 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Distributed Collaborative Retrieval Framework Excelling in All Queries and Corpora based on Zero-shot Rank-Oriented Automatic Evaluation
Dec 16, 2024



Numerous retrieval models, including sparse, dense and llm-based methods, have demonstrated remarkable performance in predicting the relevance between queries and corpora. However, the preliminary effectiveness analysis experiments indicate that these models fail to achieve satisfactory performance on the majority of queries and corpora, revealing their effectiveness restricted to specific scenarios. Thus, to tackle this problem, we propose a novel Distributed Collaborative Retrieval Framework (DCRF), outperforming each single model across all queries and corpora. Specifically, the framework integrates various retrieval models into a unified system and dynamically selects the optimal results for each user's query. It can easily aggregate any retrieval model and expand to any application scenarios, illustrating its flexibility and scalability.Moreover, to reduce maintenance and training costs, we design four effective prompting strategies with large language models (LLMs) to evaluate the quality of ranks without reliance of labeled data. Extensive experiments demonstrate that proposed framework, combined with 8 efficient retrieval models, can achieve performance comparable to effective listwise methods like RankGPT and ListT5, while offering superior efficiency. Besides, DCRF surpasses all selected retrieval models on the most datasets, indicating the effectiveness of our prompting strategies on rank-oriented automatic evaluation.
Distribution-Consistency-Guided Multi-modal Hashing
Dec 15, 2024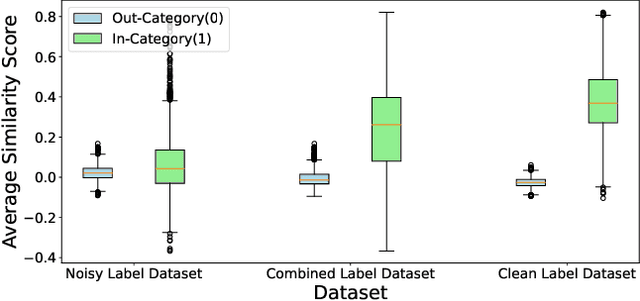
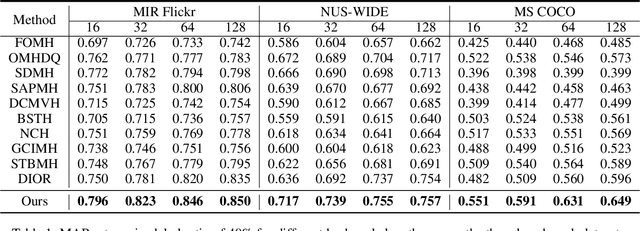
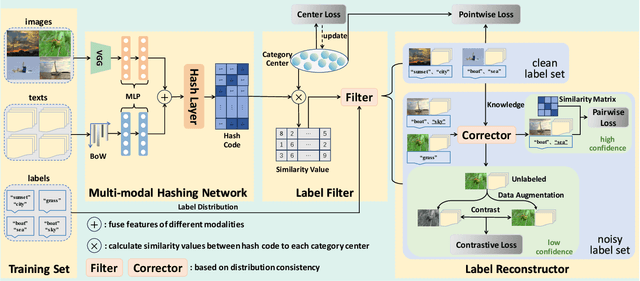
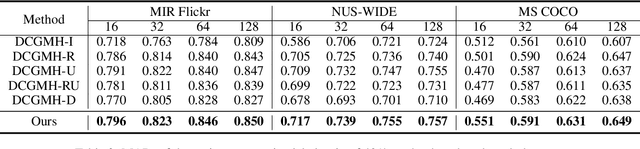
Multi-modal hashing methods have gained popularity due to their fast speed and low storage requirements. Among them, the supervised methods demonstrate better performance by utilizing labels as supervisory signals compared with unsupervised methods. Currently, for almost all supervised multi-modal hashing methods, there is a hidden assumption that training sets have no noisy labels. However, labels are often annotated incorrectly due to manual labeling in real-world scenarios, which will greatly harm the retrieval performance. To address this issue, we first discover a significant distribution consistency pattern through experiments, i.e., the 1-0 distribution of the presence or absence of each category in the label is consistent with the high-low distribution of similarity scores of the hash codes relative to category centers. Then, inspired by this pattern, we propose a novel Distribution-Consistency-Guided Multi-modal Hashing (DCGMH), which aims to filter and reconstruct noisy labels to enhance retrieval performance. Specifically, the proposed method first randomly initializes several category centers, which are used to compute the high-low distribution of similarity scores; Noisy and clean labels are then separately filtered out via the discovered distribution consistency pattern to mitigate the impact of noisy labels; Subsequently, a correction strategy, which is indirectly designed via the distribution consistency pattern, is applied to the filtered noisy labels, correcting high-confidence ones while treating low-confidence ones as unlabeled for unsupervised learning, thereby further enhancing the model's performance. Extensive experiments on three widely used datasets demonstrate the superiority of the proposed method compared to state-of-the-art baselines in multi-modal retrieval tasks. The code is available at https://github.com/LiuJinyu1229/DCGMH.
Hammer PDF: An Intelligent PDF Reader for Scientific Papers
Apr 06, 2022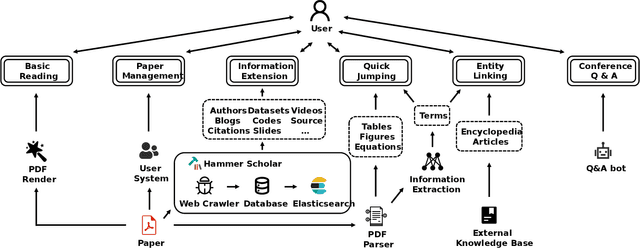
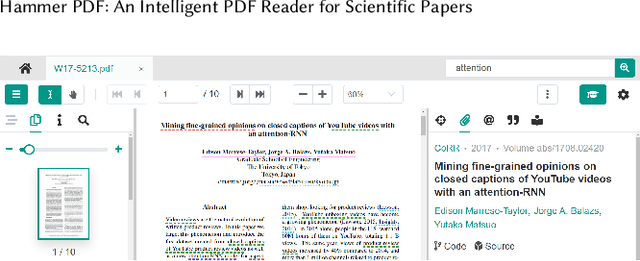


Reading scientific papers has been an essential way for researchers to acquire academic knowledge, and most papers are in PDF format. However, existing PDF Readers only support reading, editing, annotating and other basic functions, and lack of multi-granularity analysis for academic papers. Specifically, taking a paper as a whole, these PDF Readers cannot access extended information of the paper, such as related videos, blogs, codes, etc.; meanwhile, for the content of a paper, these PDF Readers also cannot extract and display academic details of the paper, such as terms, authors, citations, etc. In this paper, we introduce Hammer PDF, a novel intelligent PDF Reader for scientific papers. Beyond basic reading functions, Hammer PDF comes with four innovative features: (1) locate, mark and interact with spans (e.g., terms) obtained by information extraction; (2) citation, reference, code, video, blog, and other extended information are displayed with a paper; (3) built-in Hammer Scholar, an academic search engine that uses academic information collected from major academic databases; (4) built-in Q\&A bot to support asking for interested conference information. Our product helps researchers, especially those who study computer science, to improve the efficiency and experience of reading scientific papers. We release Hammer PDF, available for download at https://pdf.hammerscholar.net/face.