 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-DPO: Improving Data Utilization in Direct Preference Optimization Using a Guiding Reference Model
Apr 22, 2025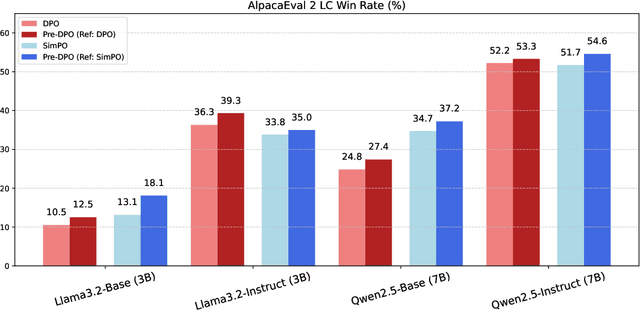
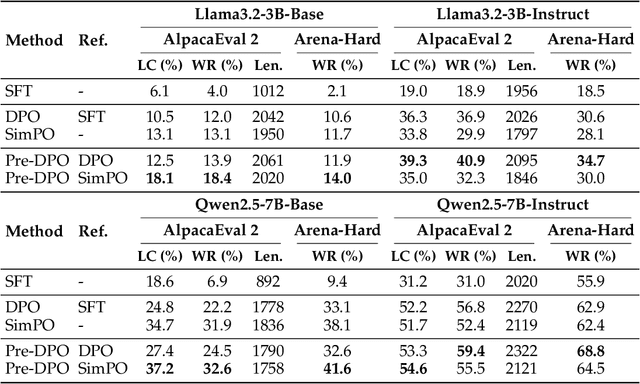
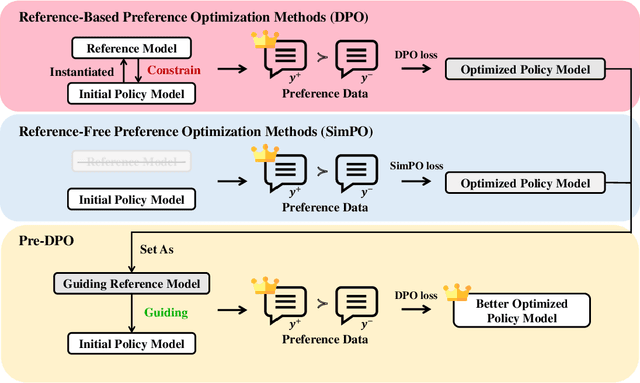
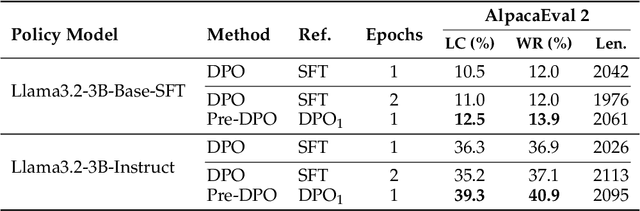
Direct Preference Optimization (DPO) simplifies reinforcement learning from human feedback (RLHF) for large language models (LLMs) by directly optimizing human preferences without an explicit reward model. We find that during DPO training, the reference model plays the role of a data weight adjuster. However, the common practice of initializing the policy and reference models identically in DPO can lead to inefficient data utilization and impose a performance ceiling. Meanwhile, the lack of a reference model in Simple Preference Optimization (SimPO) reduces training robustness and necessitates stricter conditions to prevent catastrophic forgetting. In this work, we propose Pre-DPO, a simple yet effective DPO-based training paradigm that enhances preference optimization performance by leveraging a guiding reference model. This reference model provides foresight into the optimal policy state achievable through the training preference data, serving as a guiding mechanism that adaptively assigns higher weights to samples more suitable for the model and lower weights to those less suitable. Extensive experiments on AlpacaEval 2.0 and Arena-Hard v0.1 benchmarks demonstrate that Pre-DPO consistently improves the performance of both DPO and SimPO, without relying on external models or additional data.
