 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Free Generalized Zero-Shot Learning
Jan 28, 2024



Deep learning models have the ability to extract rich knowledge from large-scale datasets. However, the sharing of data has become increasingly challenging due to concerns regarding data copyright and privacy. Consequently, this hampers the effective transfer of knowledge from existing data to novel downstream tasks and concepts. Zero-shot learning (ZSL) approaches aim to recognize new classes by transferring semantic knowledge learned from base classes. However, traditional generative ZSL methods often require access to real images from base classes and rely on manually annotated attributes, which presents challenges in terms of data restrictions and model scalability. To this end, this paper tackles a challenging and practical problem dubbed as data-free zero-shot learning (DFZSL), where only the CLIP-based base classes data pre-trained classifier is available for zero-shot classification. Specifically, we propose a generic framework for DFZSL, which consists of three main components. Firstly, to recover the virtual features of the base data, we model the CLIP features of base class images as samples from a von Mises-Fisher (vMF) distribution based on the pre-trained classifier. Secondly, we leverage the text features of CLIP as low-cost semantic information and propose a feature-language prompt tuning (FLPT) method to further align the virtual image features and textual features. Thirdly, we train a conditional generative model using the well-aligned virtual image features and corresponding semantic text features, enabling the generation of new classes features and achieve better zero-shot generalization. Our framework has been evaluated on five commonly used benchmarks for generalized ZSL, as well as 11 benchmarks for the base-to-new ZSL. The results demonstrate the superiority and effectiveness of our approach. Our code is available in https://github.com/ylong4/DFZSL
Frame Pairwise Distance Loss for Weakly-supervised Sound Event Detection
Sep 21, 2023



Weakly-supervised learning has emerged as a promising approach to leverage limited labeled data in various domains by bridging the gap between fully supervised methods and unsupervised techniques. Acquisition of strong annotations for detecting sound events is prohibitively expensive, making weakly supervised learning a more cost-effective and broadly applicable alternative. In order to enhance the recognition rate of the learning of detection of weakly-supervised sound events, we introduce a Frame Pairwise Distance (FPD) loss branch, complemented with a minimal amount of synthesized data. The corresponding sampling and label processing strategies are also proposed. Two distinct distance metrics are employed to evaluate the proposed approach. Finally, the method is validated on the standard DCASE dataset. The obtained experimental results corroborated the efficacy of this approach.
