 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
ArtVLM: Attribute Recognition Through Vision-Based Prefix Language Modeling
Aug 07, 2024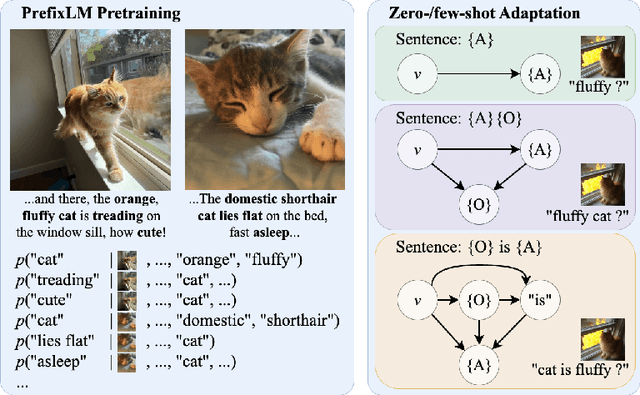

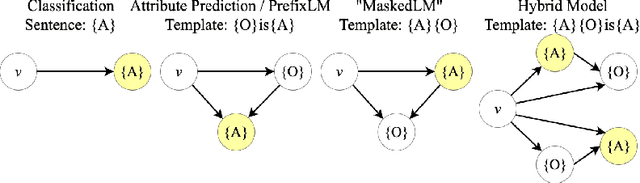

Recognizing and disentangling visual attributes from objects is a foundation to many computer vision applications. While large vision language representations like CLIP had largely resolved the task of zero-shot object recognition, zero-shot visual attribute recognition remains a challenge because CLIP's contrastively-learned vision-language representation cannot effectively capture object-attribute dependencies. In this paper, we target this weakness and propose a sentence generation-based retrieval formulation for attribute recognition that is novel in 1) explicitly modeling a to-be-measured and retrieved object-attribute relation as a conditional probability graph, which converts the recognition problem into a dependency-sensitive language-modeling problem, and 2) applying a large pretrained Vision-Language Model (VLM) on this reformulation and naturally distilling its knowledge of image-object-attribute relations to use towards attribute recognition. Specifically, for each attribute to be recognized on an image, we measure the visual-conditioned probability of generating a short sentence encoding the attribute's relation to objects on the image. Unlike contrastive retrieval, which measures likelihood by globally aligning elements of the sentence to the image, generative retrieval is sensitive to the order and dependency of objects and attributes in the sentence. We demonstrate through experiments that generative retrieval consistently outperforms contrastive retrieval on two visual reasoning datasets, Visual Attribute in the Wild (VAW), and our newly-proposed Visual Genome Attribute Ranking (VGARank).
Parrot: Pareto-optimal Multi-Reward Reinforcement Learning Framework for Text-to-Image Generation
Jan 11, 2024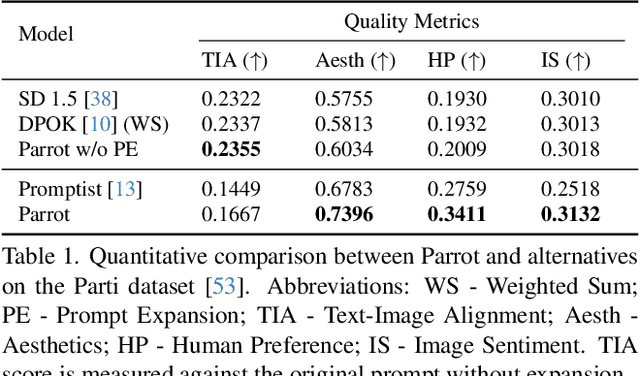
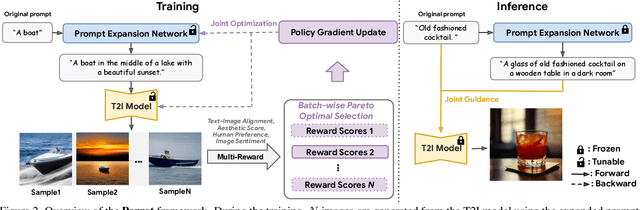


