 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid System of Sound Event Detection Transformer and Frame-wise Model for DCASE 2022 Task 4
Oct 18, 2022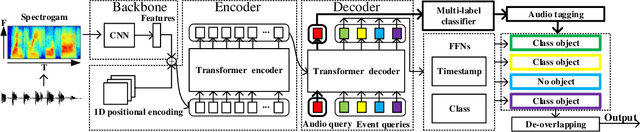
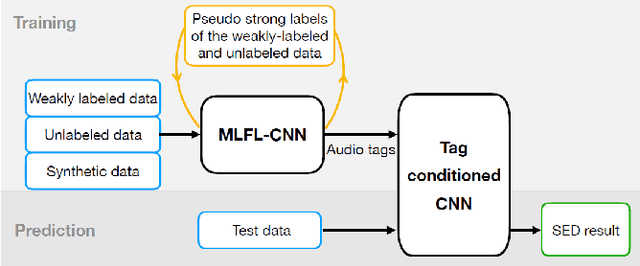
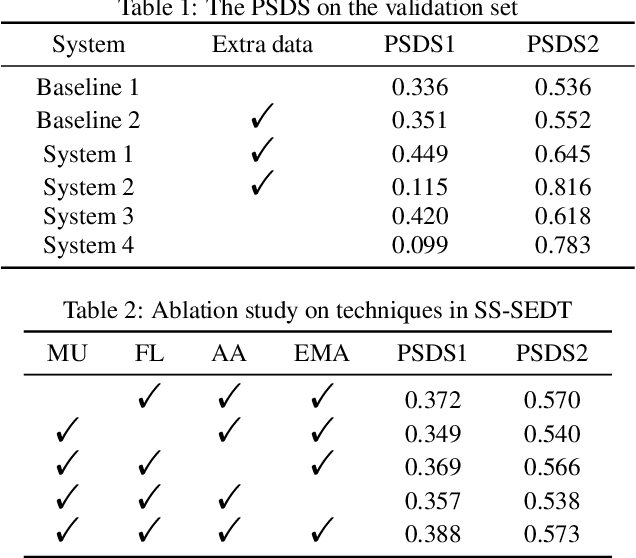

In this paper, we describe in detail our system for DCASE 2022 Task4. The system combines two considerably different models: an end-to-end Sound Event Detection Transformer (SEDT) and a frame-wise model, Metric Learning and Focal Loss CNN (MLFL-CNN). The former is an event-wise model which learns event-level representations and predicts sound event categories and boundaries directly, while the latter is based on the widely adopted frame-classification scheme, under which each frame is classified into event categories and event boundaries are obtained by post-processing such as thresholding and smoothing. For SEDT, self-supervised pre-training using unlabeled data is applied, and semi-supervised learning is adopted by using an online teacher, which is updated from the student model using the Exponential Moving Average (EMA) strategy and generates reliable pseudo labels for weakly-labeled and unlabeled data. For the frame-wise model, the ICT-TOSHIBA system of DCASE 2021 Task 4 is used. Experimental results show that the hybrid system considerably outperforms either individual model and achieves psds1 of 0.420 and psds2 of 0.783 on the validation set without external data. The code is available at https://github.com/965694547/Hybrid-system-of-frame-wise-model-and-SEDT.