ThinkBench: Dynamic Out-of-Distribution Evaluation for Robust LLM Reasoning
Feb 22, 2025Evaluating large language models (LLMs) poses significant challenges, particularly due to issues of data contamination and the leakage of correct answers. To address these challenges, we introduce ThinkBench, a novel evaluation framework designed to evaluate LLMs' reasoning capability robustly. ThinkBench proposes a dynamic data generation method for constructing out-of-distribution (OOD) datasets and offers an OOD dataset that contains 2,912 samples drawn from reasoning tasks. ThinkBench unifies the evaluation of reasoning models and non-reasoning models. We evaluate 16 LLMs and 4 PRMs under identical experimental conditions and show that most of the LLMs' performance are far from robust and they face a certain level of data leakage. By dynamically generating OOD datasets, ThinkBench effectively provides a reliable evaluation of LLMs and reduces the impact of data contamination.
UltraWiki: Ultra-fine-grained Entity Set Expansion with Negative Seed Entities
Mar 07, 2024



Entity Set Expansion (ESE) aims to identify new entities belonging to the same semantic class as a given set of seed entities. Traditional methods primarily relied on positive seed entities to represent a target semantic class, which poses challenge for the representation of ultra-fine-grained semantic classes. Ultra-fine-grained semantic classes are defined based on fine-grained semantic classes with more specific attribute constraints. Describing it with positive seed entities alone cause two issues: (i) Ambiguity among ultra-fine-grained semantic classes. (ii) Inability to define "unwanted" semantic. Due to these inherent shortcomings, previous methods struggle to address the ultra-fine-grained ESE (Ultra-ESE). To solve this issue, we first introduce negative seed entities in the inputs, which belong to the same fine-grained semantic class as the positive seed entities but differ in certain attributes. Negative seed entities eliminate the semantic ambiguity by contrast between positive and negative attributes. Meanwhile, it provide a straightforward way to express "unwanted". To assess model performance in Ultra-ESE, we constructed UltraWiki, the first large-scale dataset tailored for Ultra-ESE. UltraWiki encompasses 236 ultra-fine-grained semantic classes, where each query of them is represented with 3-5 positive and negative seed entities. A retrieval-based framework RetExpan and a generation-based framework GenExpan are proposed to comprehensively assess the efficacy of large language models from two different paradigms in Ultra-ESE. Moreover, we devised three strategies to enhance models' comprehension of ultra-fine-grained entities semantics: contrastive learning, retrieval augmentation, and chain-of-thought reasoning. Extensive experiments confirm the effectiveness of our proposed strategies and also reveal that there remains a large space for improvement in Ultra-ESE.
EcomGPT-CT: Continual Pre-training of E-commerce Large Language Models with Semi-structured Data
Dec 25, 2023Large Language Models (LLMs) pre-trained on massive corpora have exhibited remarkable performance on various NLP tasks. However, applying these models to specific domains still poses significant challenges, such as lack of domain knowledge, limited capacity to leverage domain knowledge and inadequate adaptation to domain-specific data formats. Considering the exorbitant cost of training LLMs from scratch and the scarcity of annotated data within particular domains, in this work, we focus on domain-specific continual pre-training of LLMs using E-commerce domain as an exemplar. Specifically, we explore the impact of continual pre-training on LLMs employing unlabeled general and E-commercial corpora. Furthermore, we design a mixing strategy among different data sources to better leverage E-commercial semi-structured data. We construct multiple tasks to assess LLMs' few-shot In-context Learning ability and their zero-shot performance after instruction tuning in E-commerce domain. Experimental results demonstrate the effectiveness of continual pre-training of E-commerce LLMs and the efficacy of our devised data mixing strategy.
LatEval: An Interactive LLMs Evaluation Benchmark with Incomplete Information from Lateral Thinking Puzzles
Aug 21, 2023



With the continuous evolution and refinement of LLMs, they are endowed with impressive logical reasoning or vertical thinking capabilities. But can they think out of the box? Do they possess proficient lateral thinking abilities? Following the setup of Lateral Thinking Puzzles, we propose a novel evaluation benchmark, LatEval, which assesses the model's lateral thinking within an interactive framework. In our benchmark, we challenge LLMs with 2 aspects: the quality of questions posed by the model and the model's capability to integrate information for problem-solving. We find that nearly all LLMs struggle with employing lateral thinking during interactions. For example, even the most advanced model, GPT-4, exhibits the advantage to some extent, yet still maintain a noticeable gap when compared to human. This evaluation benchmark provides LLMs with a highly challenging and distinctive task that is crucial to an effective AI assistant.
