 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware End-to-End Co-Design of Neural Network Processors: From Training and Mapping to Fabrication
Jun 03, 2026Designing a neural network processor is an end-to-end co-design problem: network architecture and training budget determine the inference workload; hardware mapping decisions determine chip area, latency, and energy; and these characteristics govern fabrication yield and manufacturing cost. In practice, these decisions are made in separate stages, and existing co-design methodologies are tightly coupled to specific algorithms, making it difficult to improve one component without reworking the entire pipeline. This paper presents a unified framework, grounded in monotone co-design theory, that composes four interoperable design blocks spanning network training, chip mapping, wafer-level fabrication, and compute resource allocation. Each block exposes only a functionality-resource interface to the rest of the system, so any block can be refined without structural changes elsewhere. A central contribution is the treatment of uncertainty: rather than collapsing stochastic outcomes into point estimates, the framework introduces Confidence, the inverse of success probability, as an explicit and optimizable resource alongside cost, time, and power. Three case studies validate the approach. The first recovers Pareto-optimal implementations across heterogeneous application scenarios. The second confirms that Confidence functions as a continuously tunable design knob rather than a post-hoc diagnostic. The third demonstrates that improving a single block's implementation set automatically propagates to the global Pareto front, without modifying the co-design diagram.
CL-SEC: Cross-Layer Semantic Error Correction Empowered by Language Models
Mar 27, 2026Achieving reliable communication has long been a fundamental challenge in networked systems. Semantic Error Correction (SEC) leverages the semantic understanding capabilities of language models (LMs) to perform application-layer error correction, complementing conventional channel decoding. While promising, existing SEC approaches rely solely on context captured by LMs at the application layer, ignoring the rich information available at the physical layer. To address this limitation, this paper introduces Cross-Layer SEC (CL-SEC), an LM-empowered error correction framework that integrates cross-layer information from both the physical and application layers to jointly correct corrupted words in text communication. Using a Bayesian combination in product form tailored to this framework, CL-SEC achieves significantly improved performance over methods that process information in isolated layers. CL-SEC shows substantial gains across multiple error-correction metrics, including bit-error rate, word-error rate, and semantic fidelity scores. Importantly, unlike most semantic communication systems that focus solely on recovering the semantic meaning of transmitted messages, CL-SEC aims to reconstruct the original transmitted message verbatim, leveraging the semantic understanding capabilities of LMs for precise reconstruction.
