 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKling-Foley: Multimodal Diffusion Transformer for High-Quality Video-to-Audio Generation
Jun 24, 2025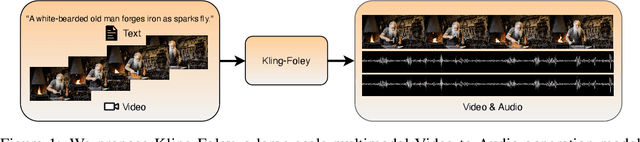
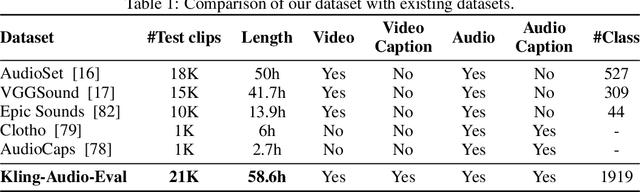
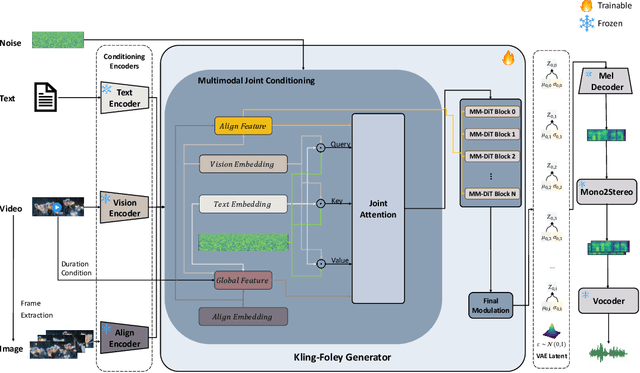
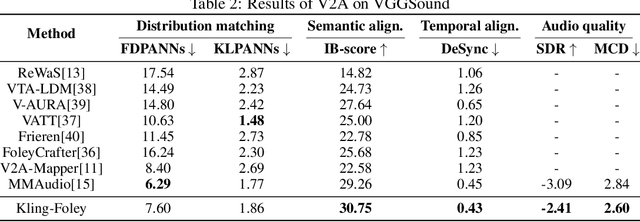
We propose Kling-Foley, a large-scale multimodal Video-to-Audio generation model that synthesizes high-quality audio synchronized with video content. In Kling-Foley, we introduce multimodal diffusion transformers to model the interactions between video, audio, and text modalities, and combine it with a visual semantic representation module and an audio-visual synchronization module to enhance alignment capabilities. Specifically, these modules align video conditions with latent audio elements at the frame level, thereby improving semantic alignment and audio-visual synchronization. Together with text conditions, this integrated approach enables precise generation of video-matching sound effects. In addition, we propose a universal latent audio codec that can achieve high-quality modeling in various scenarios such as sound effects, speech, singing, and music. We employ a stereo rendering method that imbues synthesized audio with a spatial presence. At the same time, in order to make up for the incomplete types and annotations of the open-source benchmark, we also open-source an industrial-level benchmark Kling-Audio-Eval. Our experiments show that Kling-Foley trained with the flow matching objective achieves new audio-visual SOTA performance among public models in terms of distribution matching, semantic alignment, temporal alignment and audio quality.
Physics-Constrained Flow Matching: Sampling Generative Models with Hard Constraints
Jun 04, 2025Deep generative models have recently been applied to physical systems governed by partial differential equations (PDEs), offering scalable simulation and uncertainty-aware inference. However, enforcing physical constraints, such as conservation laws (linear and nonlinear) and physical consistencies, remains challenging. Existing methods often rely on soft penalties or architectural biases that fail to guarantee hard constraints. In this work, we propose Physics-Constrained Flow Matching (PCFM), a zero-shot inference framework that enforces arbitrary nonlinear constraints in pretrained flow-based generative models. PCFM continuously guides the sampling process through physics-based corrections applied to intermediate solution states, while remaining aligned with the learned flow and satisfying physical constraints. Empirically, PCFM outperforms both unconstrained and constrained baselines on a range of PDEs, including those with shocks, discontinuities, and sharp features, while ensuring exact constraint satisfaction at the final solution. Our method provides a general framework for enforcing hard constraints in both scientific and general-purpose generative models, especially in applications where constraint satisfaction is essential.
