 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Adaptive Conformal Inference for Large-Scale Out-of-Distribution Testing
May 26, 2026This paper addresses structured out-of-distribution (OOD) testing in high-stakes machine learning applications. Traditional conformal methods rely on joint exchangeability, making it difficult to incorporate auxiliary information such as spatiotemporal or grouping structures. To overcome this limitation, we propose the structure-adaptive conformal q-value (SCQ), a significance index that integrates individual test evidence with structural patterns. We also develop pseudo-score-guided transductive automated model selection (P-TAMS), which adapts conformalized model selection to structured OOD testing across a toolbox of candidate models. Together, SCQ and P-TAMS form a unified framework under pairwise exchangeability, providing finite-sample error-rate control, improved power, and enhanced interpretability. Experiments on simulated and real data demonstrate that the proposed approach controls the false discovery rate and performs well across diverse settings.
Linguistic Rules-Based Corpus Generation for Native Chinese Grammatical Error Correction
Oct 19, 2022
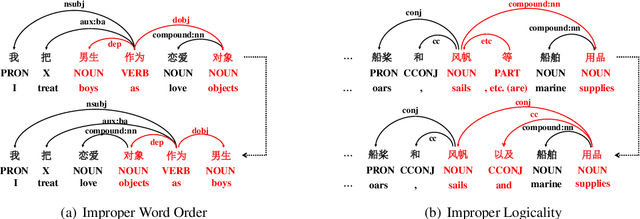
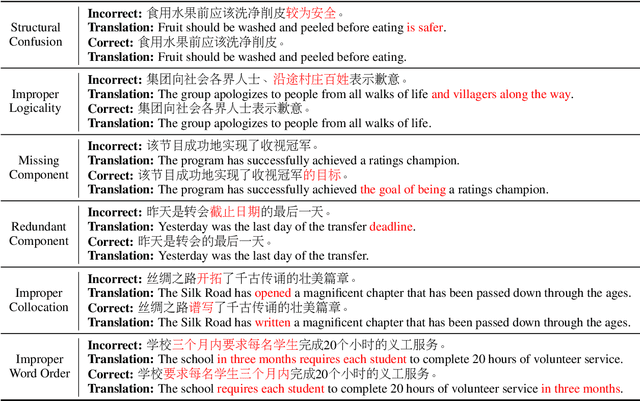
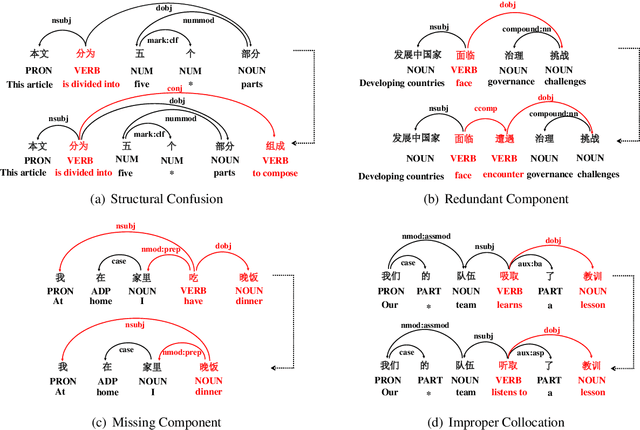
Chinese Grammatical Error Correction (CGEC) is both a challenging NLP task and a common application in human daily life. Recently, many data-driven approaches are proposed for the development of CGEC research. However, there are two major limitations in the CGEC field: First, the lack of high-quality annotated training corpora prevents the performance of existing CGEC models from being significantly improved. Second, the grammatical errors in widely used test sets are not made by native Chinese speakers, resulting in a significant gap between the CGEC models and the real application. In this paper, we propose a linguistic rules-based approach to construct large-scale CGEC training corpora with automatically generated grammatical errors. Additionally, we present a challenging CGEC benchmark derived entirely from errors made by native Chinese speakers in real-world scenarios. Extensive experiments and detailed analyses not only demonstrate that the training data constructed by our method effectively improves the performance of CGEC models, but also reflect that our benchmark is an excellent resource for further development of the CGEC field.