SA-OOSC: A Multimodal LLM-Distilled Semantic Communication Framework for Enhanced Coding Efficiency with Scenario Understanding
Sep 09, 2025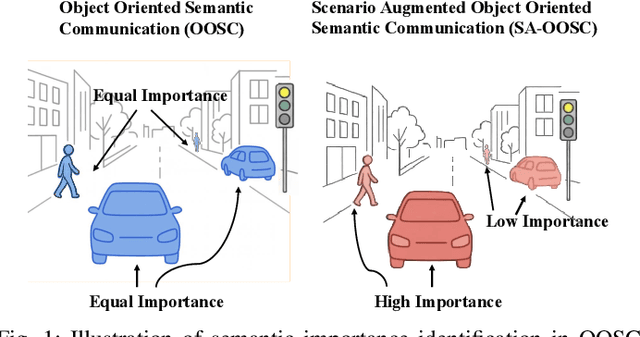

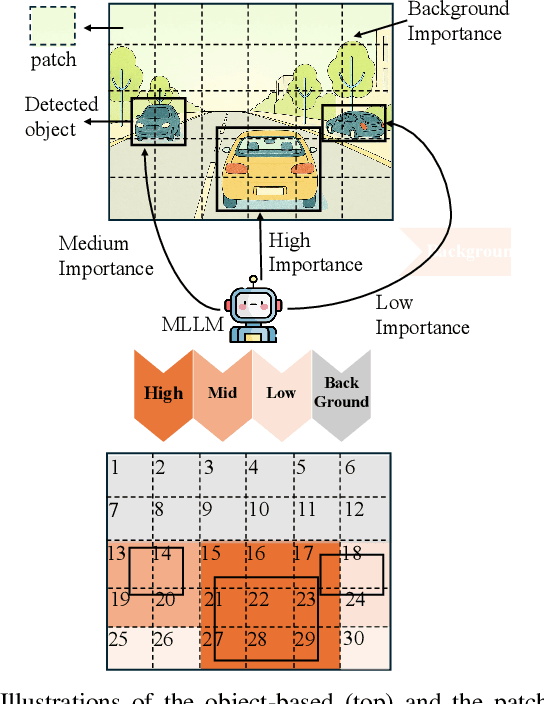
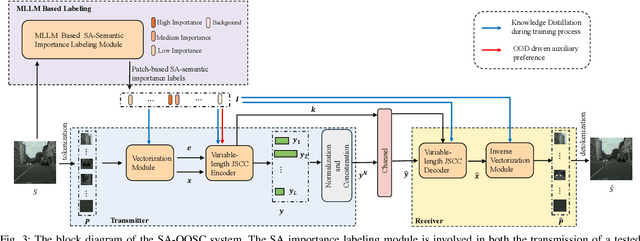
This paper introduces SA-OOSC, a multimodal large language models (MLLM)-distilled semantic communication framework that achieves efficient semantic coding with scenario-aware importance allocations. This approach addresses a critical limitation of existing object-oriented semantic communication (OOSC) systems - assigning static importance values to specific classes of objects regardless of their contextual relevance. Our framework utilizes MLLMs to identify the scenario-augmented (SA) semantic importance for objects within the image. Through knowledge distillation with the MLLM-annotated data, our vectorization/de-vectorization networks and JSCC encoder/decoder learn to dynamically allocate coding resources based on contextual significance, i.e., distinguishing between high-importance objects and low-importance according to the SA scenario information of the task. The framework features three core innovations: a MLLM-guided knowledge distillation pipeline, an importance-weighted variable-length JSCC framework, and novel loss function designs that facilitate the knowledge distillation within the JSCC framework. Experimental validation demonstrates our framework's superior coding efficiency over conventional semantic communication systems, with open-sourced MLLM-annotated and human-verified datasets established as new benchmarks for future research in semantic communications.
Addressing Out-of-Distribution Challenges in Image Semantic Communication Systems with Multi-modal Large Language Models
Jul 22, 2024



Semantic communication is a promising technology for next-generation wireless networks. However, the out-of-distribution (OOD) problem, where a pre-trained machine learning (ML) model is applied to unseen tasks that are outside the distribution of its training data, may compromise the integrity of semantic compression. This paper explores the use of multi-modal large language models (MLLMs) to address the OOD issue in image semantic communication. We propose a novel "Plan A - Plan B" framework that leverages the broad knowledge and strong generalization ability of an MLLM to assist a conventional ML model when the latter encounters an OOD input in the semantic encoding process. Furthermore, we propose a Bayesian optimization scheme that reshapes the probability distribution of the MLLM's inference process based on the contextual information of the image. The optimization scheme significantly enhances the MLLM's performance in semantic compression by 1) filtering out irrelevant vocabulary in the original MLLM output; and 2) using contextual similarities between prospective answers of the MLLM and the background information as prior knowledge to modify the MLLM's probability distribution during inference. Further, at the receiver side of the communication system, we put forth a "generate-criticize" framework that utilizes the cooperation of multiple MLLMs to enhance the reliability of image reconstruction.
