 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectrogram features for audio and speech analysis
Mar 16, 2026Spectrogram-based representations have grown to dominate the feature space for deep learning audio analysis systems, and are often adopted for speech analysis also. Initially, the primary motivator for spectrogram-based representations was their ability to present sound as a two dimensional signal in the time-frequency plane, which not only provides an interpretable physical basis for analysing sound, but also unlocks the use of a wide range of machine learning techniques such as convolutional neural networks, that had been developed for image processing. A spectrogram is a matrix characterised by the resolution and span of its two dimensions, as well as by the representation and scaling of each element. Many possibilities for these three characteristics have been explored by researchers across numerous application areas, with different settings showing affinity for various tasks. This paper reviews the use of spectrogram-based representations and surveys the state-of-the-art to question how front-end feature representation choice allies with back-end classifier architecture for different tasks.
* 30 pages
Advances and Frontiers of LLM-based Issue Resolution in Software Engineering: A Comprehensive Survey
Jan 15, 2026Issue resolution, a complex Software Engineering (SWE) task integral to real-world development, has emerged as a compelling challenge for artificial intelligence. The establishment of benchmarks like SWE-bench revealed this task as profoundly difficult for large language models, thereby significantly accelerating the evolution of autonomous coding agents. This paper presents a systematic survey of this emerging domain. We begin by examining data construction pipelines, covering automated collection and synthesis approaches. We then provide a comprehensive analysis of methodologies, spanning training-free frameworks with their modular components to training-based techniques, including supervised fine-tuning and reinforcement learning. Subsequently, we discuss critical analyses of data quality and agent behavior, alongside practical applications. Finally, we identify key challenges and outline promising directions for future research. An open-source repository is maintained at https://github.com/DeepSoftwareAnalytics/Awesome-Issue-Resolution to serve as a dynamic resource in this field.
CLARITY: Contextual Linguistic Adaptation and Accent Retrieval for Dual-Bias Mitigation in Text-to-Speech Generation
Nov 14, 2025Instruction-guided text-to-speech (TTS) research has reached a maturity level where excellent speech generation quality is possible on demand, yet two coupled biases persist: accent bias, where models default to dominant phonetic patterns, and linguistic bias, where dialect-specific lexical and cultural cues are ignored. These biases are interdependent, as authentic accent generation requires both accent fidelity and localized text. We present Contextual Linguistic Adaptation and Retrieval for Inclusive TTS sYnthesis (CLARITY), a backbone-agnostic framework that addresses these biases through dual-signal optimization: (i) contextual linguistic adaptation that localizes input text to the target dialect, and (ii) retrieval-augmented accent prompting (RAAP) that supplies accent-consistent speech prompts. Across twelve English accents, CLARITY improves accent accuracy and fairness while maintaining strong perceptual quality.