AMD-DBSCAN: An Adaptive Multi-density DBSCAN for datasets of extremely variable density
Oct 15, 2022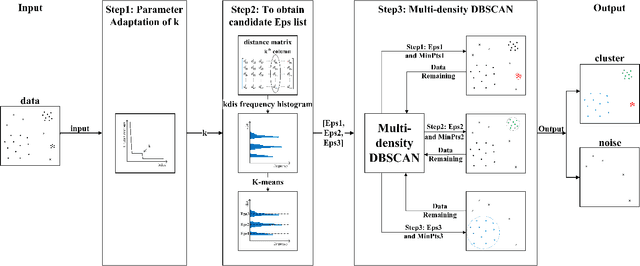
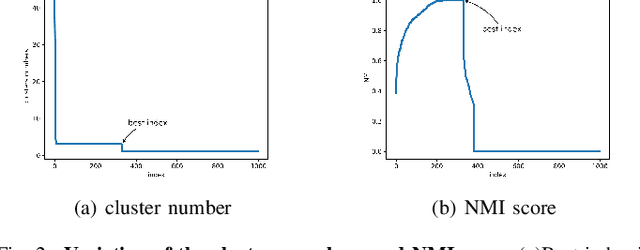
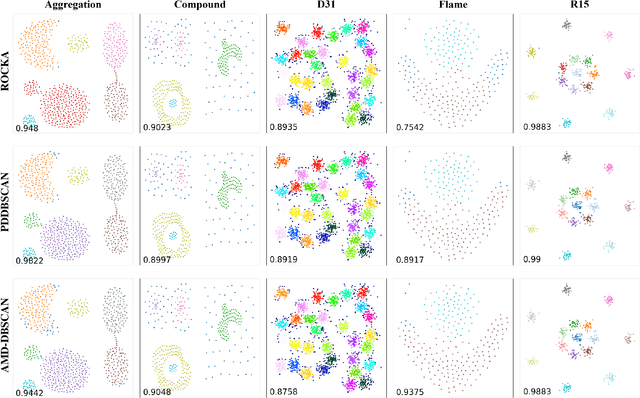
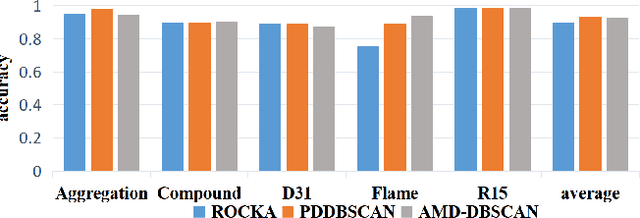
DBSCAN has been widely used in density-based clustering algorithms. However, with the increasing demand for Multi-density clustering, previous traditional DSBCAN can not have good clustering results on Multi-density datasets. In order to address this problem, an adaptive Multi-density DBSCAN algorithm (AMD-DBSCAN) is proposed in this paper. An improved parameter adaptation method is proposed in AMD-DBSCAN to search for multiple parameter pairs (i.e., Eps and MinPts), which are the key parameters to determine the clustering results and performance, therefore allowing the model to be applied to Multi-density datasets. Moreover, only one hyperparameter is required for AMD-DBSCAN to avoid the complicated repetitive initialization operations. Furthermore, the variance of the number of neighbors (VNN) is proposed to measure the difference in density between each cluster. The experimental results show that our AMD-DBSCAN reduces execution time by an average of 75% due to lower algorithm complexity compared with the traditional adaptive algorithm. In addition, AMD-DBSCAN improves accuracy by 24.7% on average over the state-of-the-art design on Multi-density datasets of extremely variable density, while having no performance loss in Single-density scenarios.
SP-SEDT: Self-supervised Pre-training for Sound Event Detection Transformer
Nov 30, 2021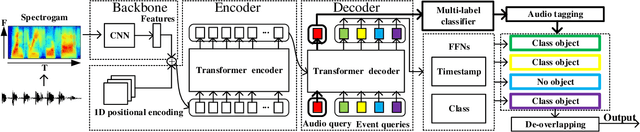
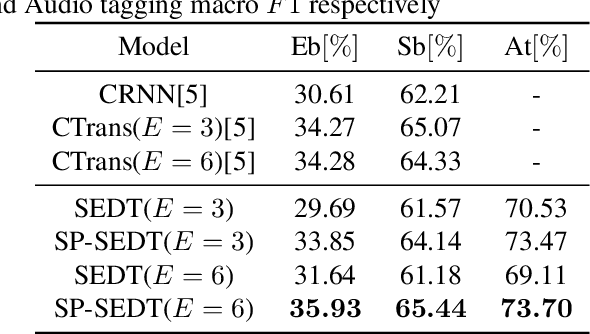
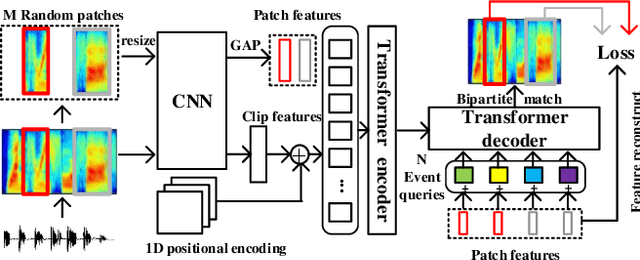
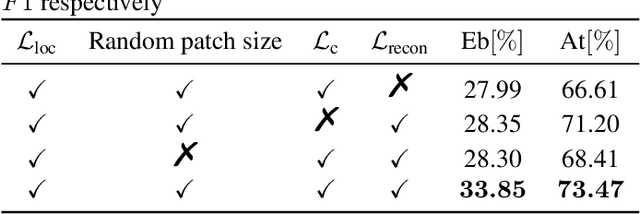
