 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReMA: Learning to Meta-think for LLMs with Multi-Agent Reinforcement Learning
Mar 12, 2025Recent research on Reasoning of Large Language Models (LLMs) has sought to further enhance their performance by integrating meta-thinking -- enabling models to monitor, evaluate, and control their reasoning processes for more adaptive and effective problem-solving. However, current single-agent work lacks a specialized design for acquiring meta-thinking, resulting in low efficacy. To address this challenge, we introduce Reinforced Meta-thinking Agents (ReMA), a novel framework that leverages Multi-Agent Reinforcement Learning (MARL) to elicit meta-thinking behaviors, encouraging LLMs to think about thinking. ReMA decouples the reasoning process into two hierarchical agents: a high-level meta-thinking agent responsible for generating strategic oversight and plans, and a low-level reasoning agent for detailed executions. Through iterative reinforcement learning with aligned objectives, these agents explore and learn collaboration, leading to improved generalization and robustness. Experimental results demonstrate that ReMA outperforms single-agent RL baselines on complex reasoning tasks, including competitive-level mathematical benchmarks and LLM-as-a-Judge benchmarks. Comprehensive ablation studies further illustrate the evolving dynamics of each distinct agent, providing valuable insights into how the meta-thinking reasoning process enhances the reasoning capabilities of LLMs.
ThinkBench: Dynamic Out-of-Distribution Evaluation for Robust LLM Reasoning
Feb 22, 2025Evaluating large language models (LLMs) poses significant challenges, particularly due to issues of data contamination and the leakage of correct answers. To address these challenges, we introduce ThinkBench, a novel evaluation framework designed to evaluate LLMs' reasoning capability robustly. ThinkBench proposes a dynamic data generation method for constructing out-of-distribution (OOD) datasets and offers an OOD dataset that contains 2,912 samples drawn from reasoning tasks. ThinkBench unifies the evaluation of reasoning models and non-reasoning models. We evaluate 16 LLMs and 4 PRMs under identical experimental conditions and show that most of the LLMs' performance are far from robust and they face a certain level of data leakage. By dynamically generating OOD datasets, ThinkBench effectively provides a reliable evaluation of LLMs and reduces the impact of data contamination.
From Target Tracking to Targeting Track -- Part II: Regularized Polynomial Trajectory Optimization
Feb 22, 2025Target tracking entails the estimation of the evolution of the target state over time, namely the target trajectory. Different from the classical state space model, our series of studies, including this paper, model the collection of the target state as a stochastic process (SP) that is further decomposed into a deterministic part which represents the trend of the trajectory and a residual SP representing the residual fitting error. Subsequently, the tracking problem is formulated as a learning problem regarding the trajectory SP for which a key part is to estimate a trajectory FoT (T-FoT) best fitting the measurements in time series. For this purpose, we consider the polynomial T-FoT and address the regularized polynomial T-FoT optimization employing two distinct regularization strategies seeking trade-off between the accuracy and simplicity. One limits the order of the polynomial and then the best choice is determined by grid searching in a narrow, bounded range while the other adopts $\ell_0$ norm regularization for which the hybrid Newton solver is employed. Simulation results obtained in both single and multiple maneuvering target scenarios demonstrate the effectiveness of our approaches.
FIND: Fine-grained Information Density Guided Adaptive Retrieval-Augmented Generation for Disease Diagnosis
Feb 20, 2025Retrieval-Augmented Large Language Models (LLMs), which integrate external knowledge into LLMs, have shown remarkable performance in various medical domains, including clinical diagnosis. However, existing RAG methods struggle to effectively assess task difficulty to make retrieval decisions, thereby failing to meet the clinical requirements for balancing efficiency and accuracy. So in this paper, we propose FIND (\textbf{F}ine-grained \textbf{In}formation \textbf{D}ensity Guided Adaptive RAG), a novel framework that improves the reliability of RAG in disease diagnosis scenarios. FIND incorporates a fine-grained adaptive control module to determine whether retrieval is necessary based on the information density of the input. By optimizing the retrieval process and implementing a knowledge filtering module, FIND ensures that the retrieval is better suited to clinical scenarios. Experiments on three Chinese electronic medical record datasets demonstrate that FIND significantly outperforms various baseline methods, highlighting its effectiveness in clinical diagnosis tasks.