Semi-supervised Sound Event Detection with Local and Global Consistency Regularization
Sep 15, 2023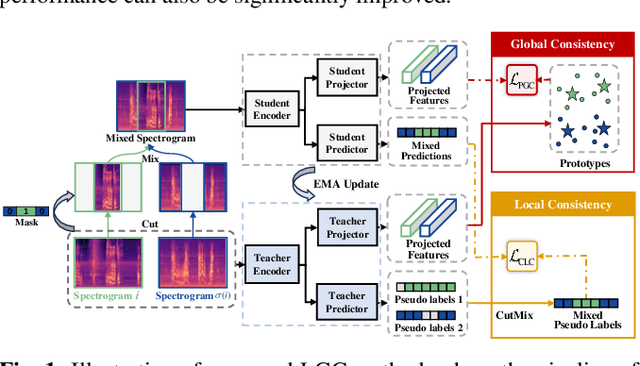
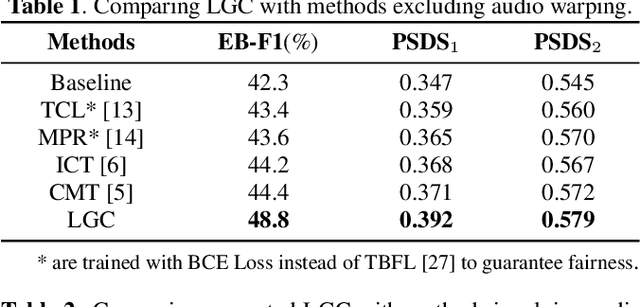
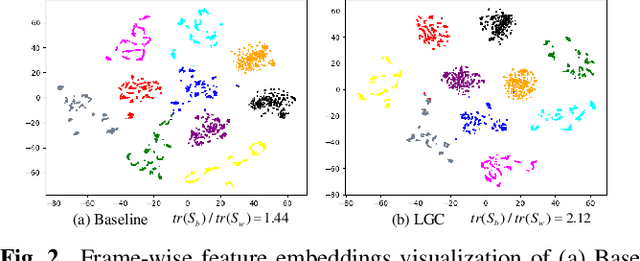
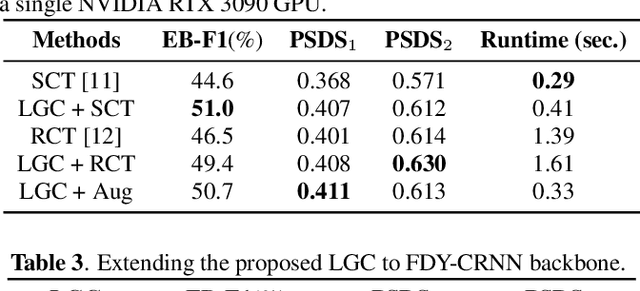
Learning meaningful frame-wise features on a partially labeled dataset is crucial to semi-supervised sound event detection. Prior works either maintain consistency on frame-level predictions or seek feature-level similarity among neighboring frames, which cannot exploit the potential of unlabeled data. In this work, we design a Local and Global Consistency (LGC) regularization scheme to enhance the model on both label- and feature-level. The audio CutMix is introduced to change the contextual information of clips. Then, the local consistency is adopted to encourage the model to leverage local features for frame-level predictions, and the global consistency is applied to force features to align with global prototypes through a specially designed contrastive loss. Experiments on the DESED dataset indicate the superiority of LGC, surpassing its respective competitors largely with the same settings as the baseline system. Besides, combining LGC with existing methods can obtain further improvements. The code will be released soon.
Audio Generation with Multiple Conditional Diffusion Model
Aug 23, 2023Text-based audio generation models have limitations as they cannot encompass all the information in audio, leading to restricted controllability when relying solely on text. To address this issue, we propose a novel model that enhances the controllability of existing pre-trained text-to-audio models by incorporating additional conditions including content (timestamp) and style (pitch contour and energy contour) as supplements to the text. This approach achieves fine-grained control over the temporal order, pitch, and energy of generated audio. To preserve the diversity of generation, we employ a trainable control condition encoder that is enhanced by a large language model and a trainable Fusion-Net to encode and fuse the additional conditions while keeping the weights of the pre-trained text-to-audio model frozen. Due to the lack of suitable datasets and evaluation metrics, we consolidate existing datasets into a new dataset comprising the audio and corresponding conditions and use a series of evaluation metrics to evaluate the controllability performance. Experimental results demonstrate that our model successfully achieves fine-grained control to accomplish controllable audio generation. Audio samples and our dataset are publicly available at https://conditionaudiogen.github.io/conditionaudiogen/
