 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpontaneous Speech Variables for Evaluating LLMs Cognitive Plausibility
May 22, 2025


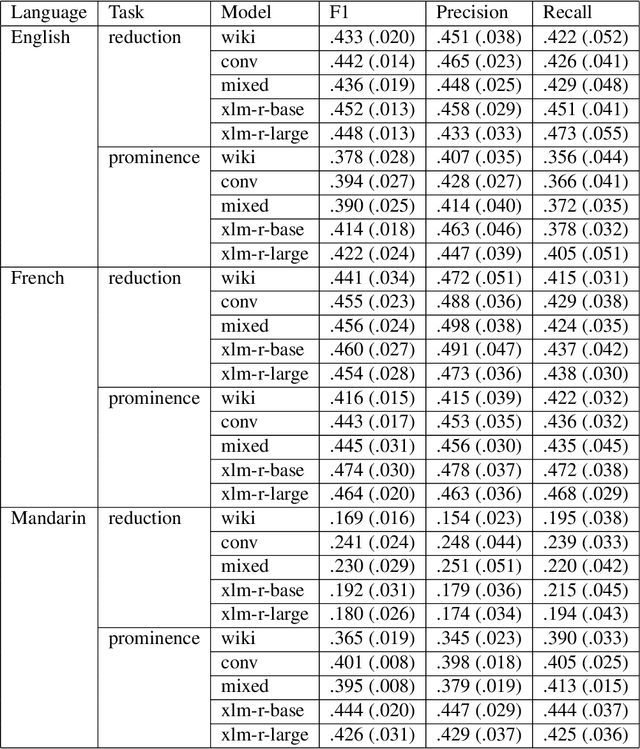
The achievements of Large Language Models in Natural Language Processing, especially for high-resource languages, call for a better understanding of their characteristics from a cognitive perspective. Researchers have attempted to evaluate artificial models by testing their ability to predict behavioral (e.g., eye-tracking fixations) and physiological (e.g., brain responses) variables during language processing (e.g., reading/listening). In this paper, we propose using spontaneous speech corpora to derive production variables (speech reductions, prosodic prominences) and applying them in a similar fashion. More precisely, we extract. We then test models trained with a standard procedure on different pretraining datasets (written, spoken, and mixed genres) for their ability to predict these two variables. Our results show that, after some fine-tuning, the models can predict these production variables well above baselines. We also observe that spoken genre training data provides more accurate predictions than written genres. These results contribute to the broader effort of using high-quality speech corpora as benchmarks for LLMs.
Hammer PDF: An Intelligent PDF Reader for Scientific Papers
Apr 06, 2022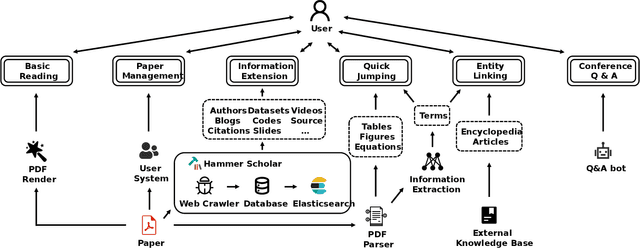


Reading scientific papers has been an essential way for researchers to acquire academic knowledge, and most papers are in PDF format. However, existing PDF Readers only support reading, editing, annotating and other basic functions, and lack of multi-granularity analysis for academic papers. Specifically, taking a paper as a whole, these PDF Readers cannot access extended information of the paper, such as related videos, blogs, codes, etc.; meanwhile, for the content of a paper, these PDF Readers also cannot extract and display academic details of the paper, such as terms, authors, citations, etc. In this paper, we introduce Hammer PDF, a novel intelligent PDF Reader for scientific papers. Beyond basic reading functions, Hammer PDF comes with four innovative features: (1) locate, mark and interact with spans (e.g., terms) obtained by information extraction; (2) citation, reference, code, video, blog, and other extended information are displayed with a paper; (3) built-in Hammer Scholar, an academic search engine that uses academic information collected from major academic databases; (4) built-in Q\&A bot to support asking for interested conference information. Our product helps researchers, especially those who study computer science, to improve the efficiency and experience of reading scientific papers. We release Hammer PDF, available for download at https://pdf.hammerscholar.net/face.