OpenR: An Open Source Framework for Advanced Reasoning with Large Language Models
Oct 12, 2024



In this technical report, we introduce OpenR, an open-source framework designed to integrate key components for enhancing the reasoning capabilities of large language models (LLMs). OpenR unifies data acquisition, reinforcement learning training (both online and offline), and non-autoregressive decoding into a cohesive software platform. Our goal is to establish an open-source platform and community to accelerate the development of LLM reasoning. Inspired by the success of OpenAI's o1 model, which demonstrated improved reasoning abilities through step-by-step reasoning and reinforcement learning, OpenR integrates test-time compute, reinforcement learning, and process supervision to improve reasoning in LLMs. Our work is the first to provide an open-source framework that explores the core techniques of OpenAI's o1 model with reinforcement learning, achieving advanced reasoning capabilities beyond traditional autoregressive methods. We demonstrate the efficacy of OpenR by evaluating it on the MATH dataset, utilising publicly available data and search methods. Our initial experiments confirm substantial gains, with relative improvements in reasoning and performance driven by test-time computation and reinforcement learning through process reward models. The OpenR framework, including code, models, and datasets, is accessible at https://openreasoner.github.io.
Efficient Reinforcement Learning with Large Language Model Priors
Oct 10, 2024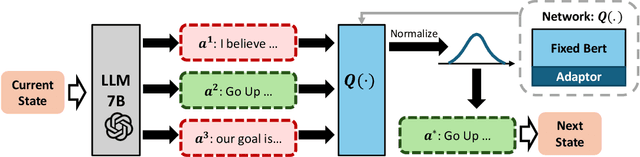
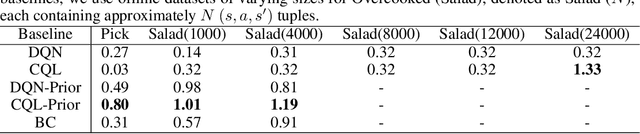
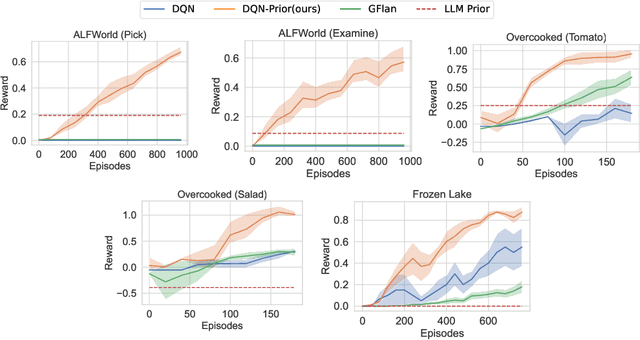
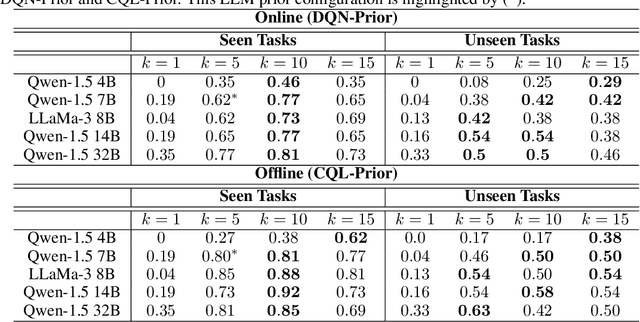
In sequential decision-making (SDM) tasks, methods like reinforcement learning (RL) and heuristic search have made notable advances in specific cases. However, they often require extensive exploration and face challenges in generalizing across diverse environments due to their limited grasp of the underlying decision dynamics. In contrast, large language models (LLMs) have recently emerged as powerful general-purpose tools, due to their capacity to maintain vast amounts of domain-specific knowledge. To harness this rich prior knowledge for efficiently solving complex SDM tasks, we propose treating LLMs as prior action distributions and integrating them into RL frameworks through Bayesian inference methods, making use of variational inference and direct posterior sampling. The proposed approaches facilitate the seamless incorporation of fixed LLM priors into both policy-based and value-based RL frameworks. Our experiments show that incorporating LLM-based action priors significantly reduces exploration and optimization complexity, substantially improving sample efficiency compared to traditional RL techniques, e.g., using LLM priors decreases the number of required samples by over 90% in offline learning scenarios.
