 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPS-LSTM: Exploiting Multi-Periodicity and Diverse Spatial Dependencies for Flood Forecasting
Dec 07, 2024Accurate flood prediction is crucial for disaster prevention and mitigation. Hydrological data exhibit highly nonlinear temporal patterns and encompass complex spatial relationships between rainfall and flow. Existing flood prediction models struggle to capture these intricate temporal features and spatial dependencies. This paper presents an adaptive periodic and spatial self-attention method based on LSTM (APS-LSTM) to address these challenges. The APS-LSTM learns temporal features from a multi-periodicity perspective and captures diverse spatial dependencies from different period divisions. The APS-LSTM consists of three main stages, (i) Multi-Period Division, that utilizes Fast Fourier Transform (FFT) to divide various periodic patterns; (ii) Spatio-Temporal Information Extraction, that performs periodic and spatial self-attention focusing on intra- and inter-periodic temporal patterns and spatial dependencies; (iii) Adaptive Aggregation, that relies on amplitude strength to aggregate the computational results from each periodic division. The abundant experiments on two real-world datasets demonstrate the superiority of APS-LSTM. The code is available: https://github.com/oopcmd/APS-LSTM.
Towards an Automatic AI Agent for Reaction Condition Recommendation in Chemical Synthesis
Nov 28, 2023



Artificial intelligence (AI) for reaction condition optimization has become an important topic in the pharmaceutical industry, given that a data-driven AI model can assist drug discovery and accelerate reaction design. However, existing AI models lack the chemical insights and real-time knowledge acquisition abilities of experienced human chemists. This paper proposes a Large Language Model (LLM) empowered AI agent to bridge this gap. We put forth a novel three-phase paradigm and applied advanced intelligence-enhancement methods like in-context learning and multi-LLM debate so that the AI agent can borrow human insight and update its knowledge by searching the latest chemical literature. Additionally, we introduce a novel Coarse-label Contrastive Learning (CCL) based chemical fingerprint that greatly enhances the agent's performance in optimizing the reaction condition. With the above efforts, the proposed AI agent can autonomously generate the optimal reaction condition recommendation without any human interaction. Further, the agent is highly professional in terms of chemical reactions. It demonstrates close-to-human performance and strong generalization capability in both dry-lab and wet-lab experiments. As the first attempt in the chemical AI agent, this work goes a step further in the field of "AI for chemistry" and opens up new possibilities for computer-aided synthesis planning.
Heterogeneous Entity Matching with Complex Attribute Associations using BERT and Neural Networks
Sep 20, 2023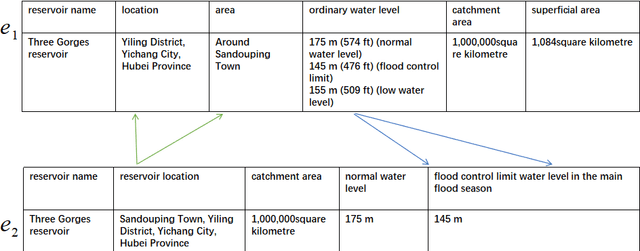
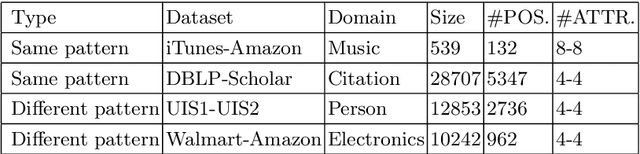
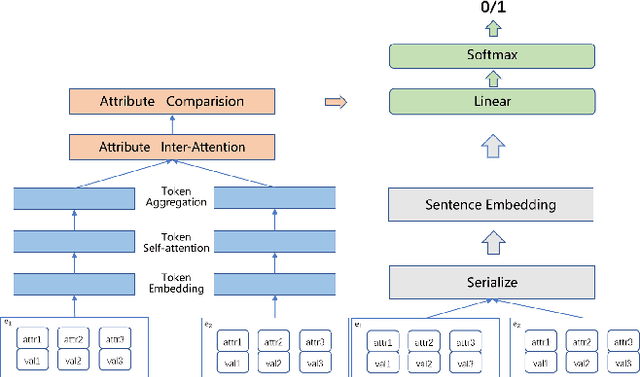
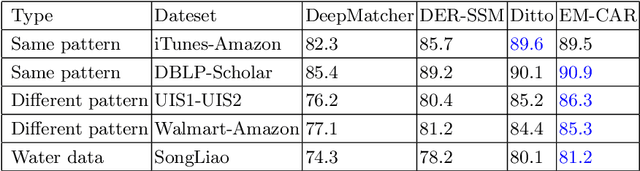
Across various domains, data from different sources such as Baidu Baike and Wikipedia often manifest in distinct forms. Current entity matching methodologies predominantly focus on homogeneous data, characterized by attributes that share the same structure and concise attribute values. However, this orientation poses challenges in handling data with diverse formats. Moreover, prevailing approaches aggregate the similarity of attribute values between corresponding attributes to ascertain entity similarity. Yet, they often overlook the intricate interrelationships between attributes, where one attribute may have multiple associations. The simplistic approach of pairwise attribute comparison fails to harness the wealth of information encapsulated within entities.To address these challenges, we introduce a novel entity matching model, dubbed Entity Matching Model for Capturing Complex Attribute Relationships(EMM-CCAR),built upon pre-trained models. Specifically, this model transforms the matching task into a sequence matching problem to mitigate the impact of varying data formats. Moreover, by introducing attention mechanisms, it identifies complex relationships between attributes, emphasizing the degree of matching among multiple attributes rather than one-to-one correspondences. Through the integration of the EMM-CCAR model, we adeptly surmount the challenges posed by data heterogeneity and intricate attribute interdependencies. In comparison with the prevalent DER-SSM and Ditto approaches, our model achieves improvements of approximately 4% and 1% in F1 scores, respectively. This furnishes a robust solution for addressing the intricacies of attribute complexity in entity matching.