RGB-Event based Pedestrian Attribute Recognition: A Benchmark Dataset and An Asymmetric RWKV Fusion Framework
Apr 14, 2025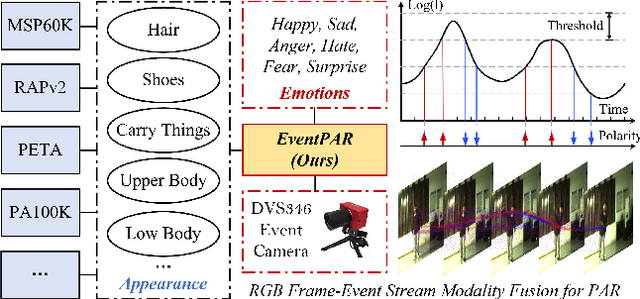
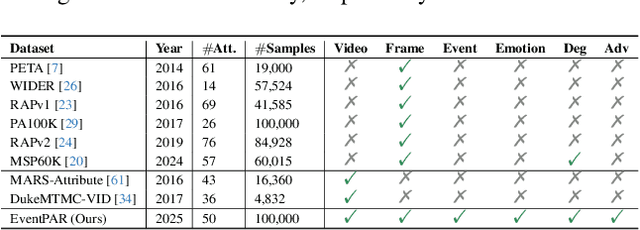

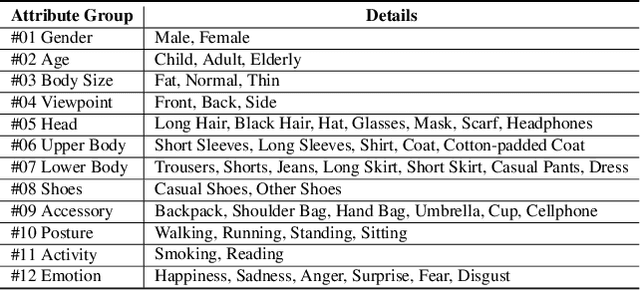
Existing pedestrian attribute recognition methods are generally developed based on RGB frame cameras. However, these approaches are constrained by the limitations of RGB cameras, such as sensitivity to lighting conditions and motion blur, which hinder their performance. Furthermore, current attribute recognition primarily focuses on analyzing pedestrians' external appearance and clothing, lacking an exploration of emotional dimensions. In this paper, we revisit these issues and propose a novel multi-modal RGB-Event attribute recognition task by drawing inspiration from the advantages of event cameras in low-light, high-speed, and low-power consumption. Specifically, we introduce the first large-scale multi-modal pedestrian attribute recognition dataset, termed EventPAR, comprising 100K paired RGB-Event samples that cover 50 attributes related to both appearance and six human emotions, diverse scenes, and various seasons. By retraining and evaluating mainstream PAR models on this dataset, we establish a comprehensive benchmark and provide a solid foundation for future research in terms of data and algorithmic baselines. In addition, we propose a novel RWKV-based multi-modal pedestrian attribute recognition framework, featuring an RWKV visual encoder and an asymmetric RWKV fusion module. Extensive experiments are conducted on our proposed dataset as well as two simulated datasets (MARS-Attribute and DukeMTMC-VID-Attribute), achieving state-of-the-art results. The source code and dataset will be released on https://github.com/Event-AHU/OpenPAR
VELoRA: A Low-Rank Adaptation Approach for Efficient RGB-Event based Recognition
Dec 28, 2024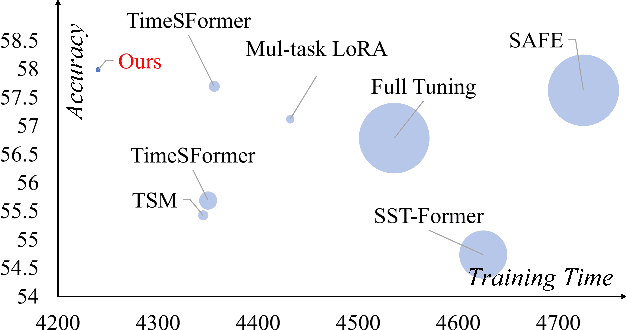
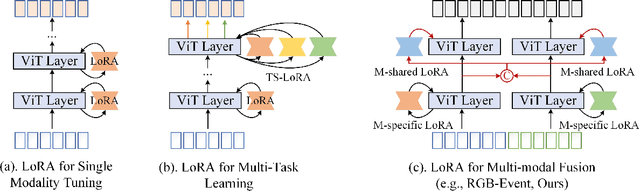
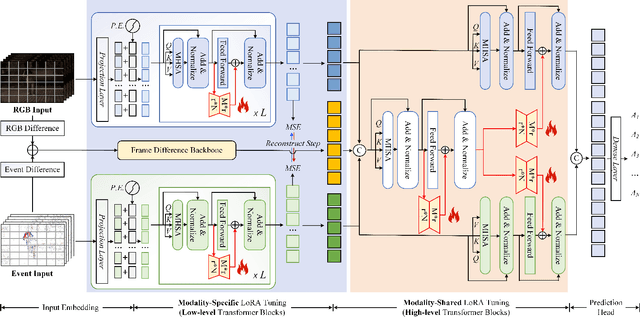
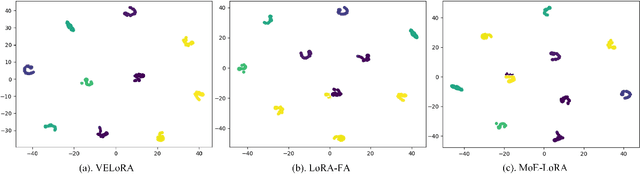
Pattern recognition leveraging both RGB and Event cameras can significantly enhance performance by deploying deep neural networks that utilize a fine-tuning strategy. Inspired by the successful application of large models, the introduction of such large models can also be considered to further enhance the performance of multi-modal tasks. However, fully fine-tuning these models leads to inefficiency and lightweight fine-tuning methods such as LoRA and Adapter have been proposed to achieve a better balance between efficiency and performance. To our knowledge, there is currently no work that has conducted parameter-efficient fine-tuning (PEFT) for RGB-Event recognition based on pre-trained foundation models. To address this issue, this paper proposes a novel PEFT strategy to adapt the pre-trained foundation vision models for the RGB-Event-based classification. Specifically, given the RGB frames and event streams, we extract the RGB and event features based on the vision foundation model ViT with a modality-specific LoRA tuning strategy. The frame difference of the dual modalities is also considered to capture the motion cues via the frame difference backbone network. These features are concatenated and fed into high-level Transformer layers for efficient multi-modal feature learning via modality-shared LoRA tuning. Finally, we concatenate these features and feed them into a classification head to achieve efficient fine-tuning. The source code and pre-trained models will be released on \url{https://github.com/Event-AHU/VELoRA}.