Prototype based Masked Audio Model for Self-Supervised Learning of Sound Event Detection
Sep 26, 2024A significant challenge in sound event detection (SED) is the effective utilization of unlabeled data, given the limited availability of labeled data due to high annotation costs. Semi-supervised algorithms rely on labeled data to learn from unlabeled data, and the performance is constrained by the quality and size of the former. In this paper, we introduce the Prototype based Masked Audio Model~(PMAM) algorithm for self-supervised representation learning in SED, to better exploit unlabeled data. Specifically, semantically rich frame-level pseudo labels are constructed from a Gaussian mixture model (GMM) based prototypical distribution modeling. These pseudo labels supervise the learning of a Transformer-based masked audio model, in which binary cross-entropy loss is employed instead of the widely used InfoNCE loss, to provide independent loss contributions from different prototypes, which is important in real scenarios in which multiple labels may apply to unsupervised data frames. A final stage of fine-tuning with just a small amount of labeled data yields a very high performing SED model. On like-for-like tests using the DESED task, our method achieves a PSDS1 score of 62.5\%, surpassing current state-of-the-art models and demonstrating the superiority of the proposed technique.
USTC-KXDIGIT System Description for ASVspoof5 Challenge
Sep 03, 2024
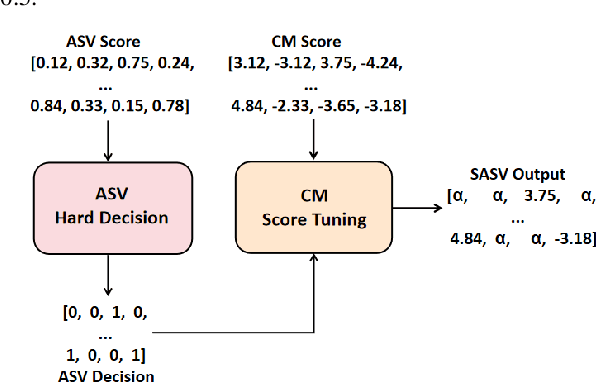
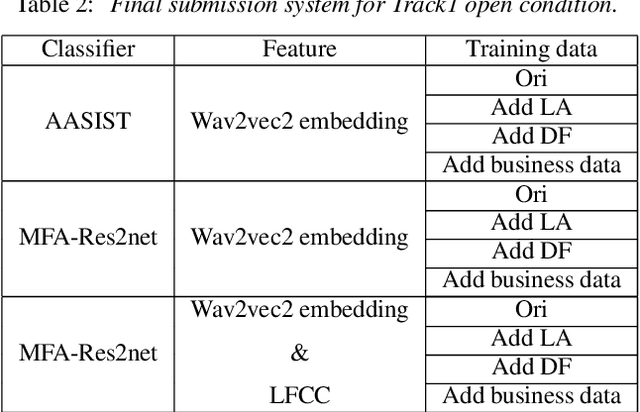
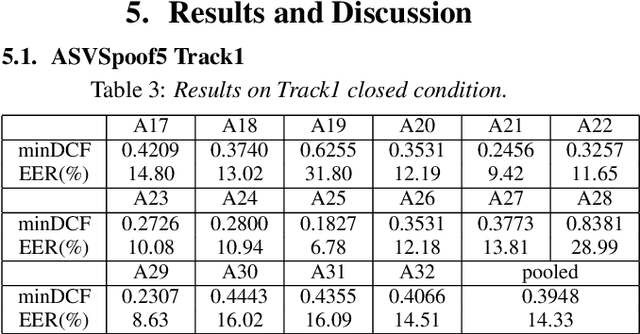
This paper describes the USTC-KXDIGIT system submitted to the ASVspoof5 Challenge for Track 1 (speech deepfake detection) and Track 2 (spoofing-robust automatic speaker verification, SASV). Track 1 showcases a diverse range of technical qualities from potential processing algorithms and includes both open and closed conditions. For these conditions, our system consists of a cascade of a frontend feature extractor and a back-end classifier. We focus on extensive embedding engineering and enhancing the generalization of the back-end classifier model. Specifically, the embedding engineering is based on hand-crafted features and speech representations from a self-supervised model, used for closed and open conditions, respectively. To detect spoof attacks under various adversarial conditions, we trained multiple systems on an augmented training set. Additionally, we used voice conversion technology to synthesize fake audio from genuine audio in the training set to enrich the synthesis algorithms. To leverage the complementary information learned by different model architectures, we employed activation ensemble and fused