LLM-Assisted Multi-Teacher Continual Learning for Visual Question Answering in Robotic Surgery
Feb 26, 2024



Visual question answering (VQA) can be fundamentally crucial for promoting robotic-assisted surgical education. In practice, the needs of trainees are constantly evolving, such as learning more surgical types, adapting to different robots, and learning new surgical instruments and techniques for one surgery. Therefore, continually updating the VQA system by a sequential data stream from multiple resources is demanded in robotic surgery to address new tasks. In surgical scenarios, the storage cost and patient data privacy often restrict the availability of old data when updating the model, necessitating an exemplar-free continual learning (CL) setup. However, prior studies overlooked two vital problems of the surgical domain: i) large domain shifts from diverse surgical operations collected from multiple departments or clinical centers, and ii) severe data imbalance arising from the uneven presence of surgical instruments or activities during surgical procedures. This paper proposes to address these two problems with a multimodal large language model (LLM) and an adaptive weight assignment methodology. We first develop a new multi-teacher CL framework that leverages a multimodal LLM as the additional teacher. The strong generalization ability of the LLM can bridge the knowledge gap when domain shifts and data imbalances occur. We then put forth a novel data processing method that transforms complex LLM embeddings into logits compatible with our CL framework. We further design an adaptive weight assignment approach that balances the generalization ability of the LLM and the domain expertise of the old CL model. We construct a new dataset for surgical VQA tasks, providing valuable data resources for future research. Extensive experimental results on three datasets demonstrate the superiority of our method to other advanced CL models.
An Autonomous Large Language Model Agent for Chemical Literature Data Mining
Feb 20, 2024