MESED: A Multi-modal Entity Set Expansion Dataset with Fine-grained Semantic Classes and Hard Negative Entities
Jul 27, 2023The Entity Set Expansion (ESE) task aims to expand a handful of seed entities with new entities belonging to the same semantic class. Conventional ESE methods are based on mono-modality (i.e., literal modality), which struggle to deal with complex entities in the real world such as: (1) Negative entities with fine-grained semantic differences. (2) Synonymous entities. (3) Polysemous entities. (4) Long-tailed entities. These challenges prompt us to propose Multi-modal Entity Set Expansion (MESE), where models integrate information from multiple modalities to represent entities. Intuitively, the benefits of multi-modal information for ESE are threefold: (1) Different modalities can provide complementary information. (2) Multi-modal information provides a unified signal via common visual properties for the same semantic class or entity. (3) Multi-modal information offers robust alignment signal for synonymous entities. To assess the performance of model in MESE and facilitate further research, we constructed the MESED dataset which is the first multi-modal dataset for ESE with large-scale and elaborate manual calibration. A powerful multi-modal model MultiExpan is proposed which is pre-trained on four multimodal pre-training tasks. The extensive experiments and analyses on MESED demonstrate the high quality of the dataset and the effectiveness of our MultiExpan, as well as pointing the direction for future research.
Progressive Multi-task Learning Framework for Chinese Text Error Correction
Jul 03, 2023
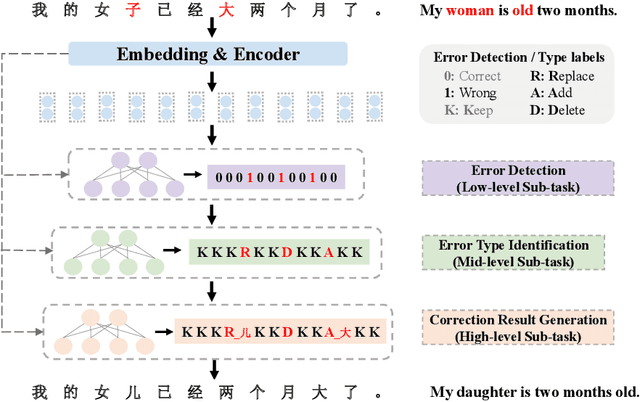
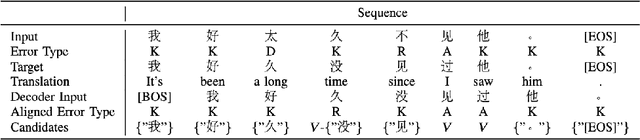

Chinese Text Error Correction (CTEC) aims to detect and correct errors in the input text, which benefits human's daily life and various downstream tasks. Recent approaches mainly employ Pre-trained Language Models (PLMs) to resolve CTEC task and achieve tremendous success. However, previous approaches suffer from issues of over-correction and under-correction, and the former is especially conspicuous in the precision-critical CTEC task. To mitigate the issue of overcorrection, we propose a novel model-agnostic progressive multitask learning framework for CTEC, named ProTEC, which guides a CTEC model to learn the task from easy to difficult. We divide CTEC task into three sub-tasks from easy to difficult: Error Detection, Error Type Identification, and Correction Result Generation. During the training process, ProTEC guides the model to learn text error correction progressively by incorporating these sub-tasks into a multi-task training objective. During the inference process, the model completes these sub-tasks in turn to generate the correction results. Extensive experiments and detailed analyses fully demonstrate the effectiveness and efficiency of our proposed framework.