Univariate Conditional Variational Autoencoder for Morphogenic Patterns Design in Frontal Polymerization-Based Manufacturing
Oct 23, 2024Rapid reaction-thermal diffusion during frontal polymerization (FP) with variations in initial and boundary conditions destabilizes the planar mode of front propagation, leading to spatially varying complex hierarchical patterns in polymeric materials. Although modern reaction-diffusion models can predict the patterns resulting from unstable FP, the inverse design of patterns, which aims to retrieve process conditions that produce a desired pattern, remains an open challenge due to the nonunique and nonintuitive mapping between process conditions and patterns. In this work, we propose a novel probabilistic generative model named univariate conditional variational autoencoder (UcVAE) for the inverse design of hierarchical patterns in FP-based manufacturing. Unlike the cVAE, which encodes both the design space and the design target, the UcVAE encodes only the design space. In the encoder of the UcVAE, the number of training parameters is significantly reduced compared to the cVAE, resulting in a shorter training time while maintaining comparable performance. Given desired pattern images, the trained UcVAE can generate multiple process condition solutions that produce high-fidelity hierarchical patterns.
Prototype based Masked Audio Model for Self-Supervised Learning of Sound Event Detection
Sep 26, 2024



A significant challenge in sound event detection (SED) is the effective utilization of unlabeled data, given the limited availability of labeled data due to high annotation costs. Semi-supervised algorithms rely on labeled data to learn from unlabeled data, and the performance is constrained by the quality and size of the former. In this paper, we introduce the Prototype based Masked Audio Model~(PMAM) algorithm for self-supervised representation learning in SED, to better exploit unlabeled data. Specifically, semantically rich frame-level pseudo labels are constructed from a Gaussian mixture model (GMM) based prototypical distribution modeling. These pseudo labels supervise the learning of a Transformer-based masked audio model, in which binary cross-entropy loss is employed instead of the widely used InfoNCE loss, to provide independent loss contributions from different prototypes, which is important in real scenarios in which multiple labels may apply to unsupervised data frames. A final stage of fine-tuning with just a small amount of labeled data yields a very high performing SED model. On like-for-like tests using the DESED task, our method achieves a PSDS1 score of 62.5\%, surpassing current state-of-the-art models and demonstrating the superiority of the proposed technique.
USTC-KXDIGIT System Description for ASVspoof5 Challenge
Sep 03, 2024
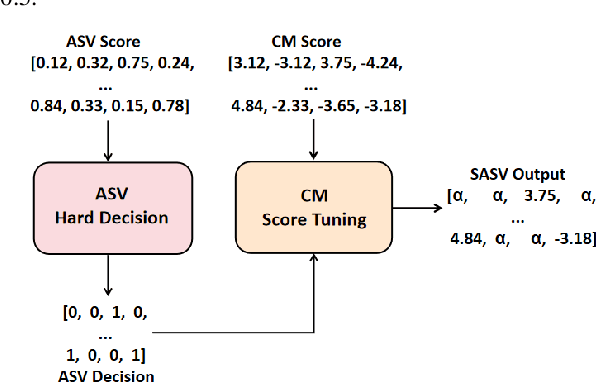
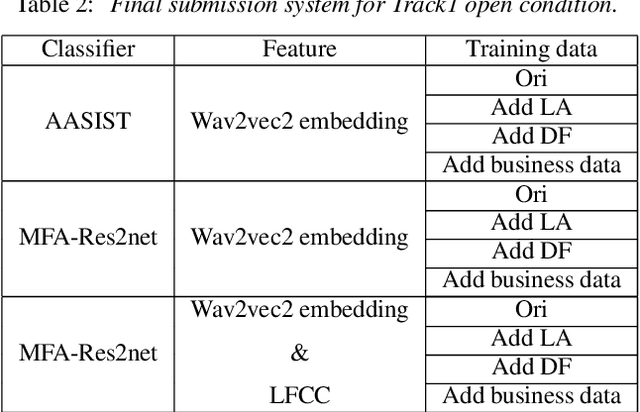
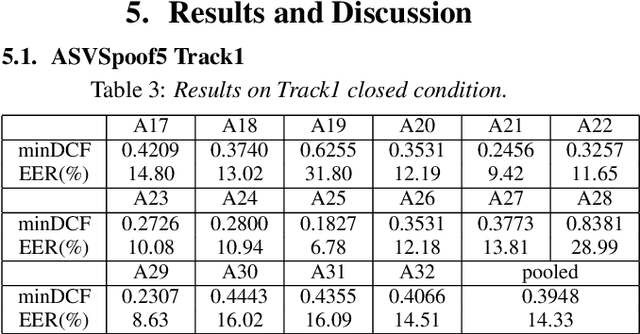
This paper describes the USTC-KXDIGIT system submitted to the ASVspoof5 Challenge for Track 1 (speech deepfake detection) and Track 2 (spoofing-robust automatic speaker verification, SASV). Track 1 showcases a diverse range of technical qualities from potential processing algorithms and includes both open and closed conditions. For these conditions, our system consists of a cascade of a frontend feature extractor and a back-end classifier. We focus on extensive embedding engineering and enhancing the generalization of the back-end classifier model. Specifically, the embedding engineering is based on hand-crafted features and speech representations from a self-supervised model, used for closed and open conditions, respectively. To detect spoof attacks under various adversarial conditions, we trained multiple systems on an augmented training set. Additionally, we used voice conversion technology to synthesize fake audio from genuine audio in the training set to enrich the synthesis algorithms. To leverage the complementary information learned by different model architectures, we employed activation ensemble and fused scores from different systems to obtain the final decision score for spoof detection. During the evaluation phase, the proposed methods achieved 0.3948 minDCF and 14.33% EER in the close condition, and 0.0750 minDCF and 2.59% EER in the open condition, demonstrating the robustness of our submitted systems under adversarial conditions. In Track 2, we continued using the CM system from Track 1 and fused it with a CNN-based ASV system. This approach achieved 0.2814 min-aDCF in the closed condition and 0.0756 min-aDCF in the open condition, showcasing superior performance in the SASV system.
