 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAT-SED: AMasked Audio Transformer with Masked-Reconstruction Based Pre-training for Sound Event Detection
Paper and Code
Aug 16, 2024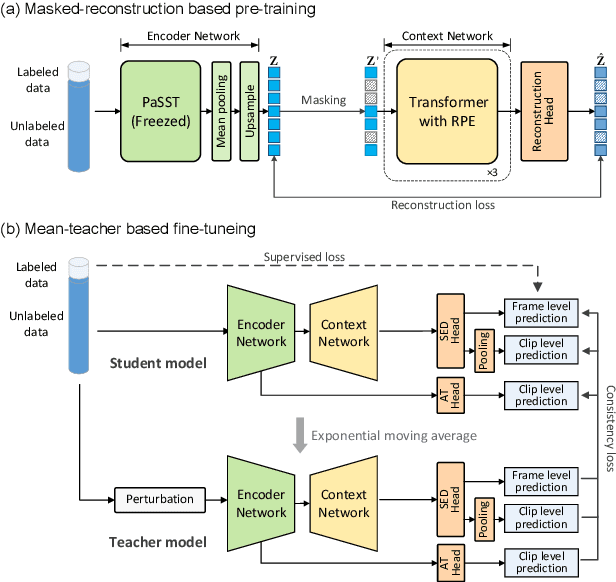

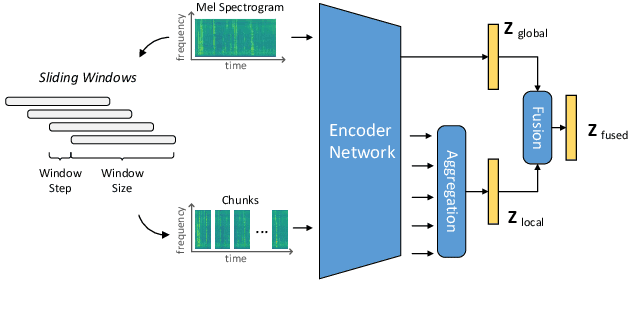

Sound event detection (SED) methods that leverage a large pre-trained Transformer encoder network have shown promising performance in recent DCASE challenges. However, they still rely on an RNN-based context network to model temporal dependencies, largely due to the scarcity of labeled data. In this work, we propose a pure Transformer-based SED model with masked-reconstruction based pre-training, termed MAT-SED. Specifically, a Transformer with relative positional encoding is first designed as the context network, pre-trained by the masked-reconstruction task on all available target data in a self-supervised way. Both the encoder and the context network are jointly fine-tuned in a semi-supervised manner. Furthermore, a global-local feature fusion strategy is proposed to enhance the localization capability. Evaluation of MAT-SED on DCASE2023 task4 surpasses state-of-the-art performance, achieving 0.587/0.896 PSDS1/PSDS2 respectively.