A Stack-Propagation Framework for Low-Resource Personalized Dialogue Generation
Oct 26, 2024



With the resurgent interest in building open-domain dialogue systems, the dialogue generation task has attracted increasing attention over the past few years. This task is usually formulated as a conditional generation problem, which aims to generate a natural and meaningful response given dialogue contexts and specific constraints, such as persona. And maintaining a consistent persona is essential for the dialogue systems to gain trust from the users. Although tremendous advancements have been brought, traditional persona-based dialogue models are typically trained by leveraging a large number of persona-dense dialogue examples. Yet, such persona-dense training data are expensive to obtain, leading to a limited scale. This work presents a novel approach to learning from limited training examples by regarding consistency understanding as a regularization of response generation. To this end, we propose a novel stack-propagation framework for learning a generation and understanding pipeline.Specifically, the framework stacks a Transformer encoder and two Transformer decoders, where the first decoder models response generation and the second serves as a regularizer and jointly models response generation and consistency understanding. The proposed framework can benefit from the stacked encoder and decoders to learn from much smaller personalized dialogue data while maintaining competitive performance. Under different low-resource settings, subjective and objective evaluations prove that the stack-propagation framework outperforms strong baselines in response quality and persona consistency and largely overcomes the shortcomings of traditional models that rely heavily on the persona-dense dialogue data.
* published as a journal paper at ACM Transactions on Information Systems 2023. 35 pages, 5 figures
SNN-PAR: Energy Efficient Pedestrian Attribute Recognition via Spiking Neural Networks
Oct 10, 2024Artificial neural network based Pedestrian Attribute Recognition (PAR) has been widely studied in recent years, despite many progresses, however, the energy consumption is still high. To address this issue, in this paper, we propose a Spiking Neural Network (SNN) based framework for energy-efficient attribute recognition. Specifically, we first adopt a spiking tokenizer module to transform the given pedestrian image into spiking feature representations. Then, the output will be fed into the spiking Transformer backbone networks for energy-efficient feature extraction. We feed the enhanced spiking features into a set of feed-forward networks for pedestrian attribute recognition. In addition to the widely used binary cross-entropy loss function, we also exploit knowledge distillation from the artificial neural network to the spiking Transformer network for more accurate attribute recognition. Extensive experiments on three widely used PAR benchmark datasets fully validated the effectiveness of our proposed SNN-PAR framework. The source code of this paper is released on \url{https://github.com/Event-AHU/OpenPAR}.
MAT-SED: A Masked Audio Transformer with Masked-Reconstruction Based Pre-training for Sound Event Detection
Aug 19, 2024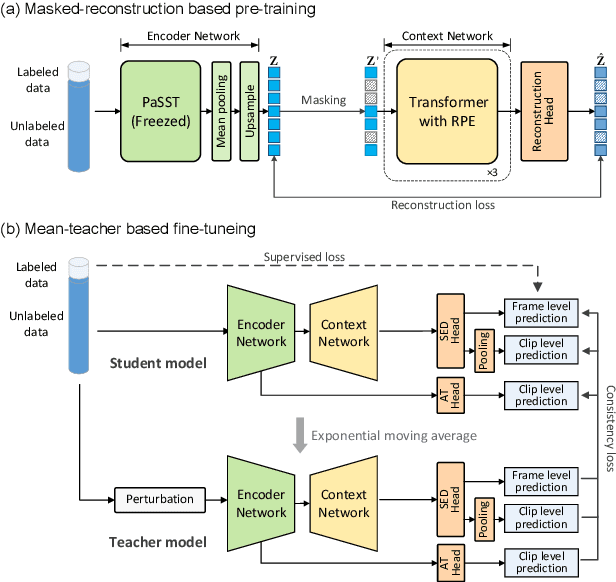

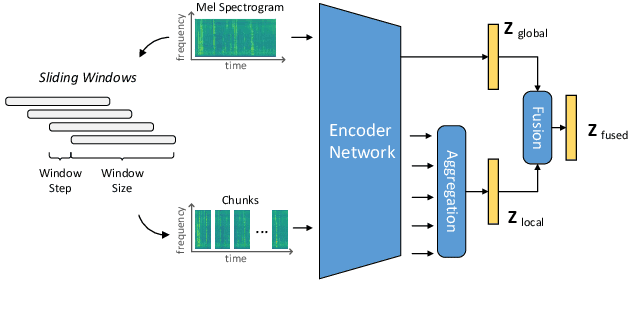

Sound event detection (SED) methods that leverage a large pre-trained Transformer encoder network have shown promising performance in recent DCASE challenges. However, they still rely on an RNN-based context network to model temporal dependencies, largely due to the scarcity of labeled data. In this work, we propose a pure Transformer-based SED model with masked-reconstruction based pre-training, termed MAT-SED. Specifically, a Transformer with relative positional encoding is first designed as the context network, pre-trained by the masked-reconstruction task on all available target data in a self-supervised way. Both the encoder and the context network are jointly fine-tuned in a semi-supervised manner. Furthermore, a global-local feature fusion strategy is proposed to enhance the localization capability. Evaluation of MAT-SED on DCASE2023 task4 surpasses state-of-the-art performance, achieving 0.587/0.896 PSDS1/PSDS2 respectively.
