 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Down Video LLM Benchmarks: Knowledge, Spatial Perception, or True Temporal Understanding?
May 20, 2025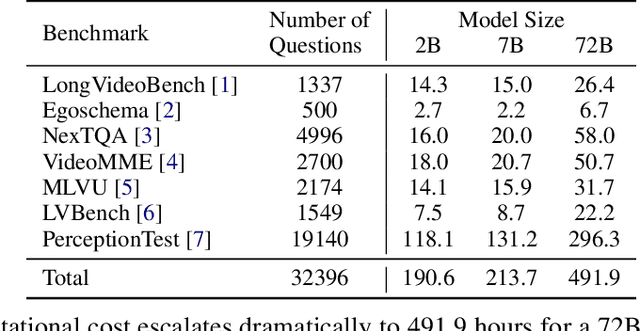

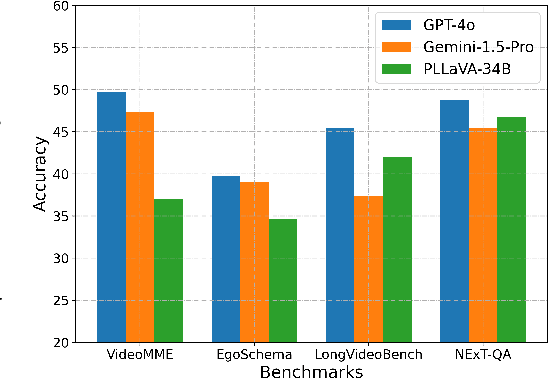
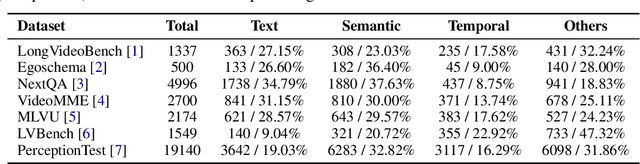
Existing video understanding benchmarks often conflate knowledge-based and purely image-based questions, rather than clearly isolating a model's temporal reasoning ability, which is the key aspect that distinguishes video understanding from other modalities. We identify two major limitations that obscure whether higher scores truly indicate stronger understanding of the dynamic content in videos: (1) strong language priors, where models can answer questions without watching the video; and (2) shuffling invariance, where models maintain similar performance on certain questions even when video frames are temporally shuffled. To alleviate these issues, we propose VBenchComp, an automated pipeline that categorizes questions into different domains: LLM-Answerable, Semantic, and Temporal. Specifically, LLM-Answerable questions can be answered without viewing the video; Semantic questions remain answerable even when the video frames are shuffled; and Temporal questions require understanding the correct temporal order of frames. The rest of the questions are labeled as Others. This can enable fine-grained evaluation of different capabilities of a video LLM. Our analysis reveals nuanced model weaknesses that are hidden by traditional overall scores, and we offer insights and recommendations for designing future benchmarks that more accurately assess video LLMs.
DialogUSR: Complex Dialogue Utterance Splitting and Reformulation for Multiple Intent Detection
Oct 20, 2022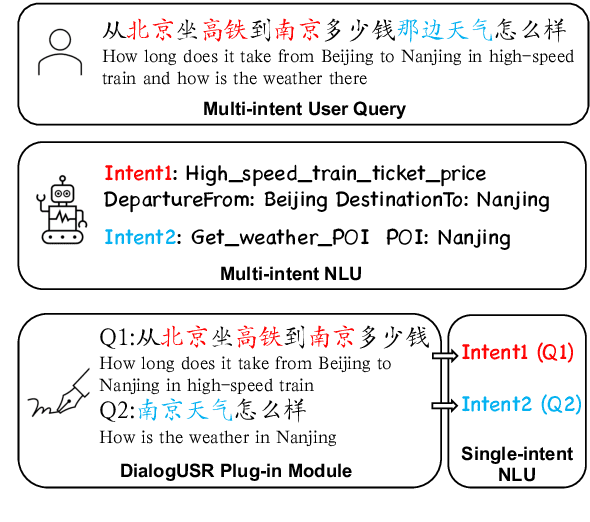
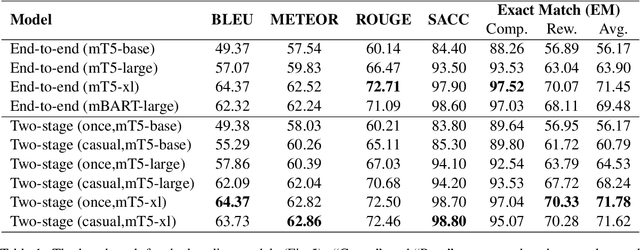

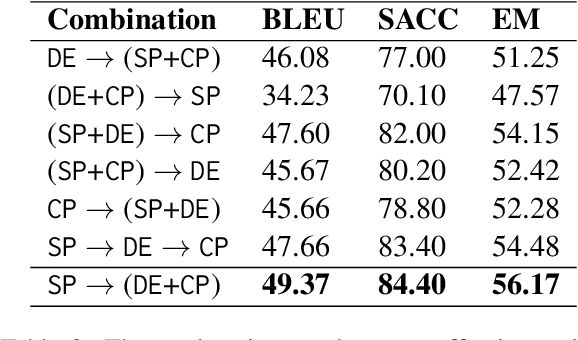