Recent works demonstrate that using reinforcement learning (RL) with quality rewards can enhance the quality of generated images in text-to-image (T2I) generation. However, a simple aggregation of multiple rewards may cause over-optimization in certain metrics and degradation in others, and it is challenging to manually find the optimal weights. An effective strategy to jointly optimize multiple rewards in RL for T2I generation is highly desirable. This paper introduces Parrot, a novel multi-reward RL framework for T2I generation. Through the use of the batch-wise Pareto optimal selection, Parrot automatically identifies the optimal trade-off among different rewards during the RL optimization of the T2I generation. Additionally, Parrot employs a joint optimization approach for the T2I model and the prompt expansion network, facilitating the generation of quality-aware text prompts, thus further enhancing the final image quality. To counteract the potential catastrophic forgetting of the original user prompt due to prompt expansion, we introduce original prompt centered guidance at inference time, ensuring that the generated image remains faithful to the user input. Extensive experiments and a user study demonstrate that Parrot outperforms several baseline methods across various quality criteria, including aesthetics, human preference, image sentiment, and text-image alignment.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Towards an Automatic AI Agent for Reaction Condition Recommendation in Chemical Synthesis
Nov 28, 2023



Artificial intelligence (AI) for reaction condition optimization has become an important topic in the pharmaceutical industry, given that a data-driven AI model can assist drug discovery and accelerate reaction design. However, existing AI models lack the chemical insights and real-time knowledge acquisition abilities of experienced human chemists. This paper proposes a Large Language Model (LLM) empowered AI agent to bridge this gap. We put forth a novel three-phase paradigm and applied advanced intelligence-enhancement methods like in-context learning and multi-LLM debate so that the AI agent can borrow human insight and update its knowledge by searching the latest chemical literature. Additionally, we introduce a novel Coarse-label Contrastive Learning (CCL) based chemical fingerprint that greatly enhances the agent's performance in optimizing the reaction condition. With the above efforts, the proposed AI agent can autonomously generate the optimal reaction condition recommendation without any human interaction. Further, the agent is highly professional in terms of chemical reactions. It demonstrates close-to-human performance and strong generalization capability in both dry-lab and wet-lab experiments. As the first attempt in the chemical AI agent, this work goes a step further in the field of "AI for chemistry" and opens up new possibilities for computer-aided synthesis planning.
IG Captioner: Information Gain Captioners are Strong Zero-shot Classifiers
Nov 27, 2023



Generative training has been demonstrated to be powerful for building visual-language models. However, on zero-shot discriminative benchmarks, there is still a performance gap between models trained with generative and discriminative objectives. In this paper, we aim to narrow this gap by improving the efficacy of generative training on classification tasks, without any finetuning processes or additional modules. Specifically, we focus on narrowing the gap between the generative captioner and the CLIP classifier. We begin by analysing the predictions made by the captioner and classifier and observe that the caption generation inherits the distribution bias from the language model trained with pure text modality, making it less grounded on the visual signal. To tackle this problem, we redesign the scoring objective for the captioner to alleviate the distributional bias and focus on measuring the gain of information brought by the visual inputs. We further design a generative training objective to match the evaluation objective. We name our model trained and evaluated from the novel procedures as Information Gain (IG) captioner. We pretrain the models on the public Laion-5B dataset and perform a series of discriminative evaluations. For the zero-shot classification on ImageNet, IG captioner achieves $> 18\%$ improvements over the standard captioner, achieving comparable performances with the CLIP classifier. IG captioner also demonstrated strong performance on zero-shot image-text retrieval tasks on MSCOCO and Flickr30K. We hope this paper inspires further research towards unifying generative and discriminative training procedures for visual-language models.
De-Diffusion Makes Text a Strong Cross-Modal Interface
Nov 01, 2023