From Retrieval to Generation: Efficient and Effective Entity Set Expansion
Apr 07, 2023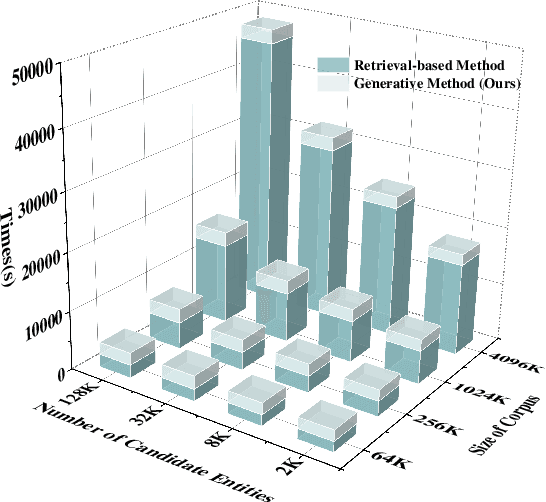
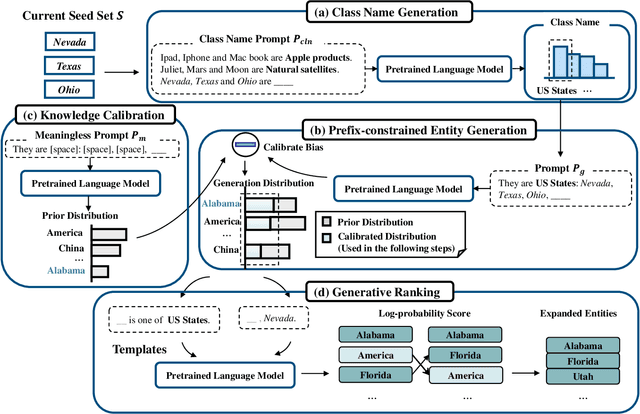

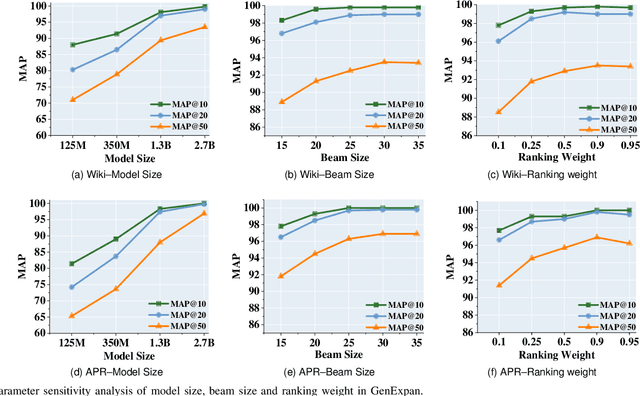
Entity Set Expansion (ESE) is a critical task aiming to expand entities of the target semantic class described by a small seed entity set. Most existing ESE methods are retrieval-based frameworks that need to extract the contextual features of entities and calculate the similarity between seed entities and candidate entities. To achieve the two purposes, they should iteratively traverse the corpus and the entity vocabulary provided in the datasets, resulting in poor efficiency and scalability. The experimental results indicate that the time consumed by the retrieval-based ESE methods increases linearly with entity vocabulary and corpus size. In this paper, we firstly propose a generative ESE framework, Generative Entity Set Expansion (GenExpan), which utilizes a generative pre-trained language model to accomplish ESE task. Specifically, a prefix tree is employed to guarantee the validity of entity generation, and automatically generated class names are adopted to guide the model to generate target entities. Moreover, we propose Knowledge Calibration and Generative Ranking to further bridge the gap between generic knowledge of the language model and the goal of ESE task. Experiments on publicly available datasets show that GenExpan is efficient and effective. For efficiency, expansion time consumed by GenExpan is independent of entity vocabulary and corpus size, and GenExpan achieves an average 600% speedup compared to strong baselines. For expansion performance, our framework outperforms previous state-of-the-art ESE methods.