BLiMP: A Benchmark of Linguistic Minimal Pairs for English
Dec 02, 2019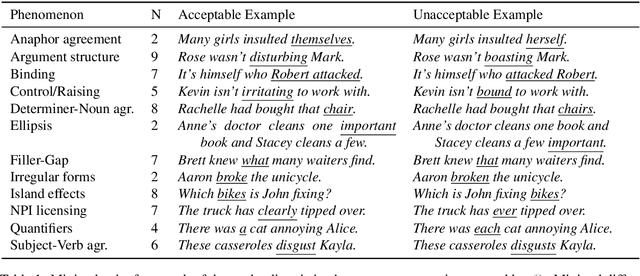
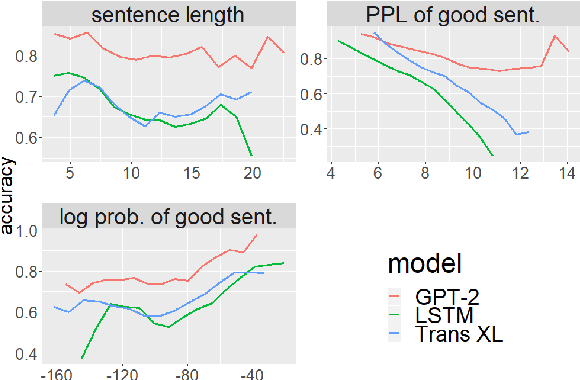

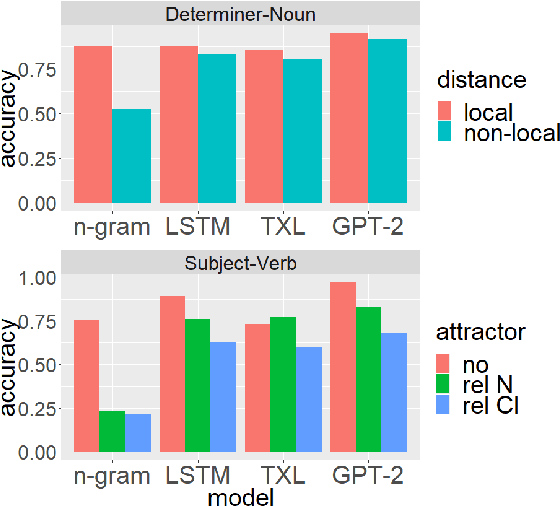
We introduce The Benchmark of Linguistic Minimal Pairs (shortened to BLiMP), a challenge set for evaluating what language models (LMs) know about major grammatical phenomena in English. BLiMP consists of 67 sub-datasets, each containing 1000 minimal pairs isolating specific contrasts in syntax, morphology, or semantics. The data is automatically generated according to expert-crafted grammars, and aggregate human agreement with the labels is 96.4%. We use it to evaluate n-gram, LSTM, and Transformer (GPT-2 and Transformer-XL) LMs. We find that state-of-the-art models identify morphological contrasts reliably, but they struggle with semantic restrictions on the distribution of quantifiers and negative polarity items and subtle syntactic phenomena such as extraction islands.
