 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from the Dictionary: Heterogeneous Knowledge Guided Fine-tuning for Chinese Spell Checking
Oct 19, 2022
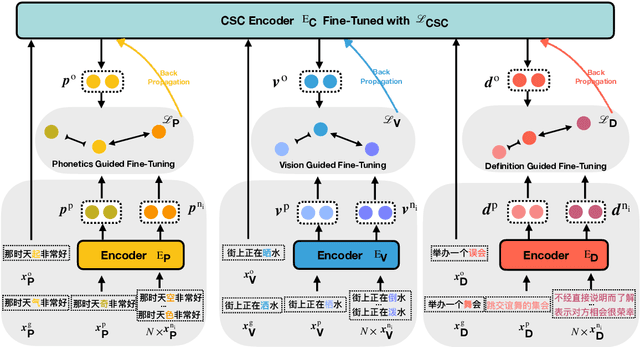
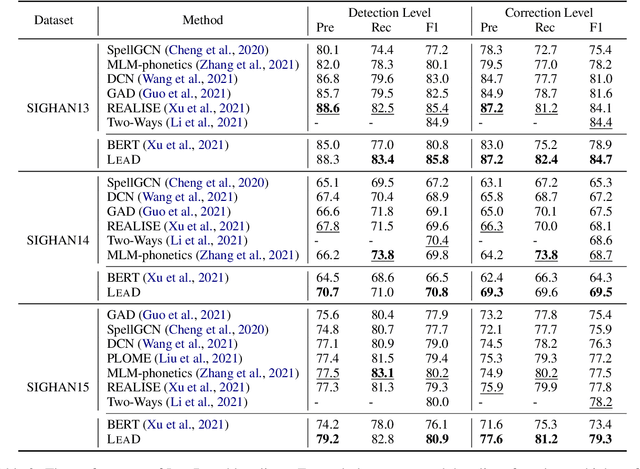

Chinese Spell Checking (CSC) aims to detect and correct Chinese spelling errors. Recent researches start from the pretrained knowledge of language models and take multimodal information into CSC models to improve the performance. However, they overlook the rich knowledge in the dictionary, the reference book where one can learn how one character should be pronounced, written, and used. In this paper, we propose the LEAD framework, which renders the CSC model to learn heterogeneous knowledge from the dictionary in terms of phonetics, vision, and meaning. LEAD first constructs positive and negative samples according to the knowledge of character phonetics, glyphs, and definitions in the dictionary. Then a unified contrastive learning-based training scheme is employed to refine the representations of the CSC models. Extensive experiments and detailed analyses on the SIGHAN benchmark datasets demonstrate the effectiveness of our proposed methods.
Linguistic Rules-Based Corpus Generation for Native Chinese Grammatical Error Correction
Oct 19, 2022
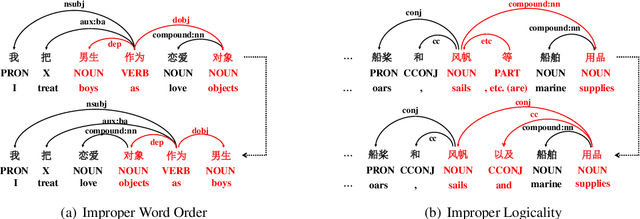
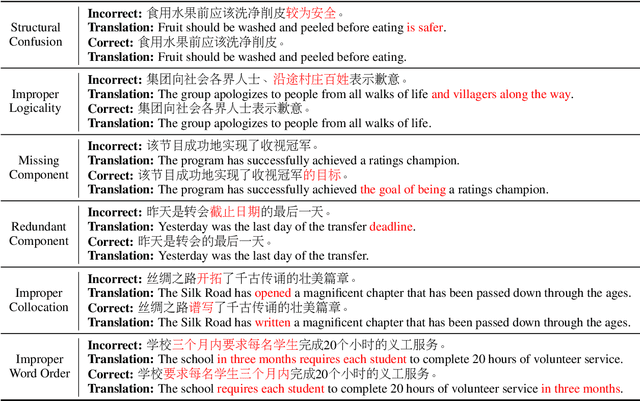
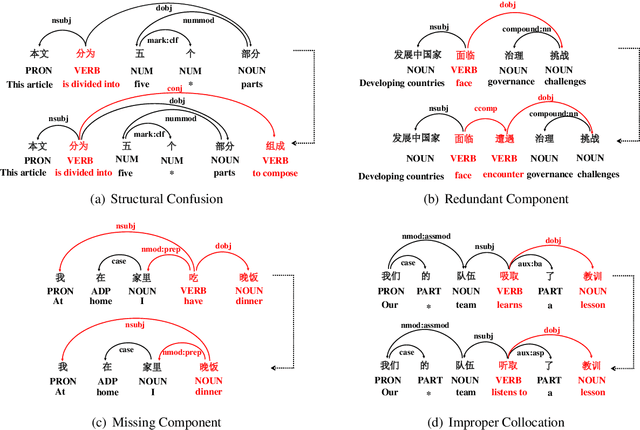
Chinese Grammatical Error Correction (CGEC) is both a challenging NLP task and a common application in human daily life. Recently, many data-driven approaches are proposed for the development of CGEC research. However, there are two major limitations in the CGEC field: First, the lack of high-quality annotated training corpora prevents the performance of existing CGEC models from being significantly improved. Second, the grammatical errors in widely used test sets are not made by native Chinese speakers, resulting in a significant gap between the CGEC models and the real application. In this paper, we propose a linguistic rules-based approach to construct large-scale CGEC training corpora with automatically generated grammatical errors. Additionally, we present a challenging CGEC benchmark derived entirely from errors made by native Chinese speakers in real-world scenarios. Extensive experiments and detailed analyses not only demonstrate that the training data constructed by our method effectively improves the performance of CGEC models, but also reflect that our benchmark is an excellent resource for further development of the CGEC field.