Chemical synthesis, which is crucial for advancing material synthesis and drug discovery, impacts various sectors including environmental science and healthcare. The rise of technology in chemistry has generated extensive chemical data, challenging researchers to discern patterns and refine synthesis processes. Artificial intelligence (AI) helps by analyzing data to optimize synthesis and increase yields. However, AI faces challenges in processing literature data due to the unstructured format and diverse writing style of chemical literature. To overcome these difficulties, we introduce an end-to-end AI agent framework capable of high-fidelity extraction from extensive chemical literature. This AI agent employs large language models (LLMs) for prompt generation and iterative optimization. It functions as a chemistry assistant, automating data collection and analysis, thereby saving manpower and enhancing performance. Our framework's efficacy is evaluated using accuracy, recall, and F1 score of reaction condition data, and we compared our method with human experts in terms of content correctness and time efficiency. The proposed approach marks a significant advancement in automating chemical literature extraction and demonstrates the potential for AI to revolutionize data management and utilization in chemistry.
LLMind: Orchestrating AI and IoT with LLMs for Complex Task Execution
Dec 14, 2023
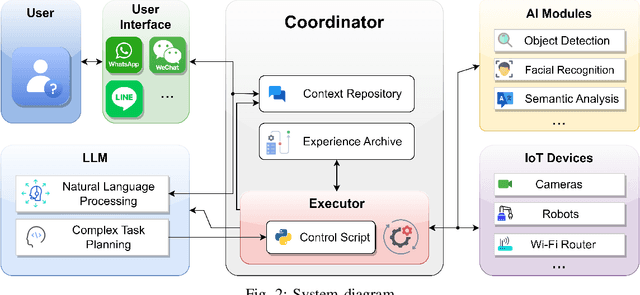
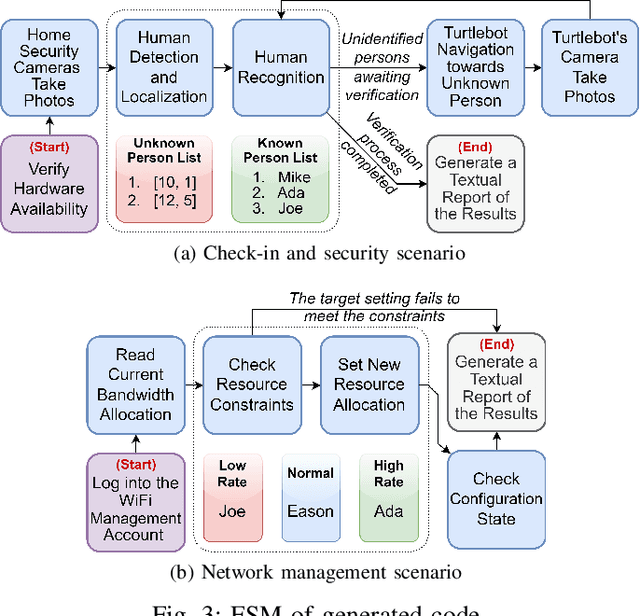
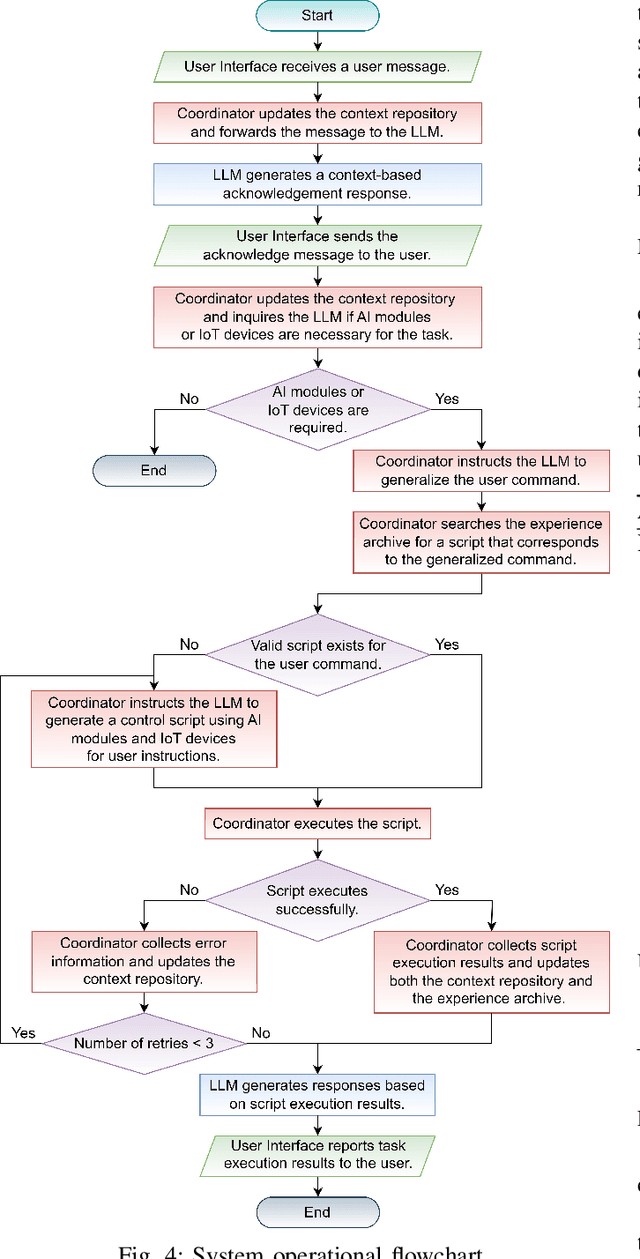
In this article, we introduce LLMind, an innovative AI framework that utilizes large language models (LLMs) as a central orchestrator. The framework integrates LLMs with domain-specific AI modules, enabling IoT devices to collaborate effectively in executing complex tasks. The LLM performs planning and generates control scripts using a reliable and precise language-code transformation approach based on finite state machines (FSMs). The LLM engages in natural conversations with users, employing role-playing techniques to generate contextually appropriate responses. Additionally, users can interact easily with the AI agent via a user-friendly social media platform. The framework also incorporates semantic analysis and response optimization techniques to enhance speed and effectiveness. Ultimately, this framework is designed not only to innovate IoT device control and enrich user experiences but also to foster an intelligent and integrated IoT device ecosystem that evolves and becomes more sophisticated through continuing user and machine interactions.