scores from different systems to obtain the final decision score for spoof detection. During the evaluation phase, the proposed methods achieved 0.3948 minDCF and 14.33% EER in the close condition, and 0.0750 minDCF and 2.59% EER in the open condition, demonstrating the robustness of our submitted systems under adversarial conditions. In Track 2, we continued using the CM system from Track 1 and fused it with a CNN-based ASV system. This approach achieved 0.2814 min-aDCF in the closed condition and 0.0756 min-aDCF in the open condition, showcasing superior performance in the SASV system.
MAT-SED: A Masked Audio Transformer with Masked-Reconstruction Based Pre-training for Sound Event Detection
Aug 19, 2024Sound event detection (SED) methods that leverage a large pre-trained Transformer encoder network have shown promising performance in recent DCASE challenges. However, they still rely on an RNN-based context network to model temporal dependencies, largely due to the scarcity of labeled data. In this work, we propose a pure Transformer-based SED model with masked-reconstruction based pre-training, termed MAT-SED. Specifically, a Transformer with relative positional encoding is first designed as the context network, pre-trained by the masked-reconstruction task on all available target data in a self-supervised way. Both the encoder and the context network are jointly fine-tuned in a semi-supervised manner. Furthermore, a global-local feature fusion strategy is proposed to enhance the localization capability. Evaluation of MAT-SED on DCASE2023 task4 surpasses state-of-the-art performance, achieving 0.587/0.896 PSDS1/PSDS2 respectively.
MAT-SED: AMasked Audio Transformer with Masked-Reconstruction Based Pre-training for Sound Event Detection
Aug 16, 2024Sound event detection (SED) methods that leverage a large pre-trained Transformer encoder network have shown promising performance in recent DCASE challenges. However, they still rely on an RNN-based context network to model temporal dependencies, largely due to the scarcity of labeled data. In this work, we propose a pure Transformer-based SED model with masked-reconstruction based pre-training, termed MAT-SED. Specifically, a Transformer with relative positional encoding is first designed as the context network, pre-trained by the masked-reconstruction task on all available target data in a self-supervised way. Both the encoder and the context network are jointly fine-tuned in a semi-supervised manner. Furthermore, a global-local feature fusion strategy is proposed to enhance the localization capability. Evaluation of MAT-SED on DCASE2023 task4 surpasses state-of-the-art performance, achieving 0.587/0.896 PSDS1/PSDS2 respectively.