Towards Attribute-Entangled Controllable Text Generation: A Pilot Study of Blessing Generation
Oct 29, 2022
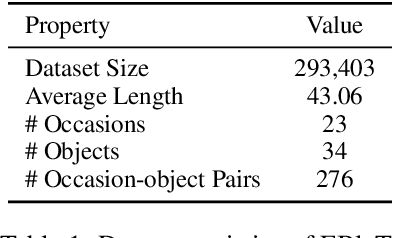
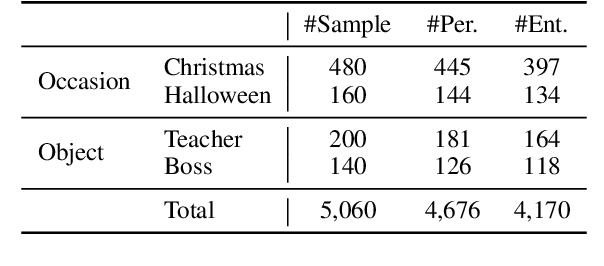
Controllable Text Generation (CTG) has obtained great success due to its fine-grained generation ability obtained by focusing on multiple attributes. However, most existing CTG researches overlook how to utilize the attribute entanglement to enhance the diversity of the controlled generated texts. Facing this dilemma, we focus on a novel CTG scenario, i.e., blessing generation which is challenging because high-quality blessing texts require CTG models to comprehensively consider the entanglement between multiple attributes (e.g., objects and occasions). To promote the research on blessing generation, we present EBleT, a large-scale Entangled Blessing Text dataset containing 293K English sentences annotated with multiple attributes. Furthermore, we propose novel evaluation metrics to measure the quality of the blessing texts generated by the baseline models we designed. Our study opens a new research direction for controllable text generation and enables the development of attribute-entangled CTG models. Our dataset and source codes are available at \url{https://github.com/huangshulin123/Blessing-Generation}.
Learning from the Dictionary: Heterogeneous Knowledge Guided Fine-tuning for Chinese Spell Checking
Oct 19, 2022
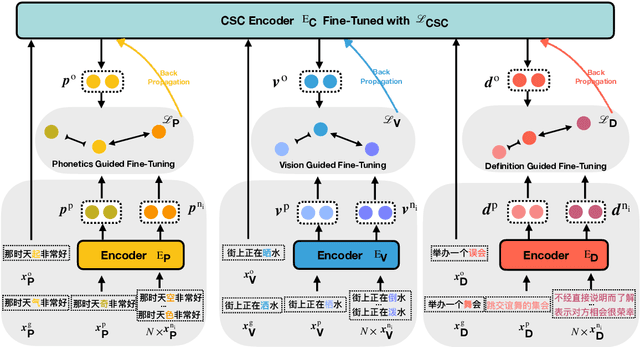
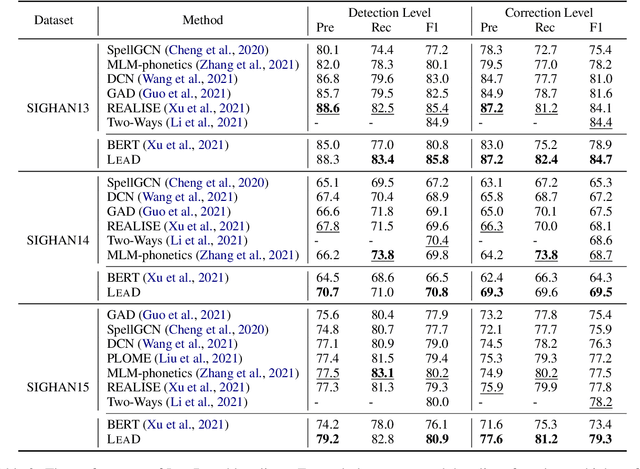

Chinese Spell Checking (CSC) aims to detect and correct Chinese spelling errors. Recent researches start from the pretrained knowledge of language models and take multimodal information into CSC models to improve the performance. However, they overlook the rich knowledge in the dictionary, the reference book where one can learn how one character should be pronounced, written, and used. In this paper, we propose the LEAD framework, which renders the CSC model to learn heterogeneous knowledge from the dictionary in terms of phonetics, vision, and meaning. LEAD first constructs positive and negative samples according to the knowledge of character phonetics, glyphs, and definitions in the dictionary. Then a unified contrastive learning-based training scheme is employed to refine the representations of the CSC models. Extensive experiments and detailed analyses on the SIGHAN benchmark datasets demonstrate the effectiveness of our proposed methods.