Recently, an event-based end-to-end model (SEDT) has been proposed for sound event detection (SED) and achieves competitive performance. However, compared with the frame-based model, it requires more training data with temporal annotations to improve the localization ability. Synthetic data is an alternative, but it suffers from a great domain gap with real recordings. Inspired by the great success of UP-DETR in object detection, we propose to self-supervisedly pre-train SEDT (SP-SEDT) by detecting random patches (only cropped along the time axis). Experiments on the DCASE2019 task4 dataset show the proposed SP-SEDT can outperform fine-tuned frame-based model. The ablation study is also conducted to investigate the impact of different loss functions and patch size.
Sound Event Detection Transformer: An Event-based End-to-End Model for Sound Event Detection
Oct 18, 2021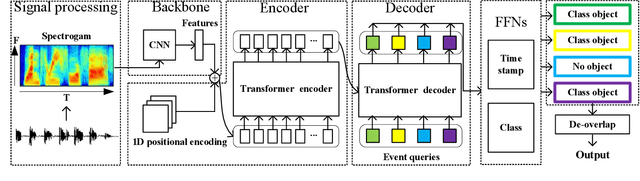

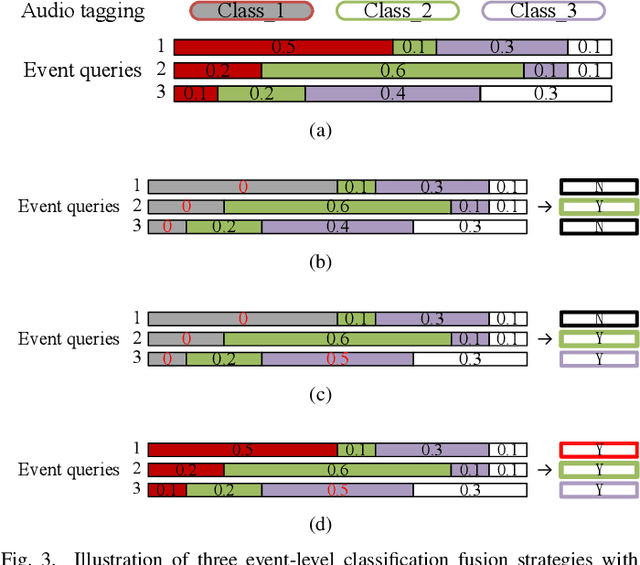

Sound event detection (SED) has gained increasing attention with its wide application in surveillance, video indexing, etc. Existing models in SED mainly generate frame-level predictions, converting it into a sequence multi-label classification problem, which inevitably brings a trade-off between event boundary detection and audio tagging when using weakly labeled data to train the model. Besides, it needs post-processing and cannot be trained in an end-to-end way. This paper firstly presents the 1D Detection Transformer (1D-DETR), inspired by Detection Transformer. Furthermore, given the characteristics of SED, the audio query and a one-to-many matching strategy for fine-tuning the model are added to 1D-DETR to form the model of Sound Event Detection Transformer (SEDT), which generates event-level predictions, end-to-end detection. Experiments are conducted on the URBAN-SED dataset and the DCASE2019 Task4 dataset, and both experiments have achieved competitive results compared with SOTA models. The application of SEDT on SED shows that it can be used as a framework for one-dimensional signal detection and may be extended to other similar tasks.