 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Users Go There: World Knowledge-Augmented Generative Next POI Recommendation
May 12, 2026Generative point-of-interest (POI) recommendation models based on large language models (LLMs) have shown promising results by formulating next POI prediction as a sequence generation task. However, the knowledge encoded in these models remains fixed after training, making them unable to perceive evolving real-world conditions that shape user mobility decisions, such as local events and cultural trends. To bridge this gap, we propose AWARE (Agent-based World knowledge Augmented REcommendation), which employs an LLM agent to generate location- and time-aware contextual narratives that capture regional cultural characteristics, seasonal trends, and ongoing events relevant to each user. Rather than introducing generic or noisy information, AWARE further anchors these narratives in each user's behavioral context, grounding external world knowledge in personalized spatial-temporal patterns. Extensive experiments on three real-world datasets demonstrate that AWARE consistently outperforms competitive baselines, achieving up to 12.4% relative improvement.
Reasoning Over Space: Enabling Geographic Reasoning for LLM-Based Generative Next POI Recommendation
Jan 08, 2026Generative recommendation with large language models (LLMs) reframes prediction as sequence generation, yet existing LLM-based recommenders remain limited in leveraging geographic signals that are crucial in mobility and local-services scenarios. Here, we present Reasoning Over Space (ROS), a framework that utilizes geography as a vital decision variable within the reasoning process. ROS introduces a Hierarchical Spatial Semantic ID (SID) that discretizes coarse-to-fine locality and POI semantics into compositional tokens, and endows LLM with a three-stage Mobility Chain-of-Thought (CoT) paradigm that models user personality, constructs an intent-aligned candidate space, and performs locality informed pruning. We further align the model with real world geography via spatial-guided Reinforcement Learning (RL). Experiments on three widely used location-based social network (LBSN) datasets show that ROS achieves over 10% relative gains in hit rate over strongest LLM-based baselines and improves cross-city transfer, despite using a smaller backbone model.
MMWOZ: Building Multimodal Agent for Task-oriented Dialogue
Nov 16, 2025Task-oriented dialogue systems have garnered significant attention due to their conversational ability to accomplish goals, such as booking airline tickets for users. Traditionally, task-oriented dialogue systems are conceptualized as intelligent agents that interact with users using natural language and have access to customized back-end APIs. However, in real-world scenarios, the widespread presence of front-end Graphical User Interfaces (GUIs) and the absence of customized back-end APIs create a significant gap for traditional task-oriented dialogue systems in practical applications. In this paper, to bridge the gap, we collect MMWOZ, a new multimodal dialogue dataset that is extended from MultiWOZ 2.3 dataset. Specifically, we begin by developing a web-style GUI to serve as the front-end. Next, we devise an automated script to convert the dialogue states and system actions from the original dataset into operation instructions for the GUI. Lastly, we collect snapshots of the web pages along with their corresponding operation instructions. In addition, we propose a novel multimodal model called MATE (Multimodal Agent for Task-oriEnted dialogue) as the baseline model for the MMWOZ dataset. Furthermore, we conduct comprehensive experimental analysis using MATE to investigate the construction of a practical multimodal agent for task-oriented dialogue.
A Distributed Collaborative Retrieval Framework Excelling in All Queries and Corpora based on Zero-shot Rank-Oriented Automatic Evaluation
Dec 16, 2024



Numerous retrieval models, including sparse, dense and llm-based methods, have demonstrated remarkable performance in predicting the relevance between queries and corpora. However, the preliminary effectiveness analysis experiments indicate that these models fail to achieve satisfactory performance on the majority of queries and corpora, revealing their effectiveness restricted to specific scenarios. Thus, to tackle this problem, we propose a novel Distributed Collaborative Retrieval Framework (DCRF), outperforming each single model across all queries and corpora. Specifically, the framework integrates various retrieval models into a unified system and dynamically selects the optimal results for each user's query. It can easily aggregate any retrieval model and expand to any application scenarios, illustrating its flexibility and scalability.Moreover, to reduce maintenance and training costs, we design four effective prompting strategies with large language models (LLMs) to evaluate the quality of ranks without reliance of labeled data. Extensive experiments demonstrate that proposed framework, combined with 8 efficient retrieval models, can achieve performance comparable to effective listwise methods like RankGPT and ListT5, while offering superior efficiency. Besides, DCRF surpasses all selected retrieval models on the most datasets, indicating the effectiveness of our prompting strategies on rank-oriented automatic evaluation.