While interacting with chatbots, users may elicit multiple intents in a single dialogue utterance. Instead of training a dedicated multi-intent detection model, we propose DialogUSR, a dialogue utterance splitting and reformulation task that first splits multi-intent user query into several single-intent sub-queries and then recovers all the coreferred and omitted information in the sub-queries. DialogUSR can serve as a plug-in and domain-agnostic module that empowers the multi-intent detection for the deployed chatbots with minimal efforts. We collect a high-quality naturally occurring dataset that covers 23 domains with a multi-step crowd-souring procedure. To benchmark the proposed dataset, we propose multiple action-based generative models that involve end-to-end and two-stage training, and conduct in-depth analyses on the pros and cons of the proposed baselines.
The Past Mistake is the Future Wisdom: Error-driven Contrastive Probability Optimization for Chinese Spell Checking
Mar 02, 2022
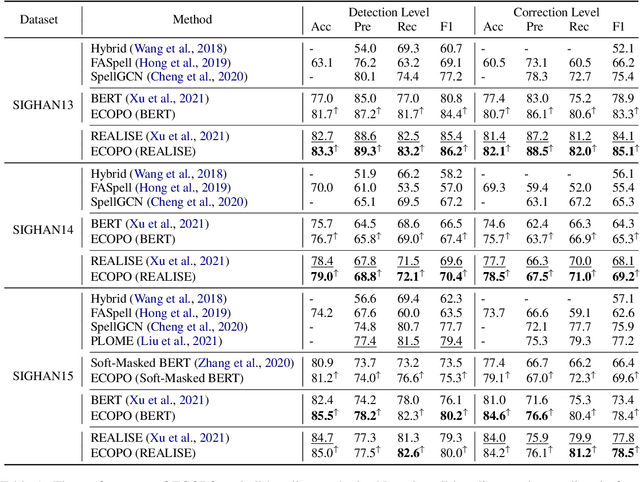
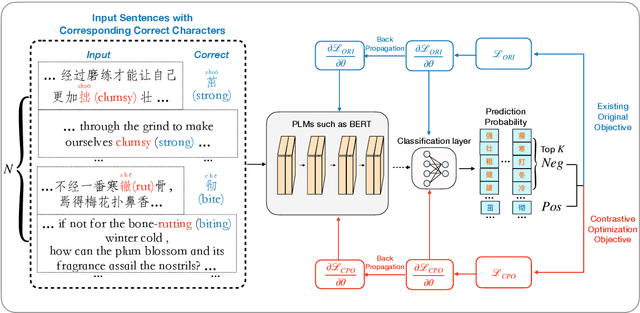
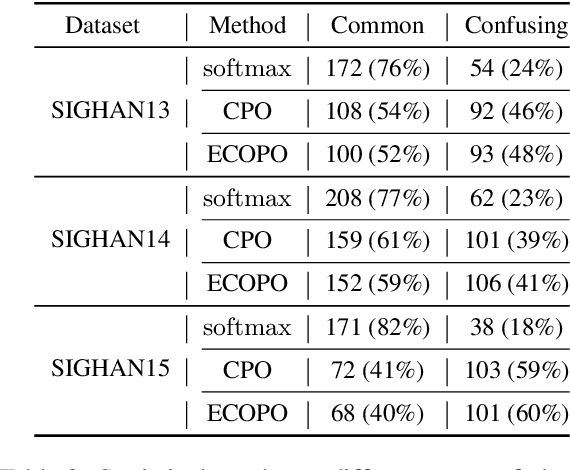
Chinese Spell Checking (CSC) aims to detect and correct Chinese spelling errors, which are mainly caused by the phonological or visual similarity. Recently, pre-trained language models (PLMs) promote the progress of CSC task. However, there exists a gap between the learned knowledge of PLMs and the goal of CSC task. PLMs focus on the semantics in text and tend to correct the erroneous characters to semantically proper or commonly used ones, but these aren't the ground-truth corrections. To address this issue, we propose an Error-driven COntrastive Probability Optimization (ECOPO) framework for CSC task. ECOPO refines the knowledge representations of PLMs, and guides the model to avoid predicting these common characters through an error-driven way. Particularly, ECOPO is model-agnostic and it can be combined with existing CSC methods to achieve better performance. Extensive experiments and detailed analyses on SIGHAN datasets demonstrate that ECOPO is simple yet effective.