Dealing with negative samples with multi-task learning on span-based joint entity-relation extraction
Sep 18, 2023
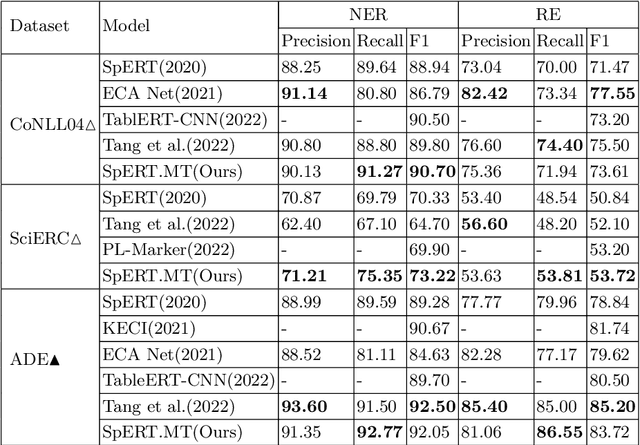
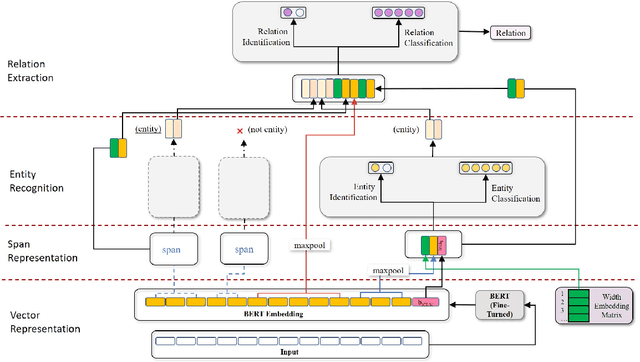
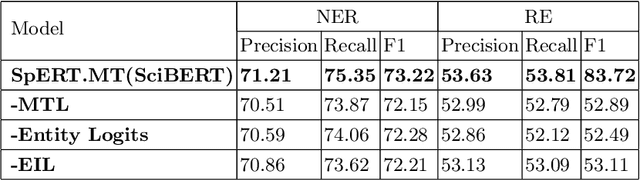
Recent span-based joint extraction models have demonstrated significant advantages in both entity recognition and relation extraction. These models treat text spans as candidate entities, and span pairs as candidate relationship tuples, achieving state-of-the-art results on datasets like ADE. However, these models encounter a significant number of non-entity spans or irrelevant span pairs during the tasks, impairing model performance significantly. To address this issue, this paper introduces a span-based multitask entity-relation joint extraction model. This approach employs the multitask learning to alleviate the impact of negative samples on entity and relation classifiers. Additionally, we leverage the Intersection over Union(IoU) concept to introduce the positional information into the entity classifier, achieving a span boundary detection. Furthermore, by incorporating the entity Logits predicted by the entity classifier into the embedded representation of entity pairs, the semantic input for the relation classifier is enriched. Experimental results demonstrate that our proposed SpERT.MT model can effectively mitigate the adverse effects of excessive negative samples on the model performance. Furthermore, the model demonstrated commendable F1 scores of 73.61\%, 53.72\%, and 83.72\% on three widely employed public datasets, namely CoNLL04, SciERC, and ADE, respectively.