The Past Mistake is the Future Wisdom: Error-driven Contrastive Probability Optimization for Chinese Spell Checking
Mar 02, 2022
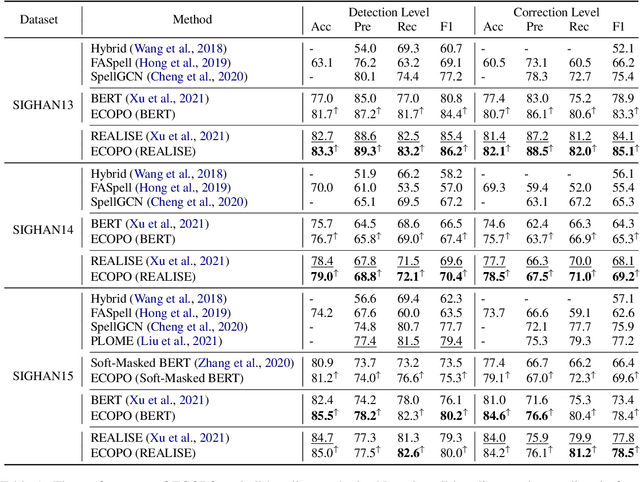
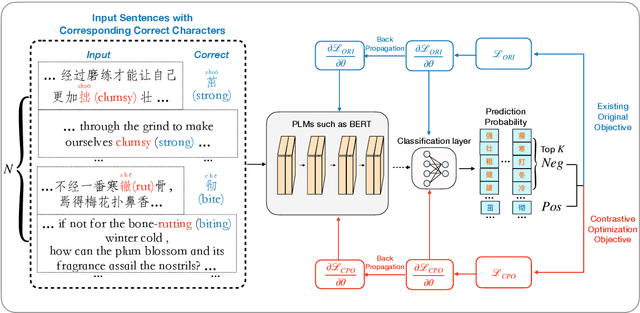
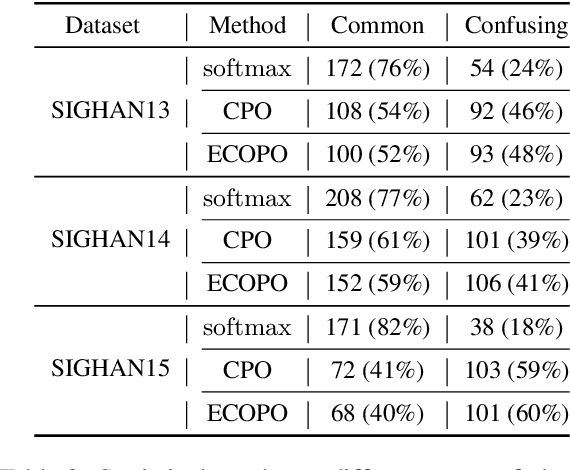
Chinese Spell Checking (CSC) aims to detect and correct Chinese spelling errors, which are mainly caused by the phonological or visual similarity. Recently, pre-trained language models (PLMs) promote the progress of CSC task. However, there exists a gap between the learned knowledge of PLMs and the goal of CSC task. PLMs focus on the semantics in text and tend to correct the erroneous characters to semantically proper or commonly used ones, but these aren't the ground-truth corrections. To address this issue, we propose an Error-driven COntrastive Probability Optimization (ECOPO) framework for CSC task. ECOPO refines the knowledge representations of PLMs, and guides the model to avoid predicting these common characters through an error-driven way. Particularly, ECOPO is model-agnostic and it can be combined with existing CSC methods to achieve better performance. Extensive experiments and detailed analyses on SIGHAN datasets demonstrate that ECOPO is simple yet effective.
A non-hierarchical attention network with modality dropout for textual response generation in multimodal dialogue systems
Oct 20, 2021
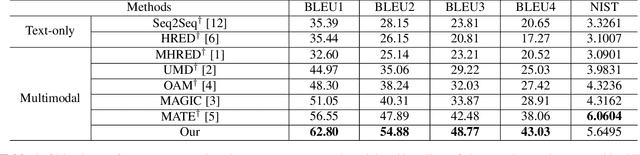
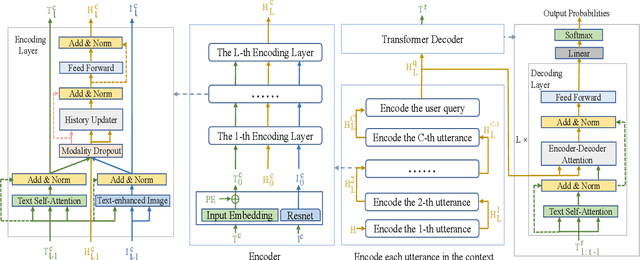

Existing text- and image-based multimodal dialogue systems use the traditional Hierarchical Recurrent Encoder-Decoder (HRED) framework, which has an utterance-level encoder to model utterance representation and a context-level encoder to model context representation. Although pioneer efforts have shown promising performances, they still suffer from the following challenges: (1) the interaction between textual features and visual features is not fine-grained enough. (2) the context representation can not provide a complete representation for the context. To address the issues mentioned above, we propose a non-hierarchical attention network with modality dropout, which abandons the HRED framework and utilizes attention modules to encode each utterance and model the context representation. To evaluate our proposed model, we conduct comprehensive experiments on a public multimodal dialogue dataset. Automatic and human evaluation demonstrate that our proposed model outperforms the existing methods and achieves state-of-the-art performance.