 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Really Need 10+ Thoughts for "Find the Time 1000 Days Later"? Towards Structural Understanding of LLM Overthinking
Oct 09, 2025Models employing long chain-of-thought (CoT) reasoning have shown superior performance on complex reasoning tasks. Yet, this capability introduces a critical and often overlooked inefficiency -- overthinking -- models often engage in unnecessarily extensive reasoning even for simple queries, incurring significant computations without accuracy improvements. While prior work has explored solutions to mitigate overthinking, a fundamental gap remains in our understanding of its underlying causes. Most existing analyses are limited to superficial, profiling-based observations, failing to delve into LLMs' inner workings. This study introduces a systematic, fine-grained analyzer of LLMs' thought process to bridge the gap, TRACE. We first benchmark the overthinking issue, confirming that long-thinking models are five to twenty times slower on simple tasks with no substantial gains. We then use TRACE to first decompose the thought process into minimally complete sub-thoughts. Next, by inferring discourse relationships among sub-thoughts, we construct granular thought progression graphs and subsequently identify common thinking patterns for topically similar queries. Our analysis reveals two major patterns for open-weight thinking models -- Explorer and Late Landing. This finding provides evidence that over-verification and over-exploration are the primary drivers of overthinking in LLMs. Grounded in thought structures, we propose a utility-based definition of overthinking, which moves beyond length-based metrics. This revised definition offers a more insightful understanding of LLMs' thought progression, as well as practical guidelines for principled overthinking management.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Self-Training for Unsupervised Parsing with PRPN
May 27, 2020

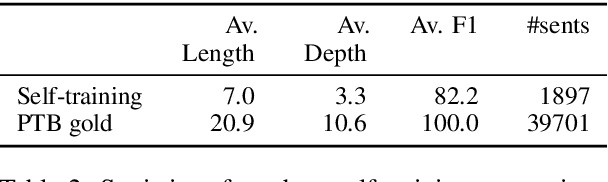

Neural unsupervised parsing (UP) models learn to parse without access to syntactic annotations, while being optimized for another task like language modeling. In this work, we propose self-training for neural UP models: we leverage aggregated annotations predicted by copies of our model as supervision for future copies. To be able to use our model's predictions during training, we extend a recent neural UP architecture, the PRPN (Shen et al., 2018a) such that it can be trained in a semi-supervised fashion. We then add examples with parses predicted by our model to our unlabeled UP training data. Our self-trained model outperforms the PRPN by 8.1% F1 and the previous state of the art by 1.6% F1. In addition, we show that our architecture can also be helpful for semi-supervised parsing in ultra-low-resource settings.
BLiMP: A Benchmark of Linguistic Minimal Pairs for English
Dec 02, 2019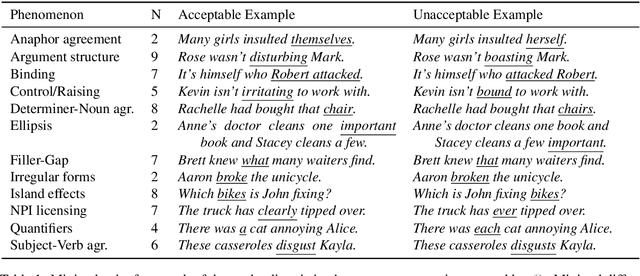
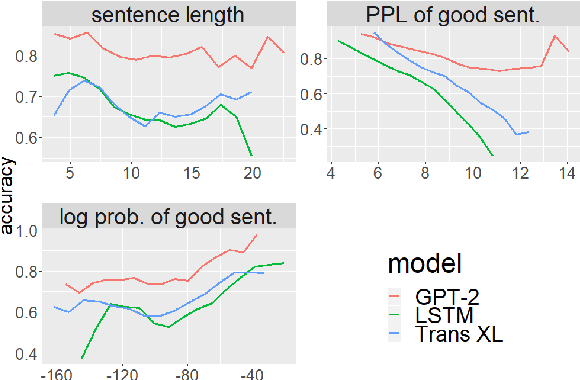

