method represents a significant advancement by leveraging historical memory information for the first time in this context, showcasing improved prediction accuracy and contributing to the optimization of nuclear fusion research.
Multi-modal Fusion based Q-distribution Prediction for Controlled Nuclear Fusion
Oct 11, 2024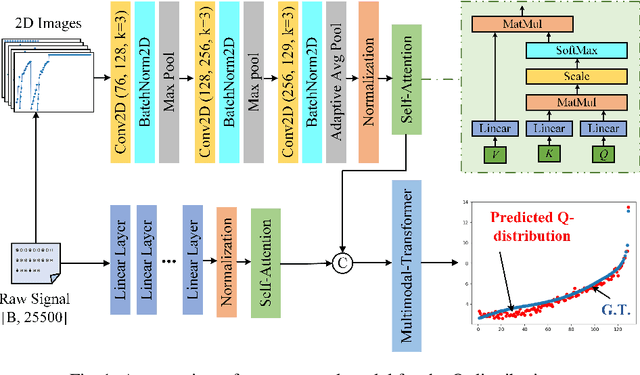


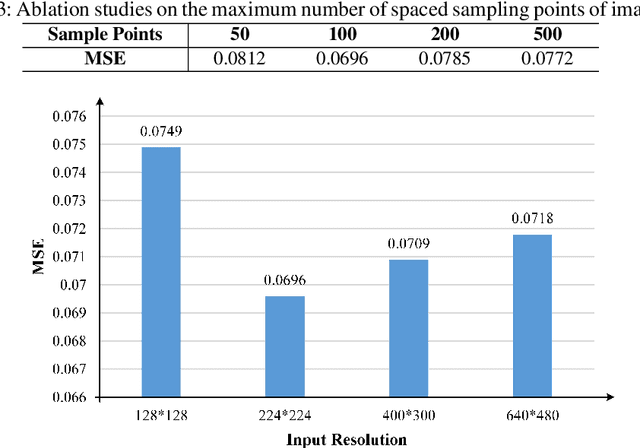
Q-distribution prediction is a crucial research direction in controlled nuclear fusion, with deep learning emerging as a key approach to solving prediction challenges. In this paper, we leverage deep learning techniques to tackle the complexities of Q-distribution prediction. Specifically, we explore multimodal fusion methods in computer vision, integrating 2D line image data with the original 1D data to form a bimodal input. Additionally, we employ the Transformer's attention mechanism for feature extraction and the interactive fusion of bimodal information. Extensive experiments validate the effectiveness of our approach, significantly reducing prediction errors in Q-distribution.