A Hybrid System of Sound Event Detection Transformer and Frame-wise Model for DCASE 2022 Task 4
Oct 18, 2022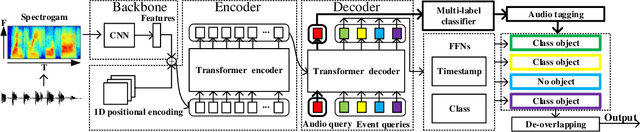
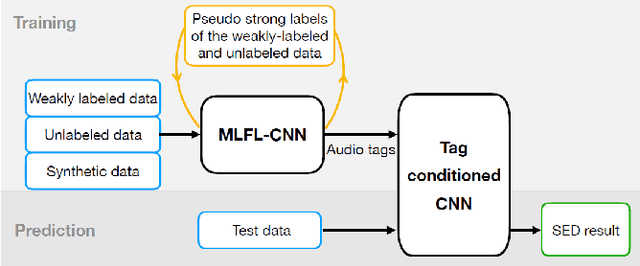
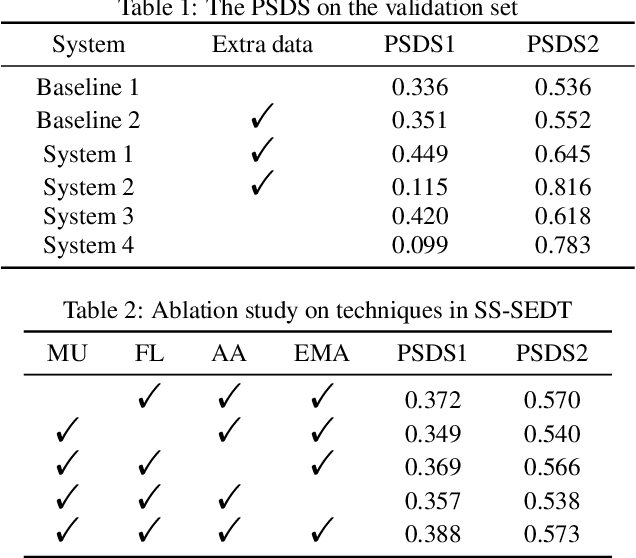

In this paper, we describe in detail our system for DCASE 2022 Task4. The system combines two considerably different models: an end-to-end Sound Event Detection Transformer (SEDT) and a frame-wise model, Metric Learning and Focal Loss CNN (MLFL-CNN). The former is an event-wise model which learns event-level representations and predicts sound event categories and boundaries directly, while the latter is based on the widely adopted frame-classification scheme, under which each frame is classified into event categories and event boundaries are obtained by post-processing such as thresholding and smoothing. For SEDT, self-supervised pre-training using unlabeled data is applied, and semi-supervised learning is adopted by using an online teacher, which is updated from the student model using the Exponential Moving Average (EMA) strategy and generates reliable pseudo labels for weakly-labeled and unlabeled data. For the frame-wise model, the ICT-TOSHIBA system of DCASE 2021 Task 4 is used. Experimental results show that the hybrid system considerably outperforms either individual model and achieves psds1 of 0.420 and psds2 of 0.783 on the validation set without external data. The code is available at https://github.com/965694547/Hybrid-system-of-frame-wise-model-and-SEDT.
SP-SEDT: Self-supervised Pre-training for Sound Event Detection Transformer
Nov 30, 2021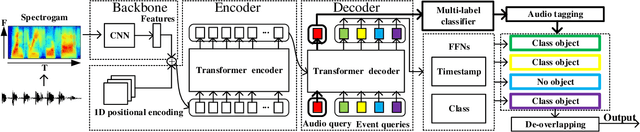
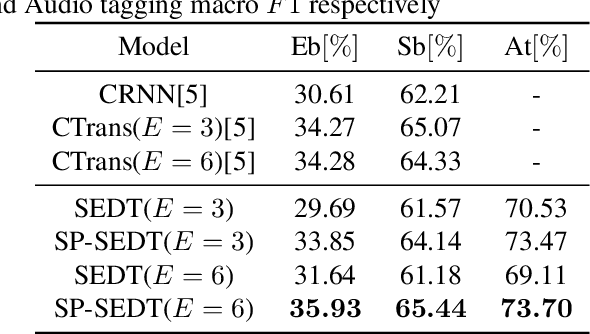
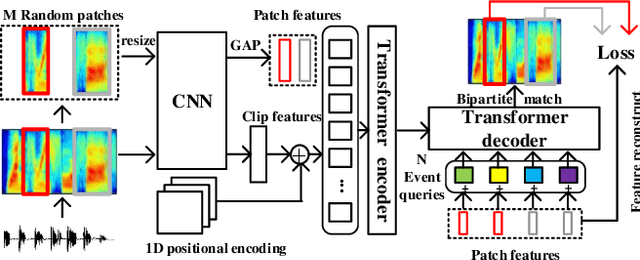
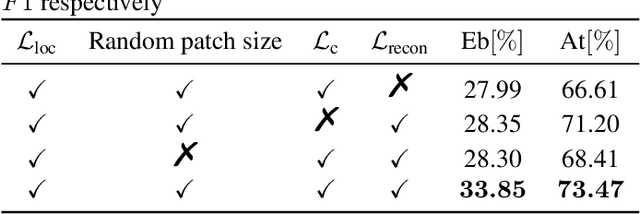
Recently, an event-based end-to-end model (SEDT) has been proposed for sound event detection (SED) and achieves competitive performance. However, compared with the frame-based model, it requires more training data with temporal annotations to improve the localization ability. Synthetic data is an alternative, but it suffers from a great domain gap with real recordings. Inspired by the great success of UP-DETR in object detection, we propose to self-supervisedly pre-train SEDT (SP-SEDT) by detecting random patches (only cropped along the time axis). Experiments on the DCASE2019 task4 dataset show the proposed SP-SEDT can outperform fine-tuned frame-based model. The ablation study is also conducted to investigate the impact of different loss functions and patch size.