Read, Listen, and See: Leveraging Multimodal Information Helps Chinese Spell Checking
May 26, 2021
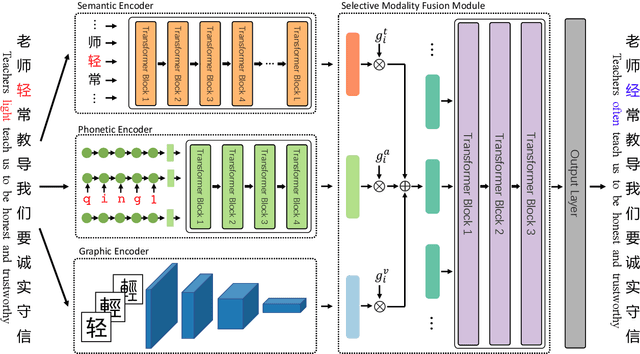
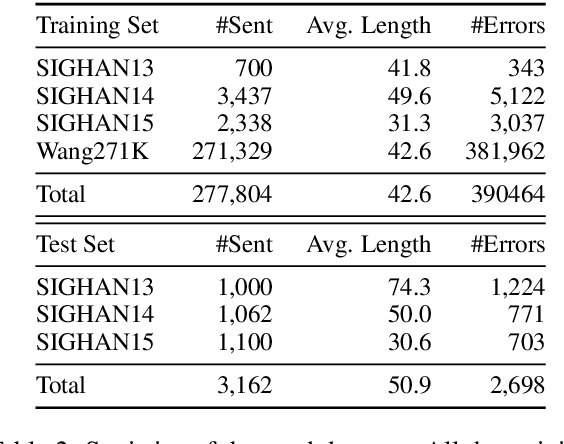

Chinese Spell Checking (CSC) aims to detect and correct erroneous characters for user-generated text in the Chinese language. Most of the Chinese spelling errors are misused semantically, phonetically or graphically similar characters. Previous attempts noticed this phenomenon and try to use the similarity for this task. However, these methods use either heuristics or handcrafted confusion sets to predict the correct character. In this paper, we propose a Chinese spell checker called ReaLiSe, by directly leveraging the multimodal information of the Chinese characters. The ReaLiSe model tackles the CSC task by (1) capturing the semantic, phonetic and graphic information of the input characters, and (2) selectively mixing the information in these modalities to predict the correct output. Experiments on the SIGHAN benchmarks show that the proposed model outperforms strong baselines by a large margin.
Generating Informative Dialogue Responses with Keywords-Guided Networks
Jul 03, 2020
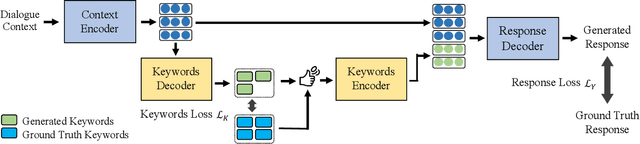
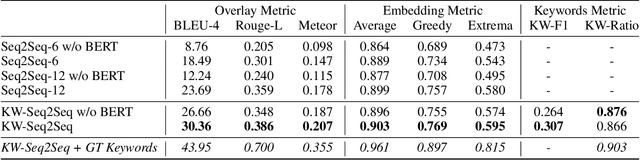
Recently, open-domain dialogue systems have attracted growing attention. Most of them use the sequence-to-sequence (Seq2Seq) architecture to generate responses. However, traditional Seq2Seq-based open-domain dialogue models tend to generate generic and safe responses, which are less informative, unlike human responses. In this paper, we propose a simple but effective keywords-guided Sequence-to-Sequence model (KW-Seq2Seq) which uses keywords information as guidance to generate open-domain dialogue responses. Specifically, KW-Seq2Seq first uses a keywords decoder to predict some topic keywords, and then generates the final response under the guidance of them. Extensive experiments demonstrate that the KW-Seq2Seq model produces more informative, coherent and fluent responses, yielding substantive gain in both automatic and human evaluation metrics.
Complicated Table Structure Recognition
Aug 28, 2019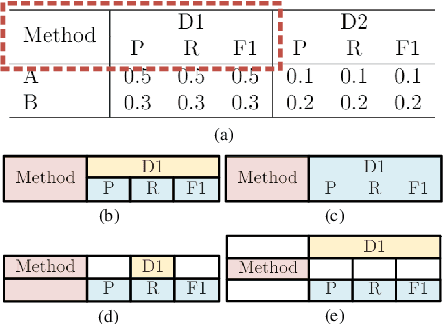
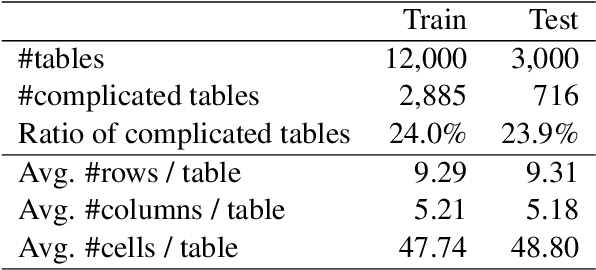
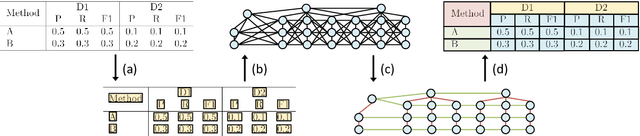
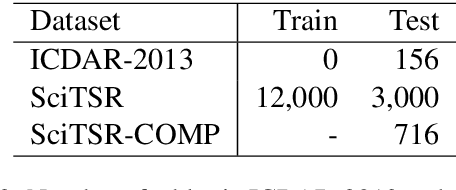
The task of table structure recognition aims to recognize the internal structure of a table, which is a key step to make machines understand tables. Currently, there are lots of studies on this task for different file formats such as ASCII text and HTML. It also attracts lots of attention to recognize the table structures in PDF files. However, it is hard for the existing methods to accurately recognize the structure of complicated tables in PDF files. The complicated tables contain spanning cells which occupy at least two columns or rows. To address the issue, we propose a novel graph neural network for recognizing the table structure in PDF files, named GraphTSR. Specifically, it takes table cells as input, and then recognizes the table structures by predicting relations among cells. Moreover, to evaluate the task better, we construct a large-scale table structure recognition dataset from scientific papers, named SciTSR, which contains 15,000 tables from PDF files and their corresponding structure labels. Extensive experiments demonstrate that our proposed model is highly effective for complicated tables and outperforms state-of-the-art baselines over a benchmark dataset and our new constructed dataset.