We demonstrate text as a strong cross-modal interface. Rather than relying on deep embeddings to connect image and language as the interface representation, our approach represents an image as text, from which we enjoy the interpretability and flexibility inherent to natural language. We employ an autoencoder that uses a pre-trained text-to-image diffusion model for decoding. The encoder is trained to transform an input image into text, which is then fed into the fixed text-to-image diffusion decoder to reconstruct the original input -- a process we term De-Diffusion. Experiments validate both the precision and comprehensiveness of De-Diffusion text representing images, such that it can be readily ingested by off-the-shelf text-to-image tools and LLMs for diverse multi-modal tasks. For example, a single De-Diffusion model can generalize to provide transferable prompts for different text-to-image tools, and also achieves a new state of the art on open-ended vision-language tasks by simply prompting large language models with few-shot examples.
Module-wise Adaptive Distillation for Multimodality Foundation Models
Oct 06, 2023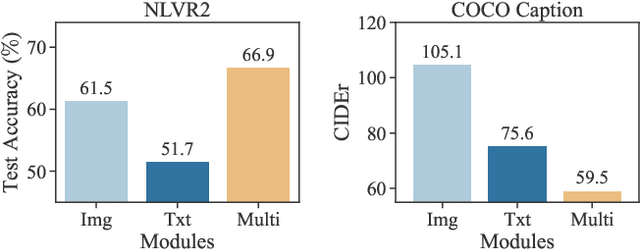
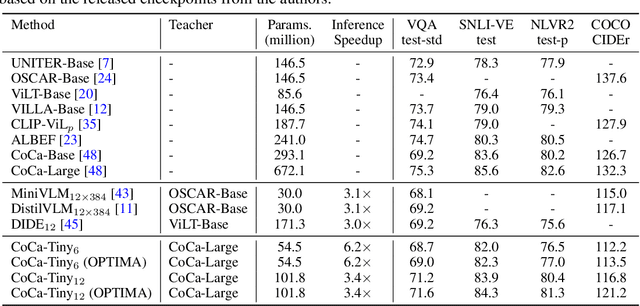
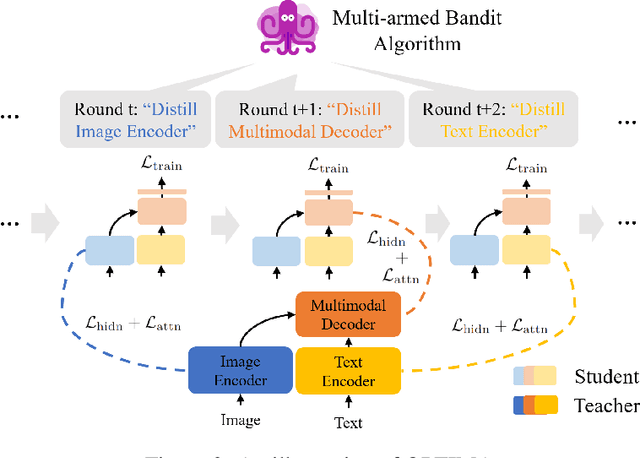
Pre-trained multimodal foundation models have demonstrated remarkable generalizability but pose challenges for deployment due to their large sizes. One effective approach to reducing their sizes is layerwise distillation, wherein small student models are trained to match the hidden representations of large teacher models at each layer. Motivated by our observation that certain architecture components, referred to as modules, contribute more significantly to the student's performance than others, we propose to track the contributions of individual modules by recording the loss decrement after distillation each module and choose the module with a greater contribution to distill more frequently. Such an approach can be naturally formulated as a multi-armed bandit (MAB) problem, where modules and loss decrements are considered as arms and rewards, respectively. We then develop a modified-Thompson sampling algorithm named OPTIMA to address the nonstationarity of module contributions resulting from model updating. Specifically, we leverage the observed contributions in recent history to estimate the changing contribution of each module and select modules based on these estimations to maximize the cumulative contribution. We evaluate the effectiveness of OPTIMA through distillation experiments on various multimodal understanding and image captioning tasks, using the CoCa-Large model (Yu et al., 2022) as the teacher model.
AudioPaLM: A Large Language Model That Can Speak and Listen
Jun 22, 2023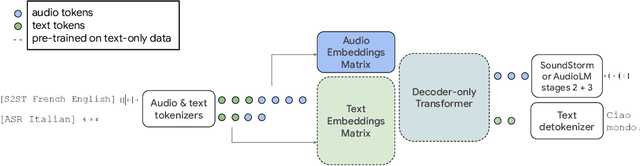



We introduce AudioPaLM, a large language model for speech understanding and generation. AudioPaLM fuses text-based and speech-based language models, PaLM-2 [Anil et al., 2023] and AudioLM [Borsos et al., 2022], into a unified multimodal architecture that can process and generate text and speech with applications including speech recognition and speech-to-speech translation. AudioPaLM inherits the capability to preserve paralinguistic information such as speaker identity and intonation from AudioLM and the linguistic knowledge present only in text large language models such as PaLM-2. We demonstrate that initializing AudioPaLM with the weights of a text-only large language model improves speech processing, successfully leveraging the larger quantity of text training data used in pretraining to assist with the speech tasks. The resulting model significantly outperforms existing systems for speech translation tasks and has the ability to perform zero-shot speech-to-text translation for many languages for which input/target language combinations were not seen in training. AudioPaLM also demonstrates features of audio language models, such as transferring a voice across languages based on a short spoken prompt. We release examples of our method at https://google-research.github.io/seanet/audiopalm/examples