Sound Event Detection Transformer: An Event-based End-to-End Model for Sound Event Detection
Oct 18, 2021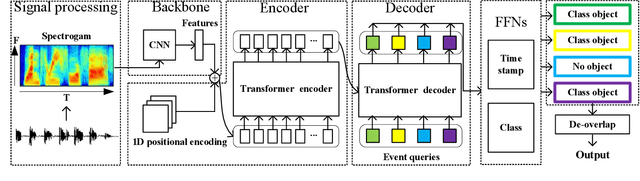

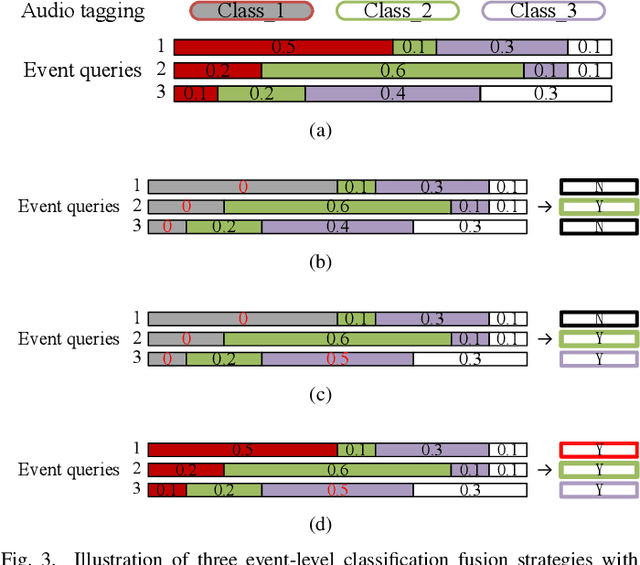

Sound event detection (SED) has gained increasing attention with its wide application in surveillance, video indexing, etc. Existing models in SED mainly generate frame-level predictions, converting it into a sequence multi-label classification problem, which inevitably brings a trade-off between event boundary detection and audio tagging when using weakly labeled data to train the model. Besides, it needs post-processing and cannot be trained in an end-to-end way. This paper firstly presents the 1D Detection Transformer (1D-DETR), inspired by Detection Transformer. Furthermore, given the characteristics of SED, the audio query and a one-to-many matching strategy for fine-tuning the model are added to 1D-DETR to form the model of Sound Event Detection Transformer (SEDT), which generates event-level predictions, end-to-end detection. Experiments are conducted on the URBAN-SED dataset and the DCASE2019 Task4 dataset, and both experiments have achieved competitive results compared with SOTA models. The application of SEDT on SED shows that it can be used as a framework for one-dimensional signal detection and may be extended to other similar tasks.
Couple Learning: Mean Teacher method with pseudo-labels improves semi-supervised deep learning results
Oct 12, 2021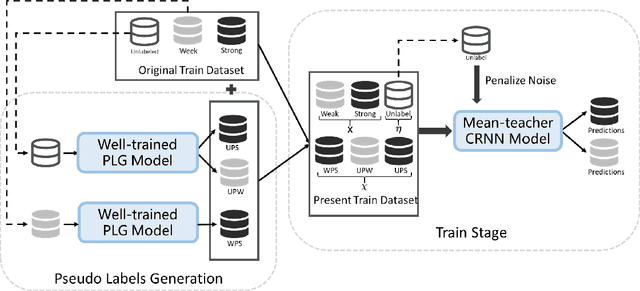


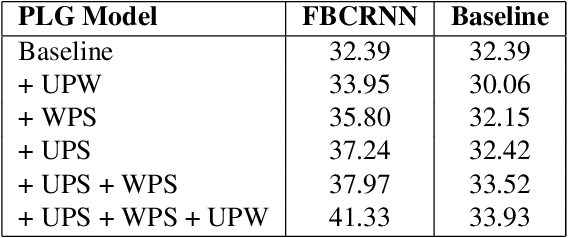
The recently proposed Mean Teacher has achieved state-of-the-art results in several semi-supervised learning benchmarks. The Mean Teacher method can exploit large-scale unlabeled data in a self-ensembling manner. In this paper, an effective Couple Learning method based on a well-trained model and a Mean Teacher model is proposed. The proposed pseudo-labels generated model (PLG) can increase strongly-labeled data and weakly-labeled data to improve performance of the Mean Teacher method. The Mean Teacher method can suppress noise in pseudo-labels data. The Couple Learning method can extract more information in the compound training data. These experimental results on Task 4 of the DCASE2020 challenge demonstrate the superiority of the proposed method, achieving about 39.18% F1-score on public eval set, outperforming 37.12% of the baseline system by a significant margin.