Towards an Automatic AI Agent for Reaction Condition Recommendation in Chemical Synthesis
Nov 28, 2023



Artificial intelligence (AI) for reaction condition optimization has become an important topic in the pharmaceutical industry, given that a data-driven AI model can assist drug discovery and accelerate reaction design. However, existing AI models lack the chemical insights and real-time knowledge acquisition abilities of experienced human chemists. This paper proposes a Large Language Model (LLM) empowered AI agent to bridge this gap. We put forth a novel three-phase paradigm and applied advanced intelligence-enhancement methods like in-context learning and multi-LLM debate so that the AI agent can borrow human insight and update its knowledge by searching the latest chemical literature. Additionally, we introduce a novel Coarse-label Contrastive Learning (CCL) based chemical fingerprint that greatly enhances the agent's performance in optimizing the reaction condition. With the above efforts, the proposed AI agent can autonomously generate the optimal reaction condition recommendation without any human interaction. Further, the agent is highly professional in terms of chemical reactions. It demonstrates close-to-human performance and strong generalization capability in both dry-lab and wet-lab experiments. As the first attempt in the chemical AI agent, this work goes a step further in the field of "AI for chemistry" and opens up new possibilities for computer-aided synthesis planning.
Nonlinear Multi-Carrier System with Signal Clipping: Measurement, Analysis, and Optimization
Oct 01, 2023



Signal clipping is a classic technique for reducing peak-to-average power ratio (PAPR) in orthogonal frequency division multiplexing (OFDM) systems. It has been widely applied in consumer electronic devices owing to its low complexity and high efficiency. Although clipping reduces the nonlinear distortion caused by power amplifiers (PAs), it induces additional clipping distortion. Optimizing the joint system performance with consideration of both PA nonlinearity and clipping distortion remains an open problem due to the complex PA modeling. In this paper, we analyze the PA nonlinearity through the Bessel-Fourier PA (BFPA) model and simplify its power expression using inter-modulation product (IMP) analysis. We derive expressions of the receiver signal-to-noise ratio (SNR) and system symbol error rate (SER) for the nonlinear clipped OFDM system. With the derivations, we investigate the optimal system setting to achieve the SER lower bound in a practical OFDM system that considers both PA nonlinearity and clipping distortion. The methods and results presented in this paper can serve as a useful reference for the system-level optimization of clipped OFDM systems with nonlinear PA.
The Power of Large Language Models for Wireless Communication System Development: A Case Study on FPGA Platforms
Jul 14, 2023



Large language models (LLMs) have garnered significant attention across various research disciplines, including the wireless communication community. There have been several heated discussions on the intersection of LLMs and wireless technologies. While recent studies have demonstrated the ability of LLMs to generate hardware description language (HDL) code for simple computation tasks, developing wireless prototypes and products via HDL poses far greater challenges because of the more complex computation tasks involved. In this paper, we aim to address this challenge by investigating the role of LLMs in FPGA-based hardware development for advanced wireless signal processing. We begin by exploring LLM-assisted code refactoring, reuse, and validation, using an open-source software-defined radio (SDR) project as a case study. Through the case study, we find that an LLM assistant can potentially yield substantial productivity gains for researchers and developers. We then examine the feasibility of using LLMs to generate HDL code for advanced wireless signal processing, using the Fast Fourier Transform (FFT) algorithm as an example. This task presents two unique challenges: the scheduling of subtasks within the overall task and the multi-step thinking required to solve certain arithmetic problem within the task. To address these challenges, we employ in-context learning (ICL) and Chain-of-Thought (CoT) prompting techniques, culminating in the successful generation of a 64-point Verilog FFT module. Our results demonstrate the potential of LLMs for generalization and imitation, affirming their usefulness in writing HDL code for wireless communication systems. Overall, this work contributes to understanding the role of LLMs in wireless communication and motivates further exploration of their capabilities.