Read, Listen, and See: Leveraging Multimodal Information Helps Chinese Spell Checking
May 26, 2021
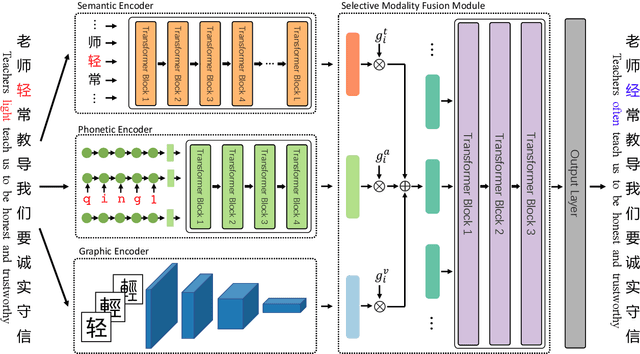

Chinese Spell Checking (CSC) aims to detect and correct erroneous characters for user-generated text in the Chinese language. Most of the Chinese spelling errors are misused semantically, phonetically or graphically similar characters. Previous attempts noticed this phenomenon and try to use the similarity for this task. However, these methods use either heuristics or handcrafted confusion sets to predict the correct character. In this paper, we propose a Chinese spell checker called ReaLiSe, by directly leveraging the multimodal information of the Chinese characters. The ReaLiSe model tackles the CSC task by (1) capturing the semantic, phonetic and graphic information of the input characters, and (2) selectively mixing the information in these modalities to predict the correct output. Experiments on the SIGHAN benchmarks show that the proposed model outperforms strong baselines by a large margin.
Match$^2$: A Matching over Matching Model for Similar Question Identification
Jun 21, 2020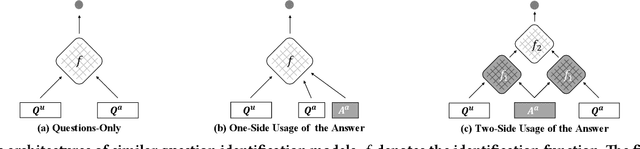


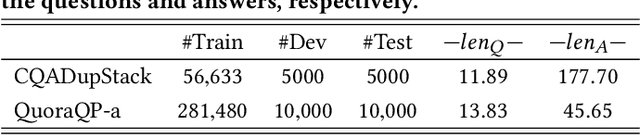
Community Question Answering (CQA) has become a primary means for people to acquire knowledge, where people are free to ask questions or submit answers. To enhance the efficiency of the service, similar question identification becomes a core task in CQA which aims to find a similar question from the archived repository whenever a new question is asked. However, it has long been a challenge to properly measure the similarity between two questions due to the inherent variation of natural language, i.e., there could be different ways to ask a same question or different questions sharing similar expressions. To alleviate this problem, it is natural to involve the existing answers for the enrichment of the archived questions. Traditional methods typically take a one-side usage, which leverages the answer as some expanded representation of the corresponding question. Unfortunately, this may introduce unexpected noises into the similarity computation since answers are often long and diverse, leading to inferior performance. In this work, we propose a two-side usage, which leverages the answer as a bridge of the two questions. The key idea is based on our observation that similar questions could be addressed by similar parts of the answer while different questions may not. In other words, we can compare the matching patterns of the two questions over the same answer to measure their similarity. In this way, we propose a novel matching over matching model, namely Match$^2$, which compares the matching patterns between two question-answer pairs for similar question identification. Empirical experiments on two benchmark datasets demonstrate that our model can significantly outperform previous state-of-the-art methods on the similar question identification task.