MAT-SED: A Masked Audio Transformer with Masked-Reconstruction Based Pre-training for Sound Event Detection
Aug 19, 2024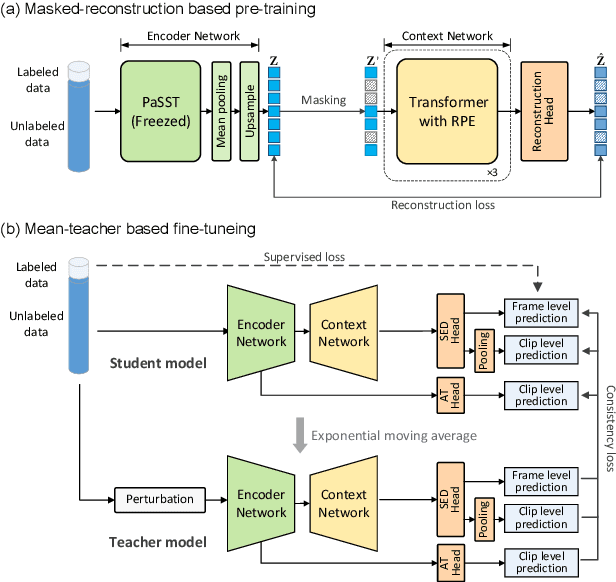

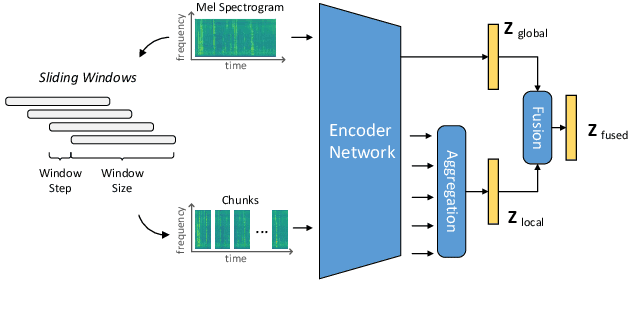

Sound event detection (SED) methods that leverage a large pre-trained Transformer encoder network have shown promising performance in recent DCASE challenges. However, they still rely on an RNN-based context network to model temporal dependencies, largely due to the scarcity of labeled data. In this work, we propose a pure Transformer-based SED model with masked-reconstruction based pre-training, termed MAT-SED. Specifically, a Transformer with relative positional encoding is first designed as the context network, pre-trained by the masked-reconstruction task on all available target data in a self-supervised way. Both the encoder and the context network are jointly fine-tuned in a semi-supervised manner. Furthermore, a global-local feature fusion strategy is proposed to enhance the localization capability. Evaluation of MAT-SED on DCASE2023 task4 surpasses state-of-the-art performance, achieving 0.587/0.896 PSDS1/PSDS2 respectively.
MAT-SED: AMasked Audio Transformer with Masked-Reconstruction Based Pre-training for Sound Event Detection
Aug 16, 2024Sound event detection (SED) methods that leverage a large pre-trained Transformer encoder network have shown promising performance in recent DCASE challenges. However, they still rely on an RNN-based context network to model temporal dependencies, largely due to the scarcity of labeled data. In this work, we propose a pure Transformer-based SED model with masked-reconstruction based pre-training, termed MAT-SED. Specifically, a Transformer with relative positional encoding is first designed as the context network, pre-trained by the masked-reconstruction task on all available target data in a self-supervised way. Both the encoder and the context network are jointly fine-tuned in a semi-supervised manner. Furthermore, a global-local feature fusion strategy is proposed to enhance the localization capability. Evaluation of MAT-SED on DCASE2023 task4 surpasses state-of-the-art performance, achieving 0.587/0.896 PSDS1/PSDS2 respectively.