Learning Purified Feature Representations from Task-irrelevant Labels
Feb 22, 2021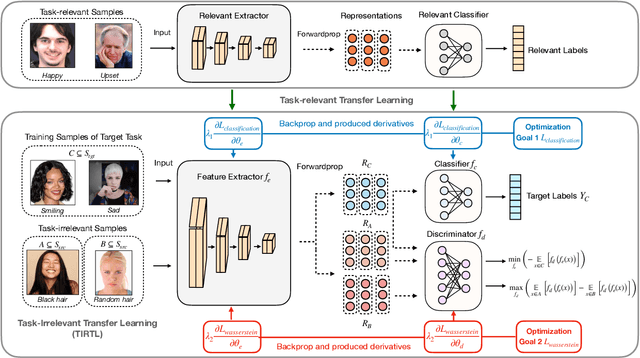
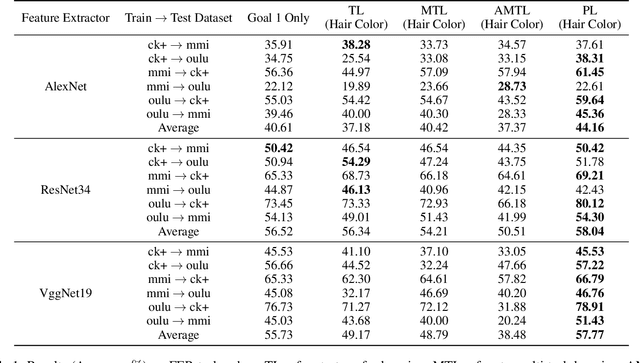
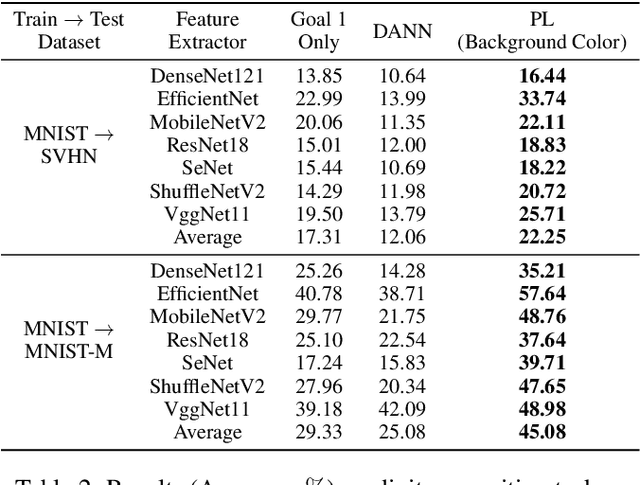
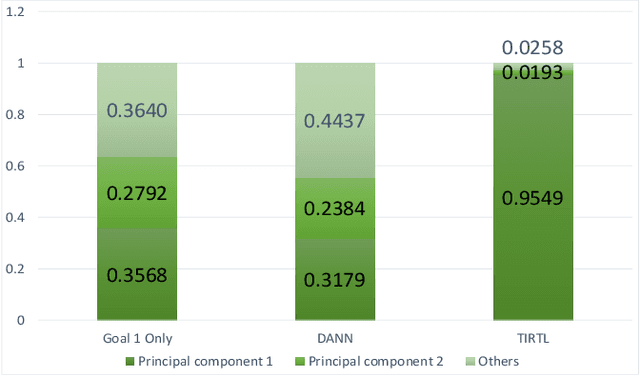
Learning an empirically effective model with generalization using limited data is a challenging task for deep neural networks. In this paper, we propose a novel learning framework called PurifiedLearning to exploit task-irrelevant features extracted from task-irrelevant labels when training models on small-scale datasets. Particularly, we purify feature representations by using the expression of task-irrelevant information, thus facilitating the learning process of classification. Our work is built on solid theoretical analysis and extensive experiments, which demonstrate the effectiveness of PurifiedLearning. According to the theory we proved, PurifiedLearning is model-agnostic and doesn't have any restrictions on the model needed, so it can be combined with any existing deep neural networks with ease to achieve better performance. The source code of this paper will be available in the future for reproducibility.