MAT-SED: AMasked Audio Transformer with Masked-Reconstruction Based Pre-training for Sound Event Detection
Aug 16, 2024Sound event detection (SED) methods that leverage a large pre-trained Transformer encoder network have shown promising performance in recent DCASE challenges. However, they still rely on an RNN-based context network to model temporal dependencies, largely due to the scarcity of labeled data. In this work, we propose a pure Transformer-based SED model with masked-reconstruction based pre-training, termed MAT-SED. Specifically, a Transformer with relative positional encoding is first designed as the context network, pre-trained by the masked-reconstruction task on all available target data in a self-supervised way. Both the encoder and the context network are jointly fine-tuned in a semi-supervised manner. Furthermore, a global-local feature fusion strategy is proposed to enhance the localization capability. Evaluation of MAT-SED on DCASE2023 task4 surpasses state-of-the-art performance, achieving 0.587/0.896 PSDS1/PSDS2 respectively.
Language Models are General-Purpose Interfaces
Jun 13, 2022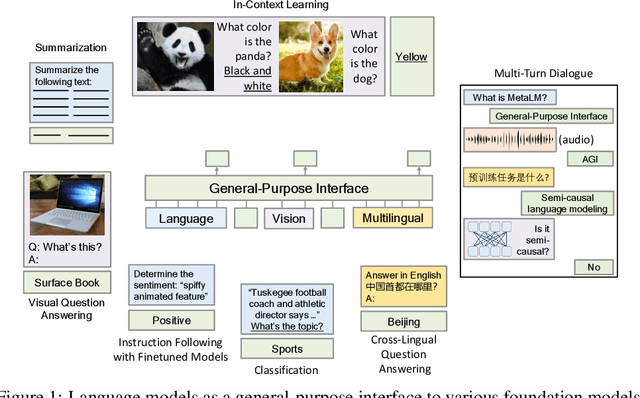

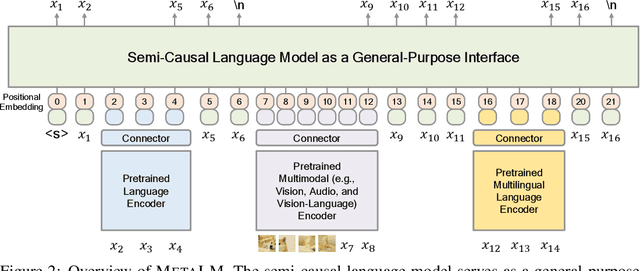
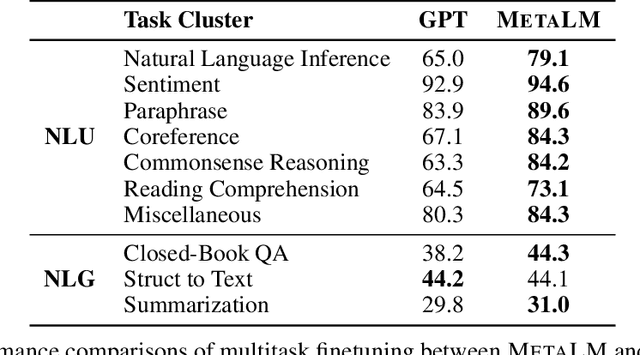
Foundation models have received much attention due to their effectiveness across a broad range of downstream applications. Though there is a big convergence in terms of architecture, most pretrained models are typically still developed for specific tasks or modalities. In this work, we propose to use language models as a general-purpose interface to various foundation models. A collection of pretrained encoders perceive diverse modalities (such as vision, and language), and they dock with a language model that plays the role of a universal task layer. We propose a semi-causal language modeling objective to jointly pretrain the interface and the modular encoders. We subsume the advantages and capabilities from both causal and non-causal modeling, thereby combining the best of two worlds. Specifically, the proposed method not only inherits the capabilities of in-context learning and open-ended generation from causal language modeling, but also is conducive to finetuning because of the bidirectional encoders. More importantly, our approach seamlessly unlocks the combinations of the above capabilities, e.g., enabling in-context learning or instruction following with finetuned encoders. Experimental results across various language-only and vision-language benchmarks show that our model outperforms or is competitive with specialized models on finetuning, zero-shot generalization, and few-shot learning.