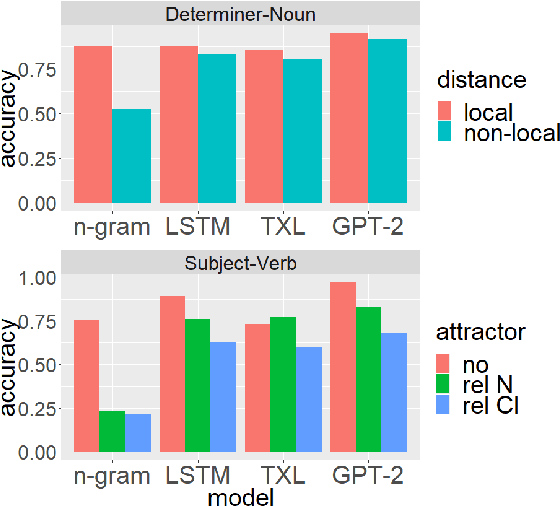
We introduce The Benchmark of Linguistic Minimal Pairs (shortened to BLiMP), a challenge set for evaluating what language models (LMs) know about major grammatical phenomena in English. BLiMP consists of 67 sub-datasets, each containing 1000 minimal pairs isolating specific contrasts in syntax, morphology, or semantics. The data is automatically generated according to expert-crafted grammars, and aggregate human agreement with the labels is 96.4%. We use it to evaluate n-gram, LSTM, and Transformer (GPT-2 and Transformer-XL) LMs. We find that state-of-the-art models identify morphological contrasts reliably, but they struggle with semantic restrictions on the distribution of quantifiers and negative polarity items and subtle syntactic phenomena such as extraction islands.
Investigating BERT's Knowledge of Language: Five Analysis Methods with NPIs
Sep 19, 2019
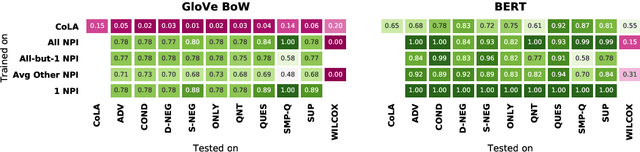

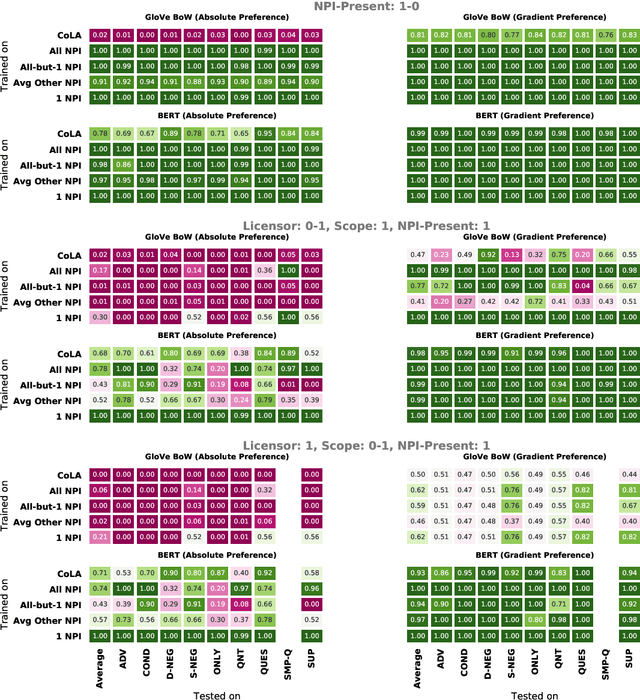
Though state-of-the-art sentence representation models can perform tasks requiring significant knowledge of grammar, it is an open question how best to evaluate their grammatical knowledge. We explore five experimental methods inspired by prior work evaluating pretrained sentence representation models. We use a single linguistic phenomenon, negative polarity item (NPI) licensing in English, as a case study for our experiments. NPIs like "any" are grammatical only if they appear in a licensing environment like negation ("Sue doesn't have any cats" vs. "Sue has any cats"). This phenomenon is challenging because of the variety of NPI licensing environments that exist. We introduce an artificially generated dataset that manipulates key features of NPI licensing for the experiments. We find that BERT has significant knowledge of these features, but its success varies widely across different experimental methods. We conclude that a variety of methods is necessary to reveal all relevant aspects of a model's grammatical knowledge in a given domain.