Investigating BERT's Knowledge of Language: Five Analysis Methods with NPIs
Sep 19, 2019
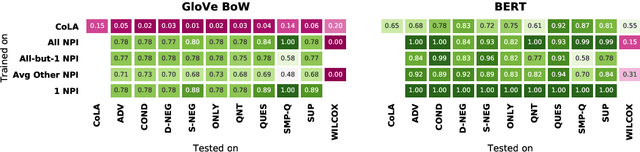

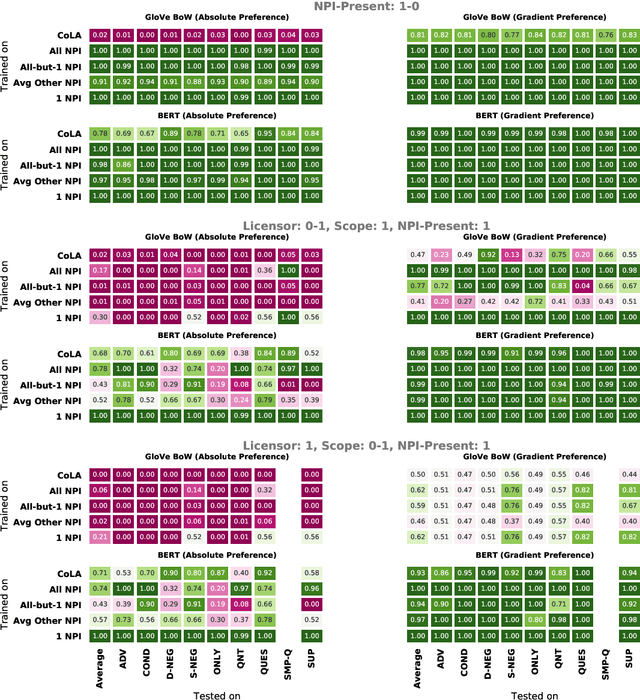
Though state-of-the-art sentence representation models can perform tasks requiring significant knowledge of grammar, it is an open question how best to evaluate their grammatical knowledge. We explore five experimental methods inspired by prior work evaluating pretrained sentence representation models. We use a single linguistic phenomenon, negative polarity item (NPI) licensing in English, as a case study for our experiments. NPIs like "any" are grammatical only if they appear in a licensing environment like negation ("Sue doesn't have any cats" vs. "Sue has any cats"). This phenomenon is challenging because of the variety of NPI licensing environments that exist. We introduce an artificially generated dataset that manipulates key features of NPI licensing for the experiments. We find that BERT has significant knowledge of these features, but its success varies widely across different experimental methods. We conclude that a variety of methods is necessary to reveal all relevant aspects of a model's grammatical knowledge in a given domain.
Neural Networks and Quantifier Conservativity: Does Data Distribution Affect Learnability?
Sep 15, 2018
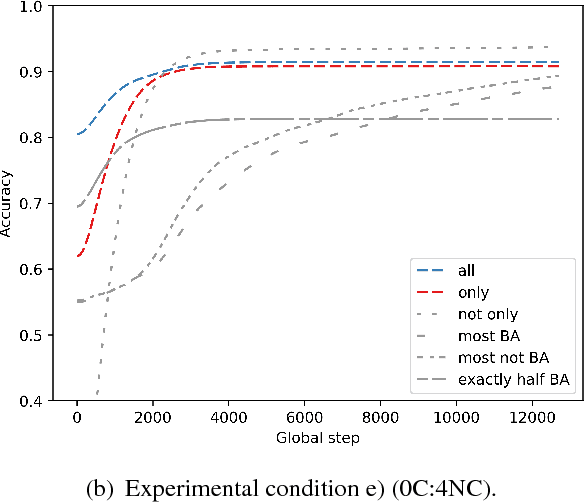
All known natural language determiners are conservative. Psycholinguistic experiments indicate that children exhibit a corresponding learnability bias when faced with the task of learning new determiners. However, recent work indicates that this bias towards conservativity is not observed during the training stage of artificial neural networks. In this work, we investigate whether the learnability bias exhibited by children is in part due to the distribution of quantifiers in natural language. We share results of five experiments, contrasted by the distribution of conservative vs. non-conservative determiners in the training data. We demonstrate that the aquisitional issues with non-conservative quantifiers can not be explained by the distribution of natural language data, which favors conservative quantifiers. This finding indicates that the bias in language acquisition data might be innate or representational.